最新更新于: 2024年6月18日上午10点14分
概述
SAC算法可以简单理解为一种将Q-Learning用于策略 πθ(a∣s) 估计的算法,由于使用了策略网络,所以可以用于解决连续问题,与梯度策略定理(A2C)或策略迭代定理(TRPO,PPO)不同,SAC策略网路的更新目标浅显易赅,就是要近似 Qπ∗(s,⋅) 对应的 softmax 分布,不过这里的价值状态函数还引入了熵正则项,直观理解就是将原有的奖励 rt 的基础上加入了下一个状态的信息熵,从而变为 rtπ:=rt+γαH(π(⋅∣st+1))(其中 α 为温度系数,H 为信息熵),我们可以用下图来对其进行直观理解,其中红色部分就是SAC折后回报所包含的项:
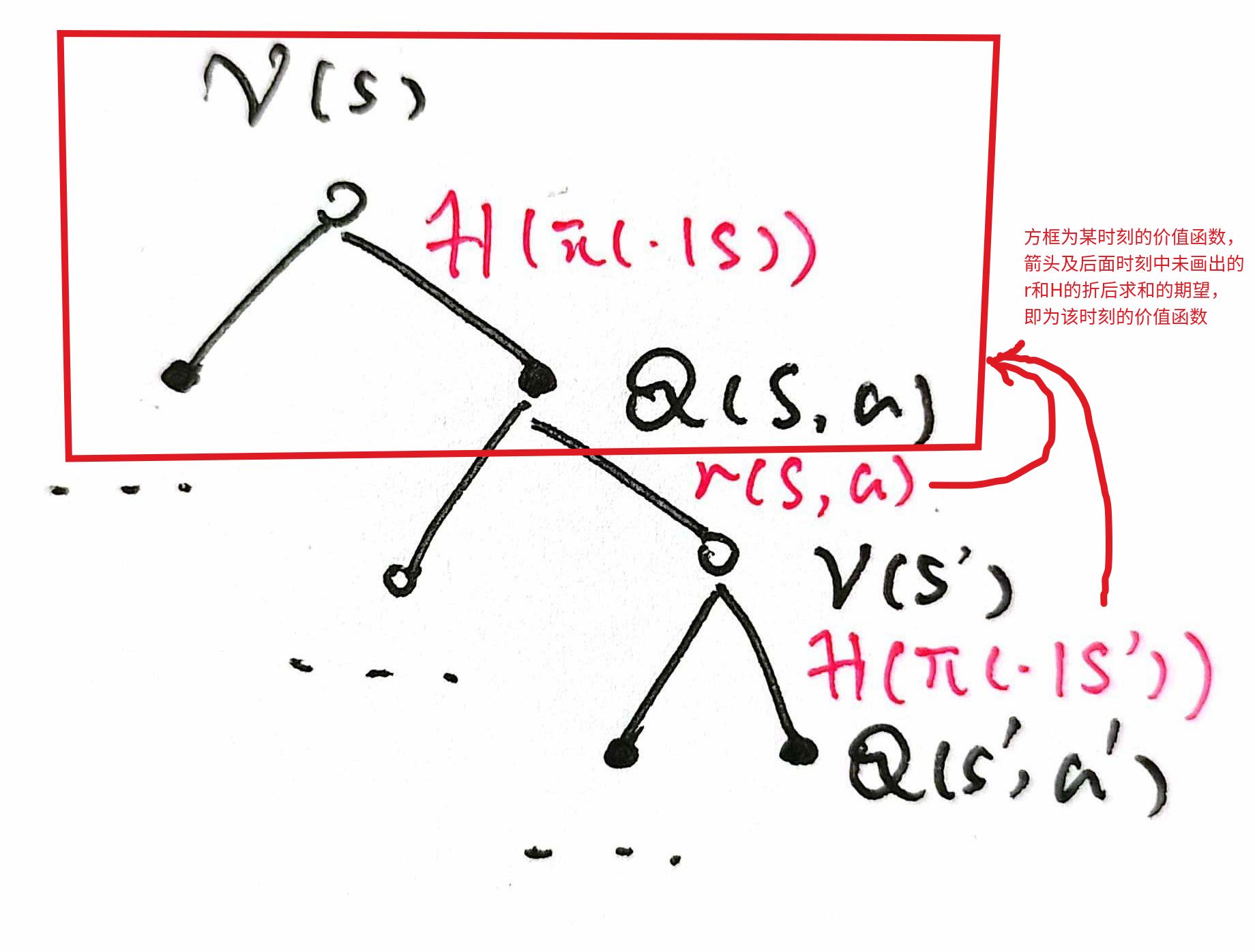
参考文献:1. Soft Actor-Critic Algorithms and Applications
理论推导
定义1(软价值函数 soft-value function)
定义策略 π 的软动作价值函数和软状态价值函数如下:
Qπ(st,at)==Vπ(st)=Eρt+1∼π[i=t∑∞γi−t(Ri+γαH(π(⋅∣St+1)))∣St=st,At=at]Eρt+1∼π[i=t∑∞γi−t(Ri−γαlogπ(Ai+1∣Si+1))∣St=st,At=at]Eρt+1∼π[i=t∑∞γi−t(Ri+γαH(π(⋅∣St+1)))∣St=st]
且有 V(st)=EAt∼π(⋅∣st)[Q(st,At)]。
定义2(SAC最优化目标)
SAC算法的目标为最大化带有熵正则的折后回报:
π∗=πargmaxEρ∼π[t=0∑∞γi−t(Rt+γαH(π(⋅∣St+1)))]=πargmaxES[Vπ(S)]
其中 ρ=(S0,A0,S1,A1,⋯) 为一幕序列,ρ∼π 表示 At∼π(⋅∣St), ∀t⩾0,α 为温度系数,γ∈(0,1) 为折扣率。
定理3(状态价值估计)
原Bellman方程:Qπ(st,at)=软Bellman方程:Qπ(st,at)== ESt+1,At+1[Rt+γQπ(St+1,At+1)∣st,at] ESt+1,At+1[Rt+γαH(π(⋅∣St+1))+γQπ(St+1,At+1)∣st,at] Rt+γESt+1,At+1[Qπ(St+1,At+1)−αlogπ(At+1∣St+1)]
故可通过TD-1的方法对 Qπ(s,a) 进行估计。
证明:只需将原Bellman方程中的 Rt 换成 Rt+γαH(π(⋅∣St+1)) 即可。
定理4(策略更新)
对于一列策略 {πk},若其满足一下递推关系:
πk+1←πargminDKL(π(⋅∣s)∣∣∣∣∣∣∣∣∣∣Zπk(s)exp(α1Qπk(s,⋅))),(k∈N)
其中 Zπk(s)=∑a∈Aexp(α1Qπk(s,⋅)) 及归一化系数(partition function),若 πk 收敛,则 πk 收敛到定义2中最优化目标的一个局部最优解。
观察:该定理告诉我们 π 的更新方向就是当前 Qπ(⋅∣s) 对应的softmax分布。
证明:(对KL散度进行拆分化减,在利用Bellman方程进行迭代证明,该证明类似Q-Learning中对Q函数迭代更新的证明)
Jπ(πk):=== DKL(π(⋅∣s)∣∣∣∣∣∣∣∣∣∣Zπk(s)exp(α1Qπk(s,⋅)) DKL(π(⋅∣s)∣∣exp(α1Qπk(s,⋅)−logZπk(s))) Ea∼π(⋅∣s)[logπ(a∣s)−α1Qπk(s,a)+logZπk(s)]
又由于 Jπk+1(πk)⩽Jπk(πk),则
Ea∼πk+1(⋅∣s)[logπk+1(a∣s)−α1Qπk(s,a)+⩽Ea∼πk(⋅∣s)[logπk(a∣s)−⇒Ea∼πk+1(⋅∣s)[logπk+1(a∣s)−α1Qπk(s,a)]⩽⩽⇒Vπk(s)⩽Ea∼πk+1(⋅∣s)[Qπk(s,a)−αlogπk+1 logZπk(s)] α1Qπk(s,a)+logZπk(s)] Ea∼πk(⋅∣s)[logπk(a∣s)−α1Qπk(s,a)] −α1Ea∼πk(⋅∣s)(Qπk(s,a))=−α1Vπk(s) (a∣s)]
于是 ∀(st,at)∈S×A 有
Qπk(st,at)=⩽=⩽== ESt+1∼p(⋅∣st,at)[Rt+γVπk(St+1)] ESt+1∼p(⋅∣st,at)At+1∼πk+1[Rt+γQπk(St+1,At+1)−αlogπk+1(At+1∣St+1)] ESt+1∼p(⋅∣st,at)At+1∼πk+1[Rt−αlogπk+1(At+1∣St+1)]+γESt+1,At+1,St+2[Rt+1+γVπk(St+2)] ⋯ Eρt+1∼πk+1[i=t∑∞γi−t(Ri−γαlogπk+1(Ai+1∣Si+1))] Qπk+1(st,at)
由上式可知 πk 收敛到定义2中最优化目标的一个局部最优解
QED
动态调整温度系数
最后一个问题就是温度系数 α 的大小问题,论文[1]中引入了一个带约束的最优化问题:
πmaxs.t. Eρpi[t=0∑TRt)] Eρπ[H(π(⋅∣st)]⩾Hˉ
其中 Hˉ 表示目标信息熵(带约束的目标中要求所有 H(π(⋅∣s))⩾Hˉ,及 Hˉ 为轨迹中所有状态对应的策略的信息熵集合的下界),作者通过使用对偶问题,将 α 视为一个Lagrange乘子,然后将回报展开,从最终状态递归求解 α,最后得到的结论为下式:
α∗=αargminEa∼π∗[−αlogπ∗(a∣s;α)−αHˉ)=α[H(π(⋅∣s))−Hˉ]=:J(α)
其中 π∗(⋅∣s;α) 表示在 α 给定的前提下,能够最大化奖励和带有 α 温度系数的熵正则项的策略,在实际算法中直接用当前的策略 π 近似。则 ∂α∂J=H(π(⋅∣s))−Hˉ,这里只能用梯度下降更新因为直接求解 α 要么是 +∞ 或 −∞。
算法实现
利用TD3中的双截断 Q 值对动作价值函数进行估计,共包含五个网络
πϕ(a∣s), qθi(s,a), qθi−(s,a),(i=1,2),
其中 qθi− 为 qθi 对应的目标网络。
交互和训练方法和DQN类似,首先用策略 πϕ(a∣s) 和环境进行交互,并将得到的状态四元组 (s,a,r,s′) 存入记忆缓存当中。
然后每次从缓存中采样得到一个固定大小的batch记为 B,更新可分为一下三步:
- (Critic)计算 (s,a,r,s′) 对应的TD目标 y^(r,s′)=r+γEa∼π(⋅∣s′)[i=1,2minqθi−(s′,a)−αlogπϕ(a∣s′)],最小化动作价值函数对应的损失,用梯度下降对参数进行更新:
θiminL(θi)=2∣B∣1(s,a,r,s′)∈B∑∣qθi(s,a)−y^(r,s′)∣2,(i=1,2)
- (Actor)最小化 DKL(π(⋅∣s)∣∣∣∣∣∣∣∣∣∣Zπk(s)exp(α1Qπk(s,⋅))) 等价于最小化以下目标(定理4中已推导),用梯度下降对参数进行更新:
ϕminL(ϕ)=∣B∣1(s,a,r,s′)∈B∑Ea∼π(⋅∣s)[αlogπϕ(a∣s)−i=1,2minqθi(s;a)]
- (自动调节温度系数 α,也可以直接固定 α=0.2 不自动调节)首先确定超参数目标信息熵下界 Hˉ=−λ1⩽i⩽∣A∣∑∣A∣1log∣A∣1=λlog∣A∣ 其中 λ∈(0,1) 为超参数。使用梯度下降对 α 进行更新:
∂α∂J(α)=∣B∣1(s,a,r,s′)∈B∑H(π(⋅∣s))−Hˉ
训练效果
在KataRL中用JAX完成了SAC的实现核心代码 sac_jax.py,使用方法:
python katarl/run/sac/sac.py --train --wandb-track
python katarl/run/sac/sac.py --train --wandb-track --env-name Acrobot-v1 --flag-autotune-alpha no
训练效果可以见wandb的报告,看得出来SAC只能勉强在Cartpole-v1上和DDQN打平手,最终稳定性较优;但在Acrobot-v1上效果极差,调参也难以解决。
主要的超参数为目标信息熵大小 \bat{\mathcal{H}},该模型对该参数的敏感度极高,或者可以不自动调整 α,固定 α=0.2。