YOLOv1笔记
最新更新于: 2024年5月24日上午11点17分
背景介绍
YOLOv1是Joseph Redmon于2015年提出的目标检测检测算法,YOLO系列(2023/09/20已经出到第8个版本)的特点在于其极高的识别速度,经典目标识别网络还有R-CNN和SSD,这些算法具有较高的准确率但是速度比YOLO慢至少一倍。
值得注意的是,作者Joseph Redmon在发布YOLOv3之后就退出CV界了,原因在于YOLO算法被用于商业中隐私窃取和军事武器当中(YOLOv3的论文也阐述),在YOLOv3以后,都是对模型细节上的微调,利用了很多最新的tricks,但对于网络主体思路基本没变。(而且YOLO系列论文虽然篇幅简略,但技巧都是以文字形式描述,需要仔细阅读论文)
当前YOLOv4(2020)是最后一个学术论文,而YOLOv5及其以后的算法均为商业研发用途(那为啥不写专利),可以学习其思路。
YOLOv1
YOLOv1的算法思路非常有趣,他不同于R-CNN的滑动窗口,而是直接端到端输出检测框。具体实现方法如下:
定义1(边界框bounding box)
设介于 中的正实数 ,称五元组 为边界框。其中 表示置信度, 分别表示边界框中心的相对坐标(相对整个图像左上角或者相对中心点所处网格的左上角等等), 分别表示边界框的宽和高(相对整个图像的比例)
定义2(交并比IOU)
对于两个边界框 ,分别用 表示其围住的点集合,则称 的交并比为 。
BoxType = jax.Array
def iou(box1: BoxType, box2: BoxType, scale: list | jax.Array = None, keepdim: bool = False, EPS: float = 1e-6):
"""
(JAX)Calculate the intersection over union for box1 and box2.
@params::box1, box2 shapes are (N,4), where the last dim x,y,w,h under the **same scale**:
(x, y): the center of the box.
(w, h): the width and the height of the box.
@return::IOU of box1 and box2, `shape=(N,)` when `keepdim=False`
"""
assert(box1.shape[-1] == box2.shape[-1])
assert(box1.shape[-1] == 4)
if box1.ndim == 1: box1 = box1.reshape(1,-1)
if box2.ndim == 1: box2 = box2.reshape(1,-1)
if scale is not None:
if type(scale) == list: scale = jnp.array(scale)
box1 *= scale; box2 *= scale
min1, min2 = box1[...,0:2]-jnp.abs(box1[...,2:4])/2, box2[...,0:2]-jnp.abs(box2[...,2:4])/2
max1, max2 = box1[...,0:2]+jnp.abs(box1[...,2:4])/2, box2[...,0:2]+jnp.abs(box2[...,2:4])/2
inter_w = (jnp.minimum(max1[...,0],max2[...,0]) - jnp.maximum(min1[...,0],min2[...,0])).clip(0.0)
inter_h = jnp.minimum(max1[...,1],max2[...,1]) - jnp.maximum(min1[...,1],min2[...,1]).clip(0.0)
inter_size = inter_w * inter_h
size1, size2 = jnp.prod(max1-min1, axis=-1), jnp.prod(max2-min2, axis=-1)
union_size = size1 + size2 - inter_size
ret = inter_size / (union_size + EPS)
if keepdim: ret = ret[...,jnp.newaxis]
return ret算法1(YOLOv1)
思路
根据输入的图像(分辨率 448x448)预测该图像中的全部物体的边界框,并对每个边界框输出对应的置信度分数和所属的类别。
设 为三个正整数,分别表示图像网格化的大小、每个网格中边界框个数、总分类类别数。取 (PASCAL VOC数据集中类别数目为20个),每个网格中模型需要预测出 个检测框,取其中置信度较高的作为预测结果,每个网格仅预测一个物体。(若数据中多个边界框的中心位于同一网格中,那么任取其中一个,YOLOv1的缺点)
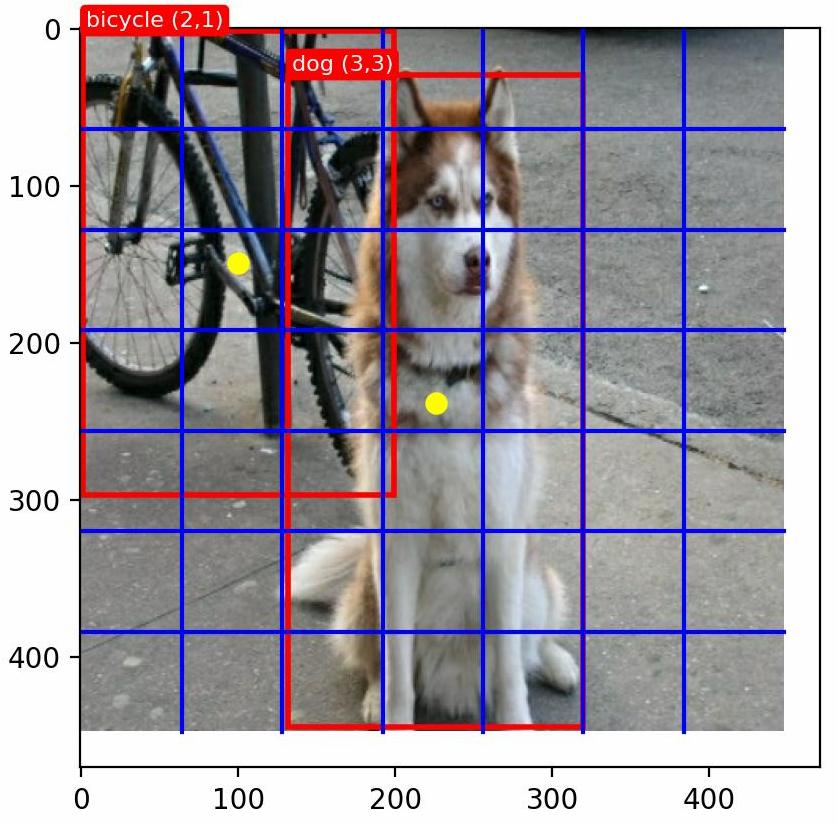
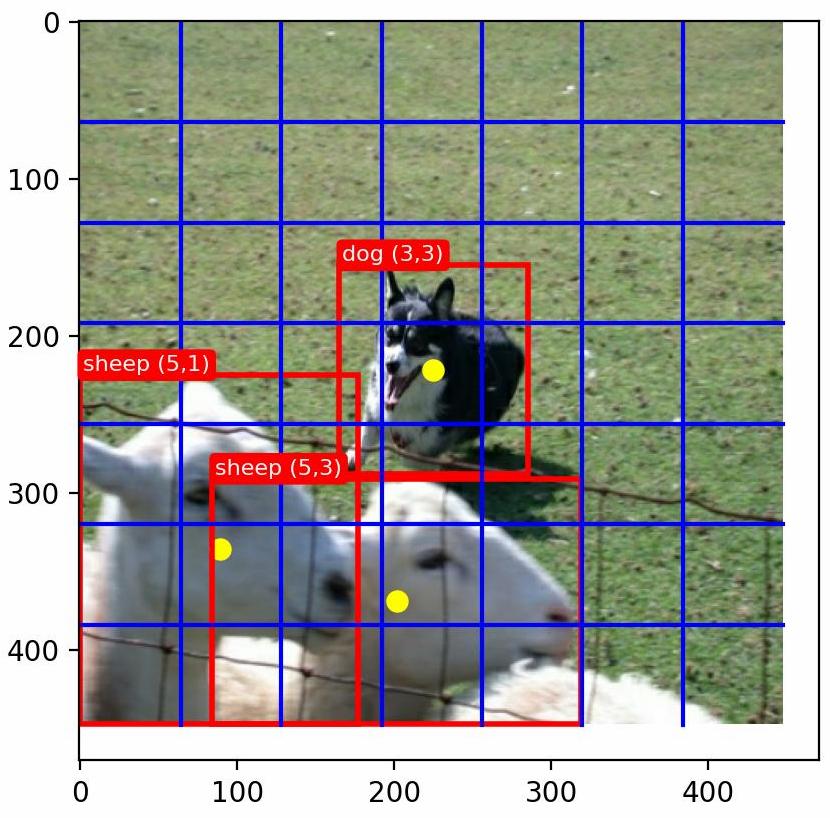
上图以两个训练样本标签为例,首先将图片缩放为 大小,然后将图像平均划分为 个网格,对于每个边界框 ,其中心点用黄色标出,假设当前边界框的中心位于 个网格内,那么在模型预测中,也应该由 网格处的边界框对其进行预测。
数据集预处理
设总共有 个图片数据,对于第 个图片其中有 个边界框需要检测,第 个边界框属于类别 ,总共有 个类别。那么当前图片对应的标签数据集大小为 ,其中前两个维度分别表示对网格的 划分,若网格 中存在边界框的 且类别为 ,则标签数据集应该为
其中 为 对应的onehot向量; 是 相对当前网格 的比例缩放(原点位于网格左上角,缩放后 )。
模型结构
模型分为两部分:Darknet-24(特征提取)和部分卷积+全链接(目标检测),其中前半部分的 Darknet-20 采用了20个卷积层,参考了GoogleNet和VGG的思路,利用了(1,1)和(3,3)卷积核交替作用,并使用Leaky损失函数 ,网络结构如下图所示:
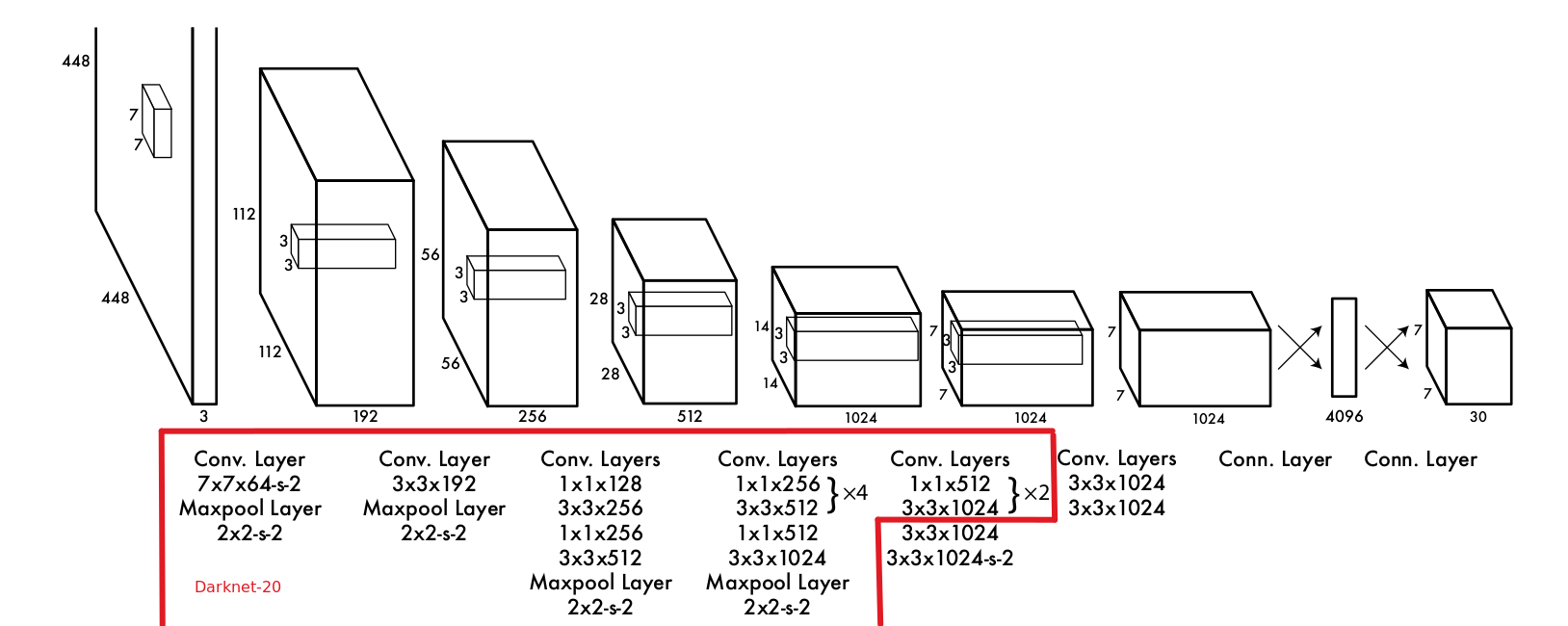
Darknet-20先在Imagenet上进行预训练达到88%的top5准确率,我自己训练达到了89.4%的top5准确率,然后再加上最后4个卷积层和2个全连接层进行目标识别。在预训模型后再加上部分卷积层有论文(Object
detection networks on convolutional feature maps)说明可以提高目标检测准确率。
在Imagenet预训练数据集上的分辨率使用的是 ,但是目标检测需要更高的分辨率,所以在检测任务训练中,将输入图片的分辨率调整为 。
模型输出
由于输出中每个网格要输出 个边界框,每个边界框又由 参数决定,所以网络的最终输出维度应该为 ,我们可以通过最后一个全链接层达到这个维度大小。
损失函数设计:对于每个网格输出的 个边界框,我们通过计算每个边界框和当前目标边界框的IOU大小,并选取其中IOU大小最大的一个作为代表(responsible),对于第 个网格中的第 个预测出的边界框,我们记
对于很多没有边界框的网格,我们记
于是我们可以给出YOLOv1的损失函数:
其中 分别表示坐标权重和无对象的损失权重系数。
上面的损失函数是我自己实现时候用的,对原损失进行了一点改动,当网格中无目标时,原论文写的是 意义不明,所以我改成对所有的检测框的置信度进行降低。
预测结果
对于得到的预测结果 ,我们对每个网格取置信度较高的边界框作为当前网格预测的边界框,该边界框的分类类别由前 个维度最大概率值确定,于是我们可以得到 个边界框,然后再利用NMS(Non-Maximum Suppression,非最大值抑制)对其进行筛选,最终得到的检测框就是模型的预测结果。
实现效果
这里我用的是别人已经整理好的PASCAL VOC 2007/2012数据集,其中 .csv 文件将数据集划分为训练集和测试集,首先我们将数据集转化为创建TFRecord
python katacv/utils/VOC/translate_tfrecord.py --path /home/wty/Coding/datasets/VOC/ --subset train
python katacv/utils/VOC/translate_tfrecord.py --path /home/wty/Coding/datasets/VOC/ --subset val再通过TFRecord对标签数据进行预处理,并生成 tf.data.dataset 数据集类型,代码katacv/utils/VOC/build_dataset.py。
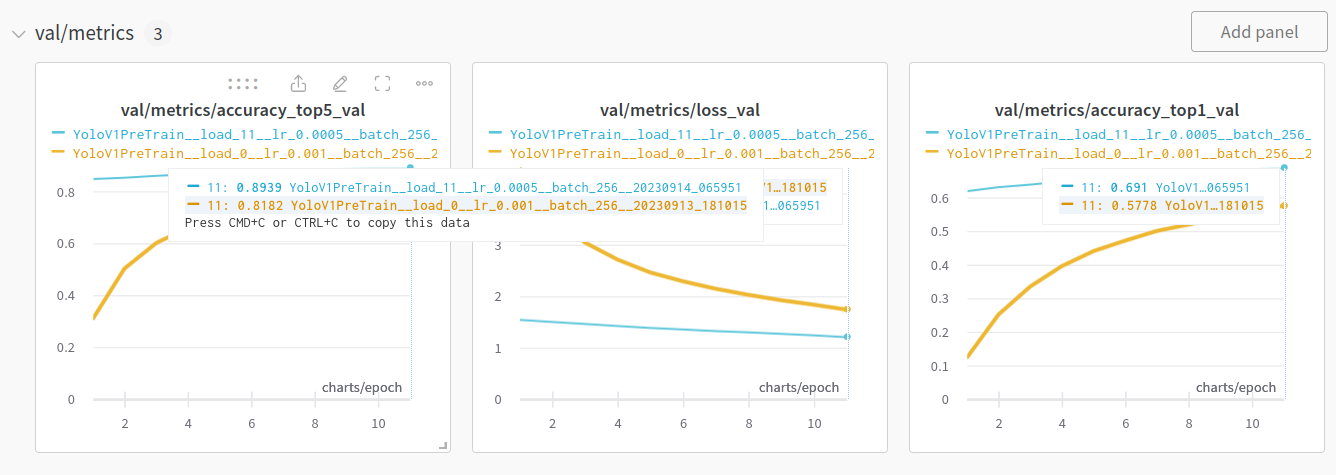
再在Imagenet2012上对Darknet-20进行预训练,代码katacv/yolov1/yolov1_pretrain.py,训练结果:
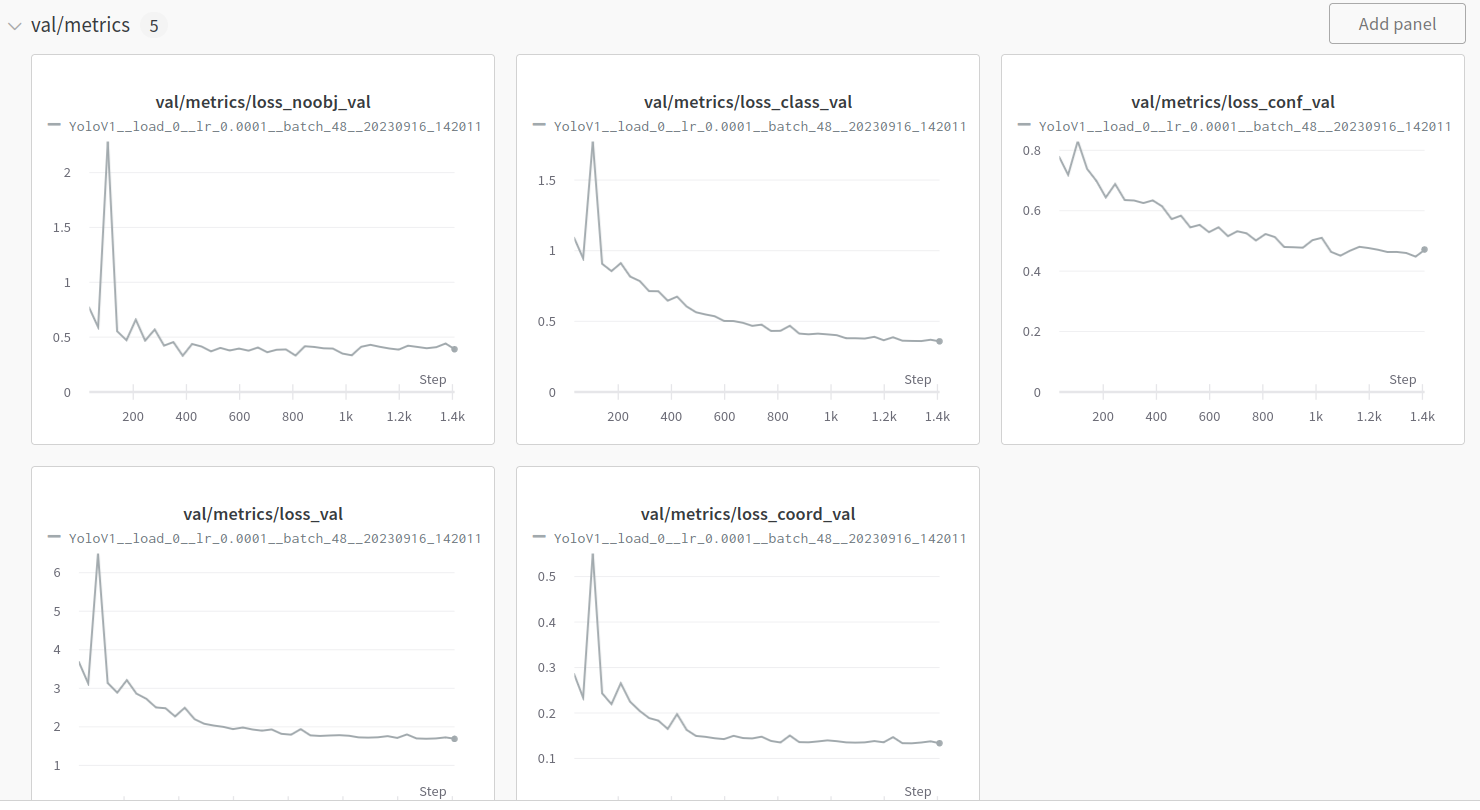
最后训练目标识别网络,代码katacv/yolov1/yolov1.py,训练结果:
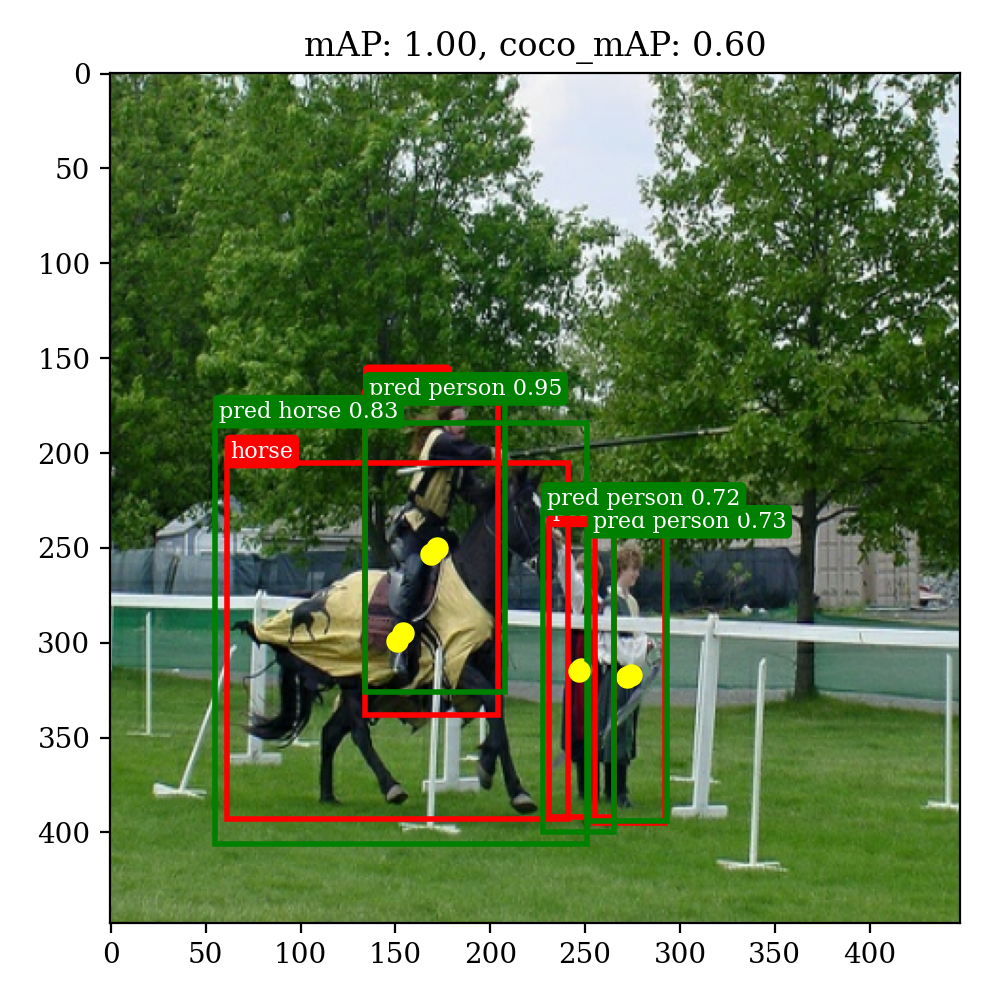
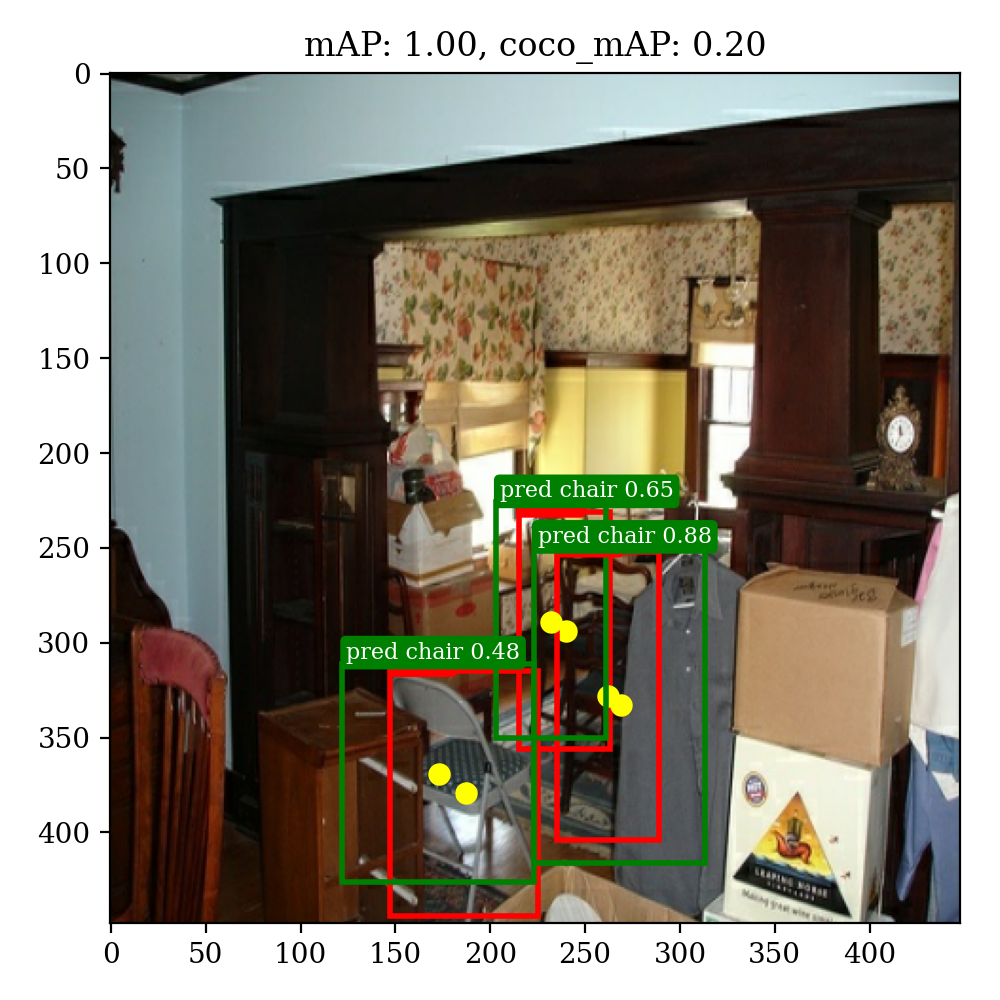
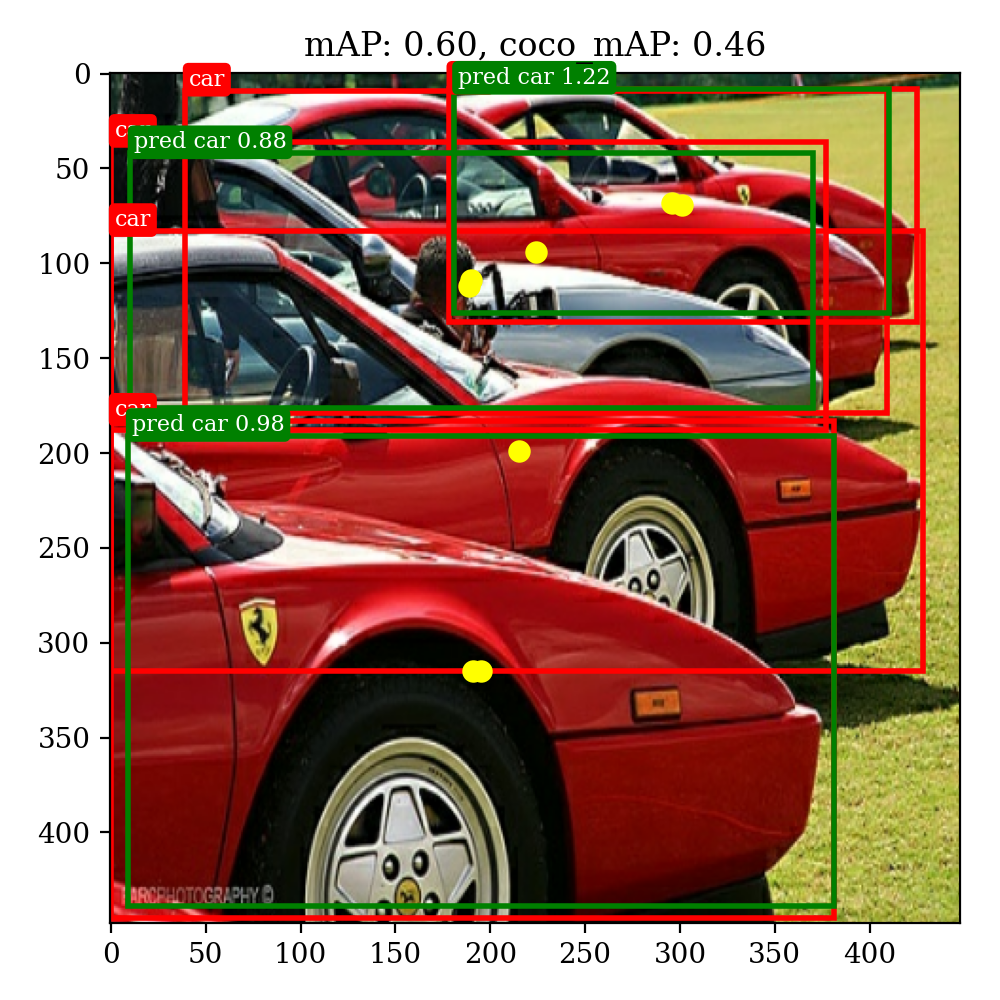
通过测试我们得到在自己划分的验证集上,YOLOv1的预测结果如下,论文上给出的mAP为57%(还有些差距,估计是学习率调整和数据集划分上的区别):
average mAP: 0.52847098262852
average coco mAP: 0.279217751483262可视化结果
通过Jupyter的易交互性,我们可以实现自定义上传文件并进行识别(视频识别还未完成)代码,效果如下: