计算机视觉与模式识别(CVPR) 期末复习
最新更新于: 2024年5月24日上午11点17分
计算机视觉为1-11题,模式识别为12-17题
- 卷积的性质及证明,卷积的计算
- 双线性插值,计算例子
- 双边滤波,原理,效果
- 六种二维几何变换矩阵具体是什么,及对应的性质
- Canny边缘检测,具体步骤,什么是好的边缘(这里我没写,ppt里有不难)
- Harris角点检测检测,具体步骤,不变性与等变性
- 相机坐标变换,给出例子计算结果
- 三维的RANSAC阐述算法过程,计算得到至少一个正常点对概率p(三维和二维的区别就是把n=3)
- 极点和极限定义,根据基础矩阵求对极限(概念)
- 给出具体的基础矩阵,给像点求对极线,并求出左右极点
- L-K光流估计,当物体移动较大时L-K估计的问题,解决方法Coarse-to-fine(Gauss金字塔)
- 3个简单选择题,例:多分类选择Softmax函数,二分类选sigmoid函数
- 最近邻,K近邻
- 排序题,五个选项,对随机梯度下降法操作顺序排序
- 给出输入大小,卷积核大小,给出输出的计算公式,计算输出大小
- 链式求导(流式梯度下降),只有两步非常简单,带sigmoid的计算图
- Adam的设计思路和具体计算方法
高斯核,中值滤波,双边滤波,fourier变换,频域和空间域的关系,图像变换和逆变换,插值,Gauss金字塔和Laplace金字塔(4题)
tiny边缘检测,计算图像梯度,NMS,角点检测(平移不变性,旋转不变性),shift描述子(如何描述平移不变性和旋转不变性),UISIKe(3题)
相机标记,数目视觉,对极几何(4题)
运动场和光流场的区别,光流场反应的运动,光流约束,Gauss大运动转化为小运动(1题)
计算机视觉部分请见PDF:
下面为模式识别部分:
传统分类器
KNN
中间空的区域原理,的情况.
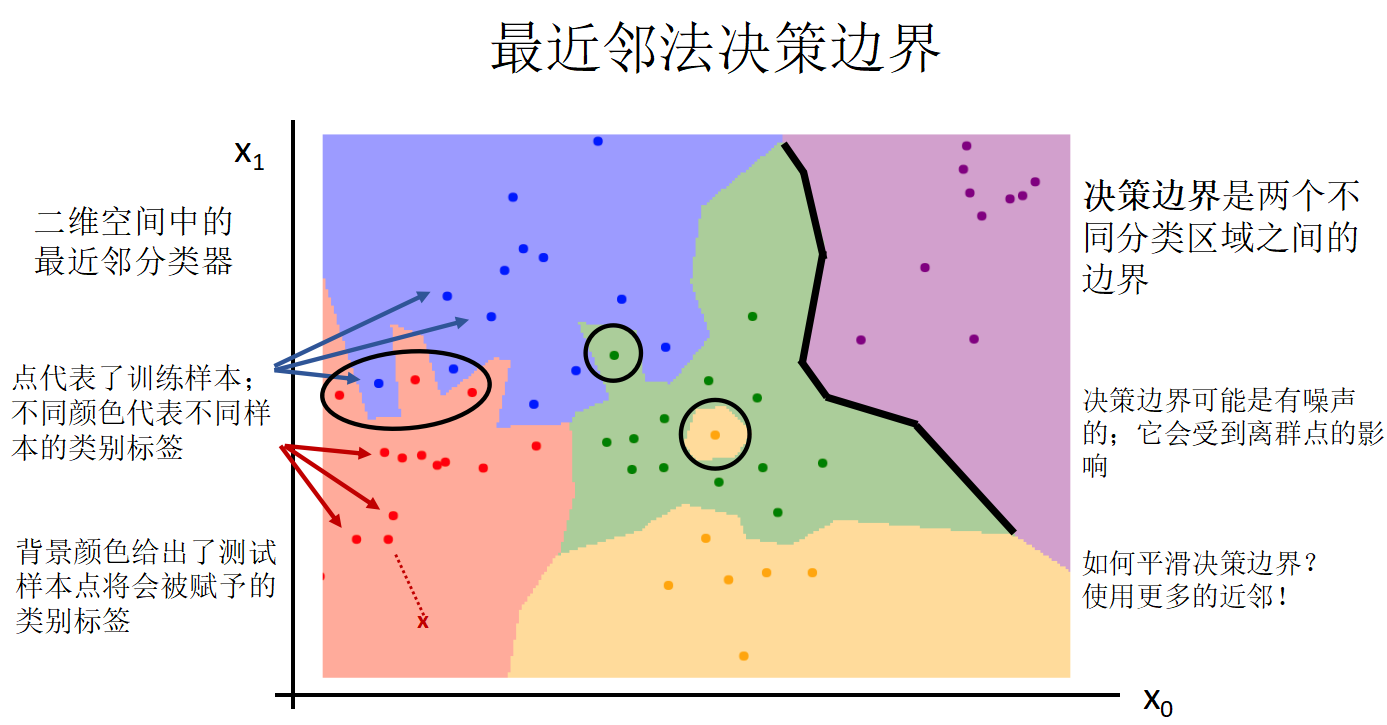
决策边界是两个不同分类区域之间的边界,决策边界可能是有噪声的;它会受到离群点的影响,如何平滑决策边界?使用更多的近邻!
当K>1时,不同类之间可能会出现间隙,这需要用某种方式消除!
贝叶斯分类器
贝叶斯规则(贝叶斯公式)
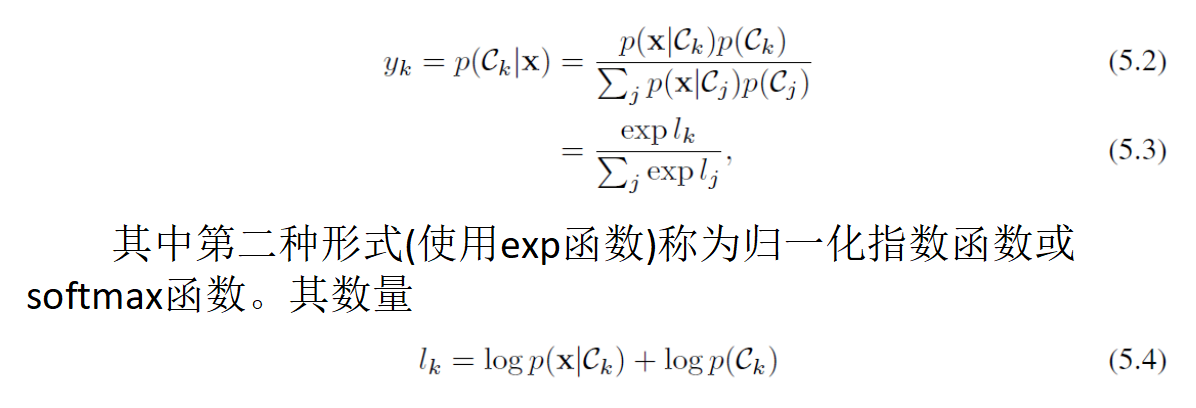

多元高斯分布,确定 的概率分布



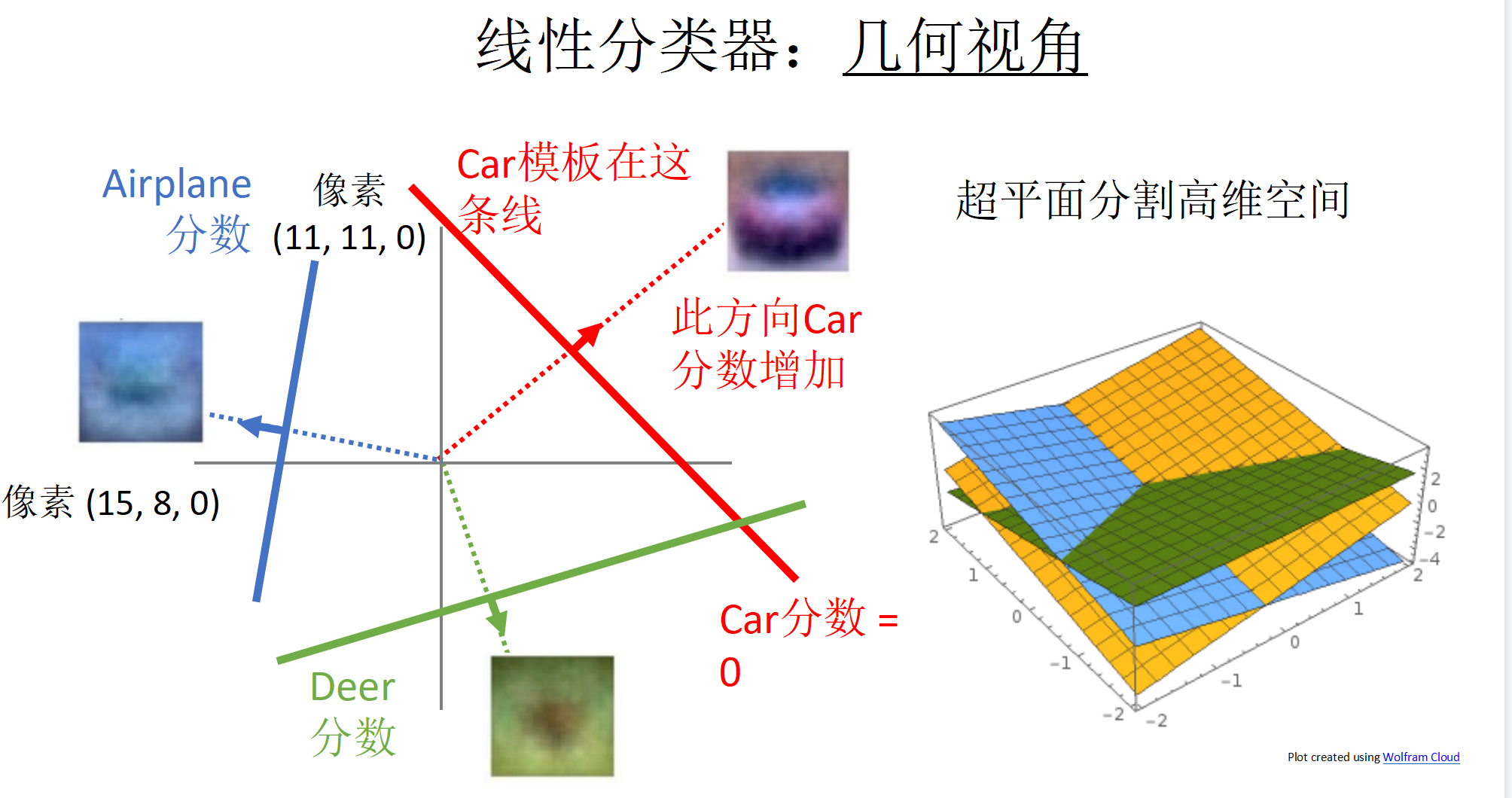
线性分类器
打分机制,从三种不同视角查看分类器结果(代数视角,视觉视角,几何视角)
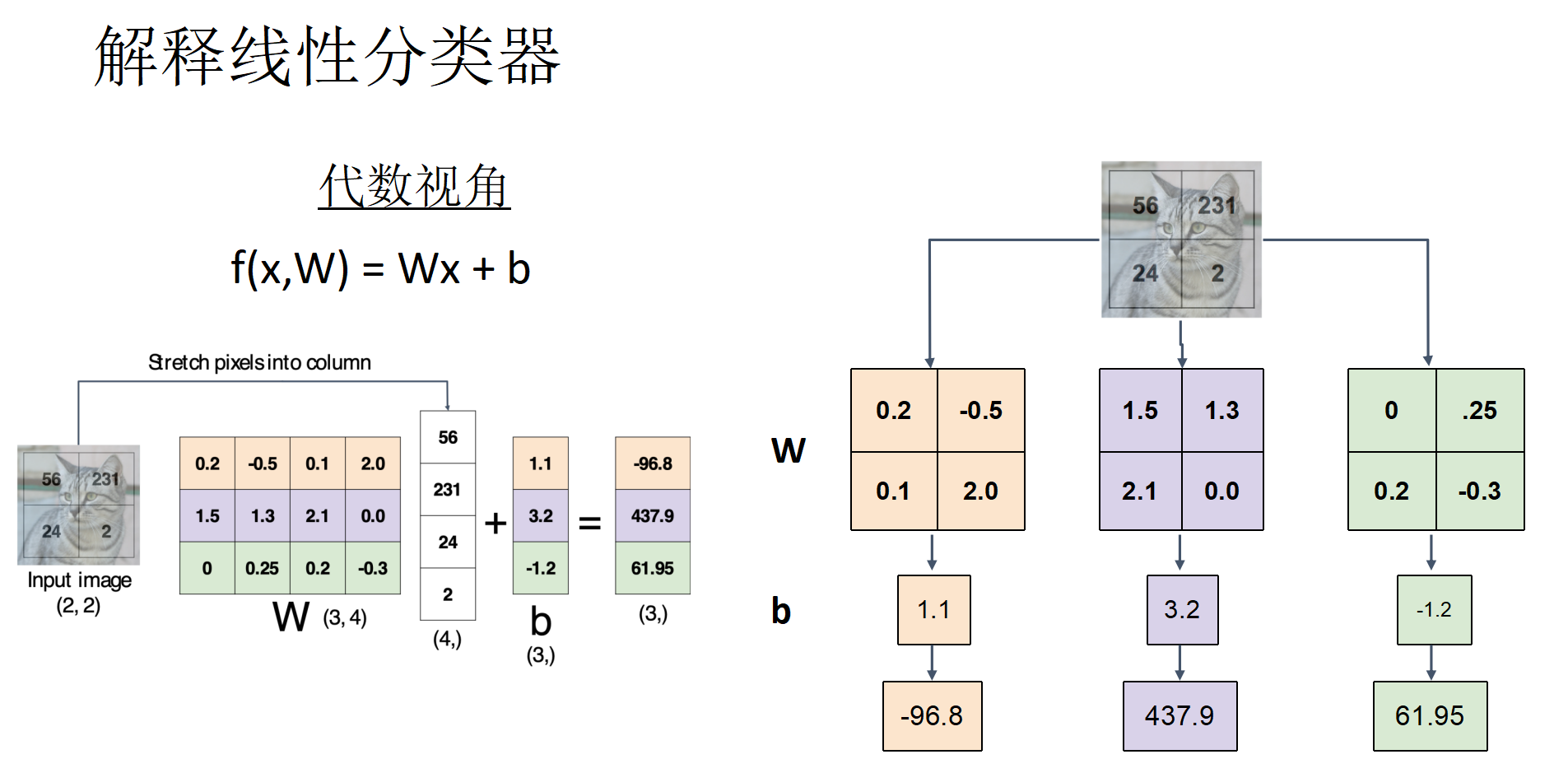
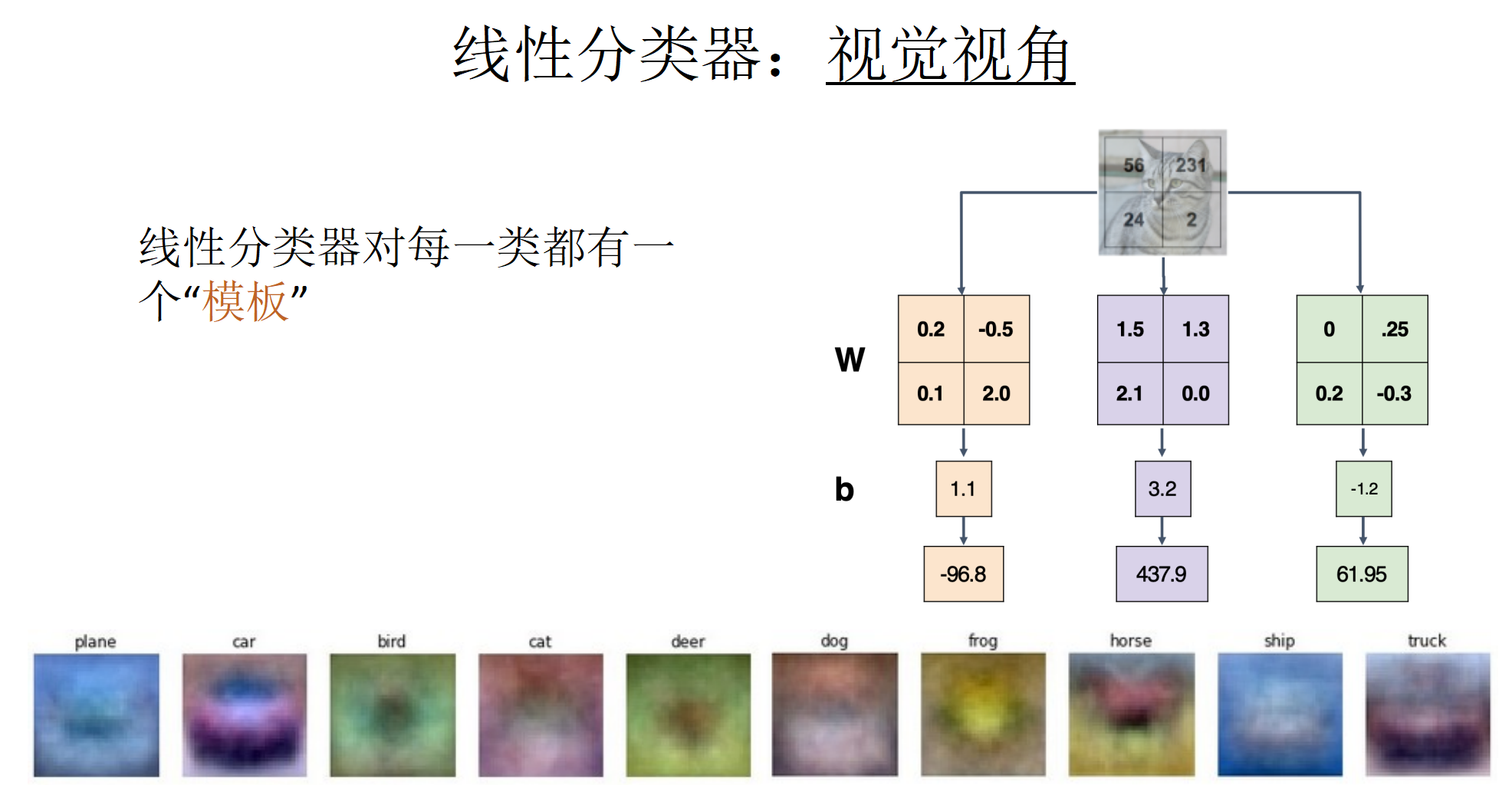
支持向量机


打分函数:Hinge损失

多分类的计算结果;交叉熵损失
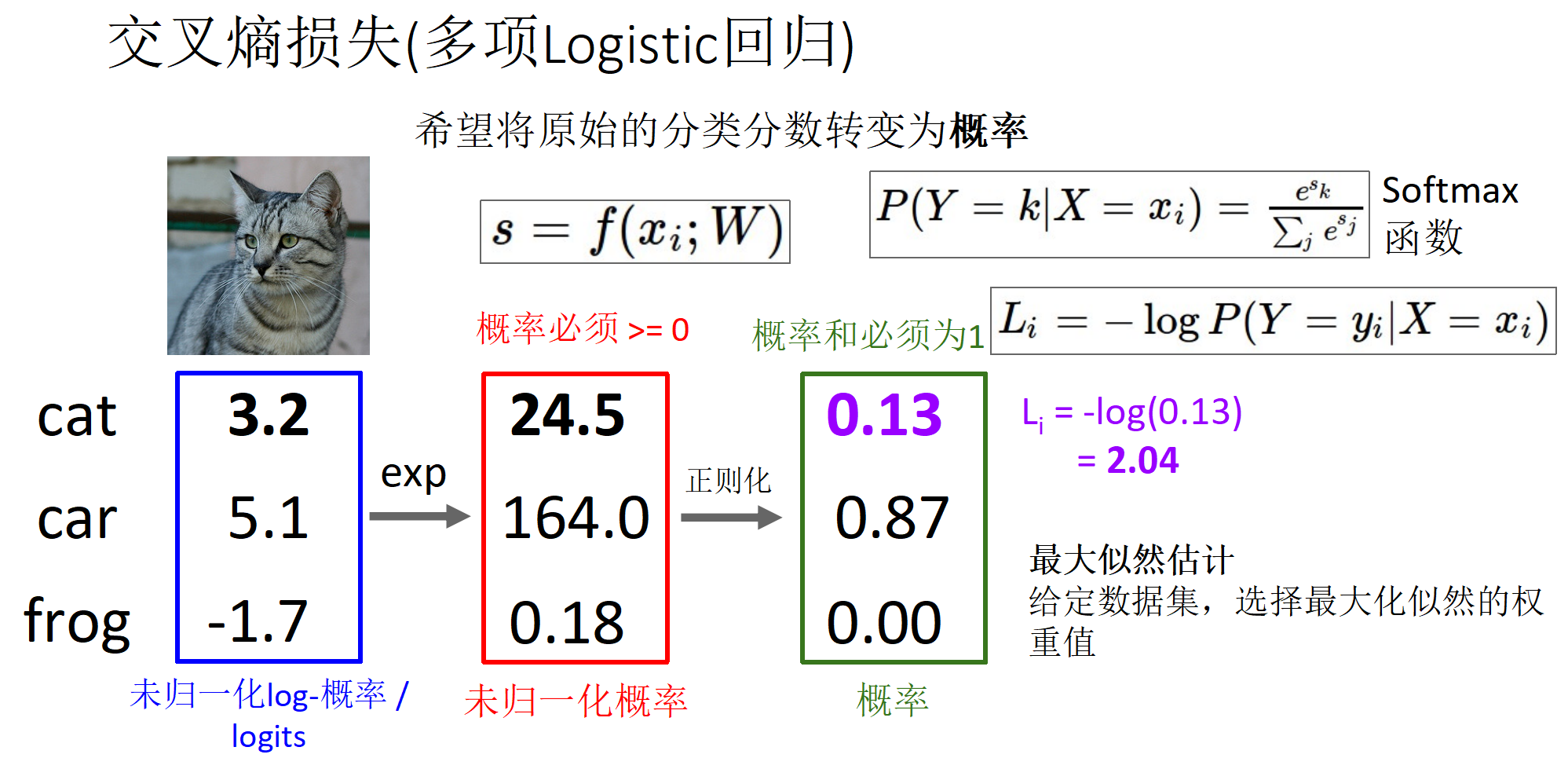
交叉熵损失 vs SVM损失

深度神经网络
如何描述非线性可分问题的解决思路(通过非线性变换)
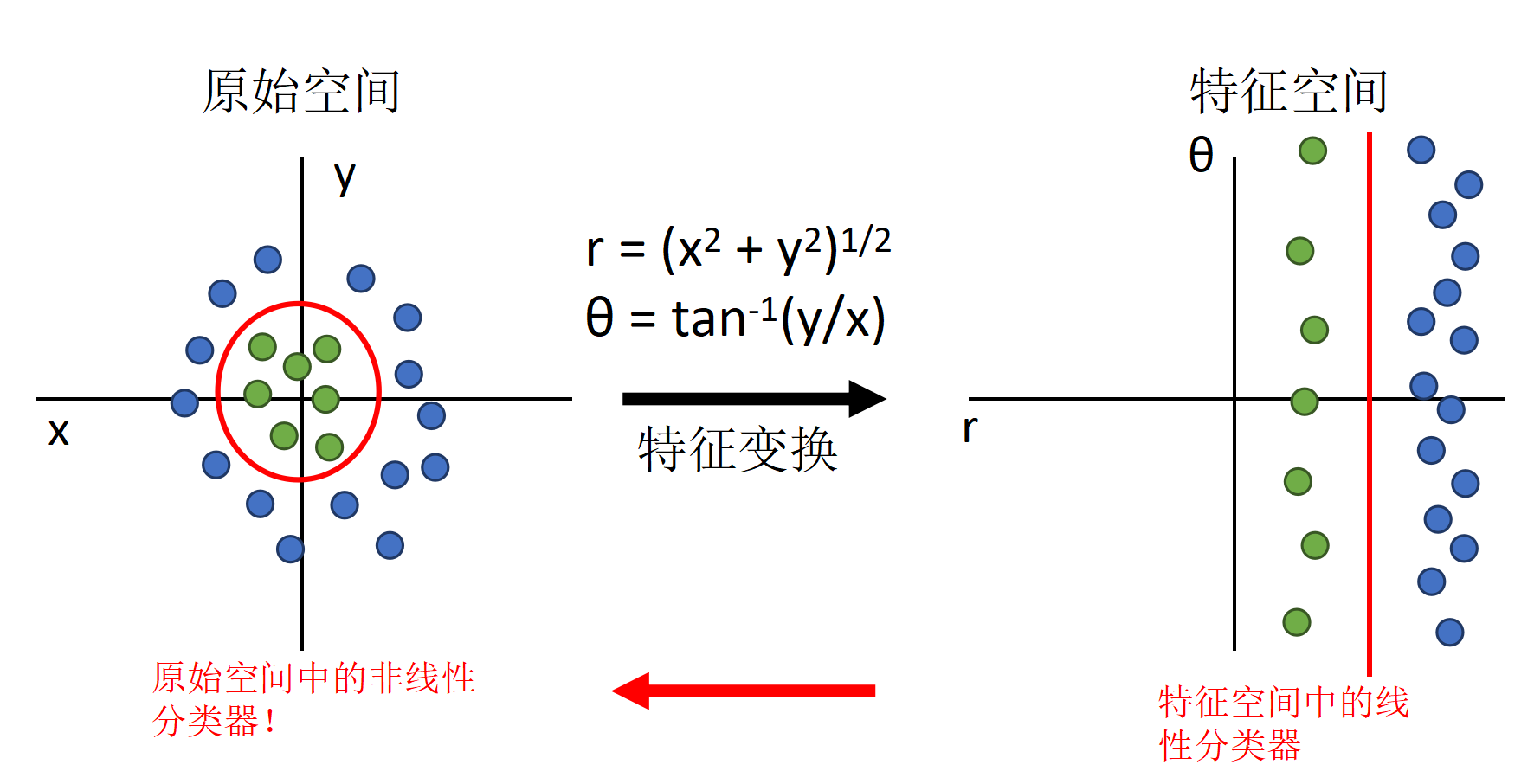
神经网络作为可学习的特征转换
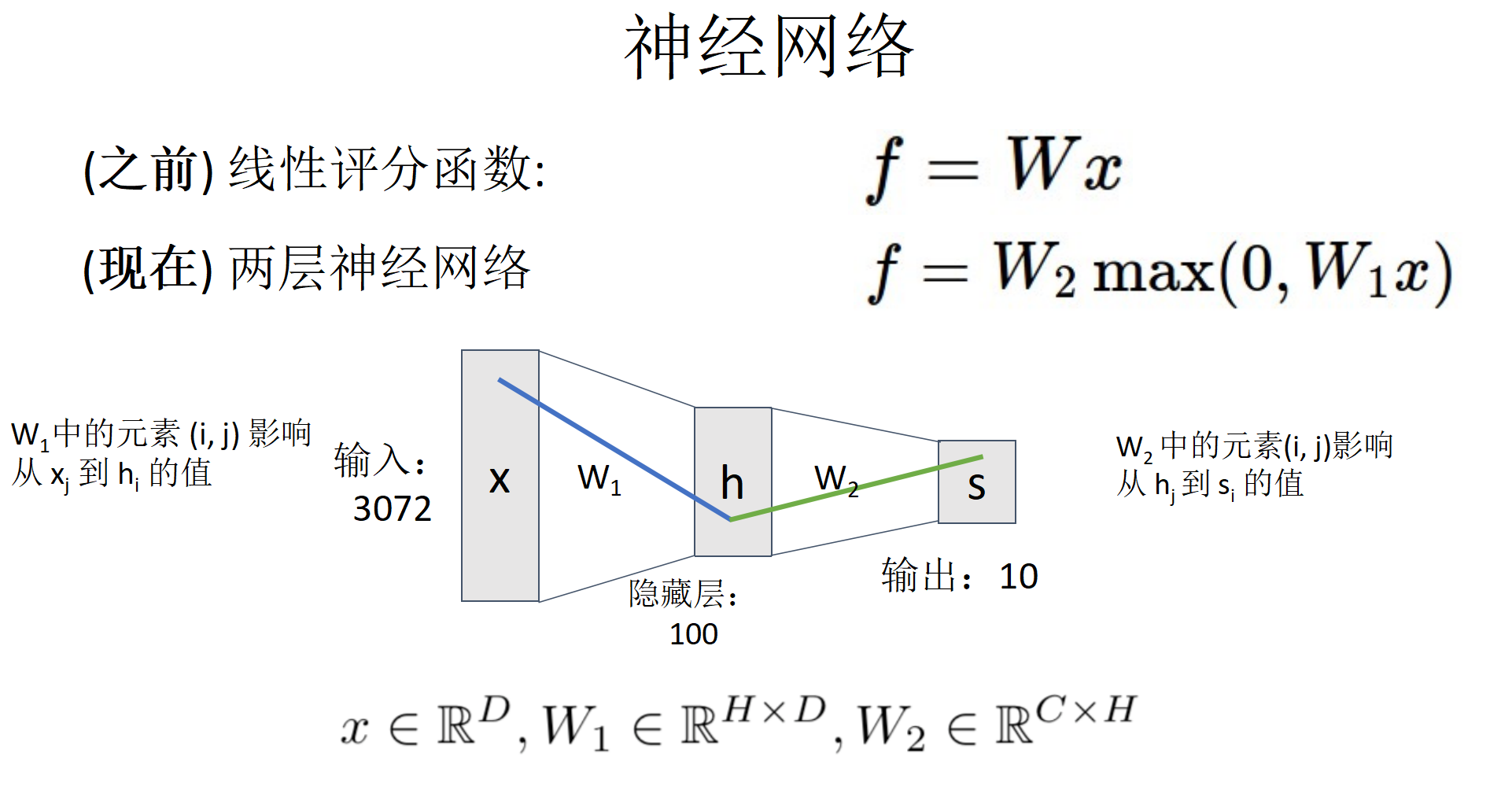
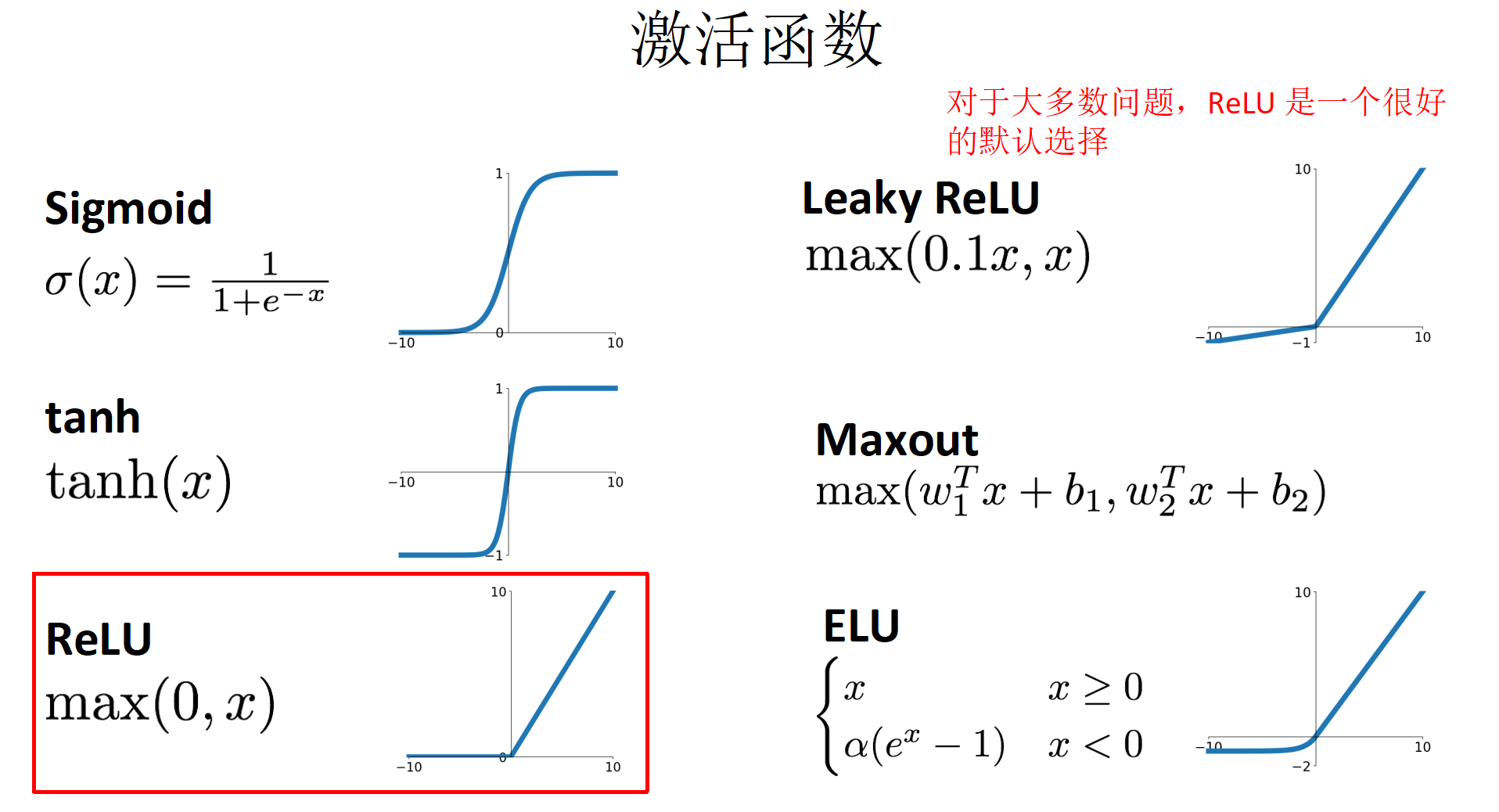
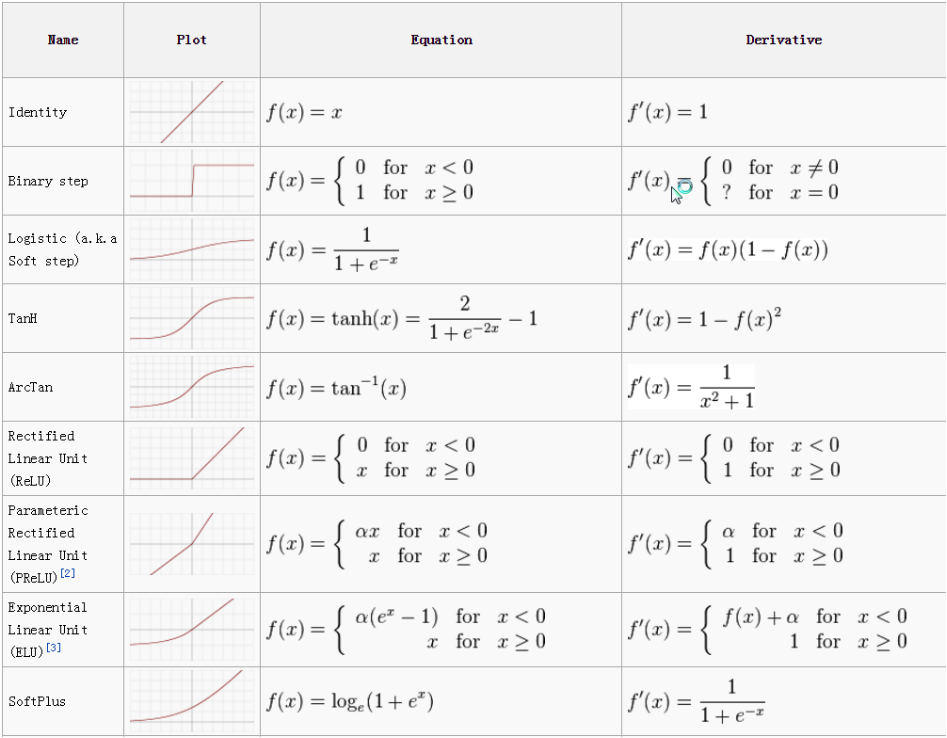
实现非线性变化的原理:激活函数(Sigmoid, tanh, ReLU)掌握梯度计算结果(用于梯度下降法).
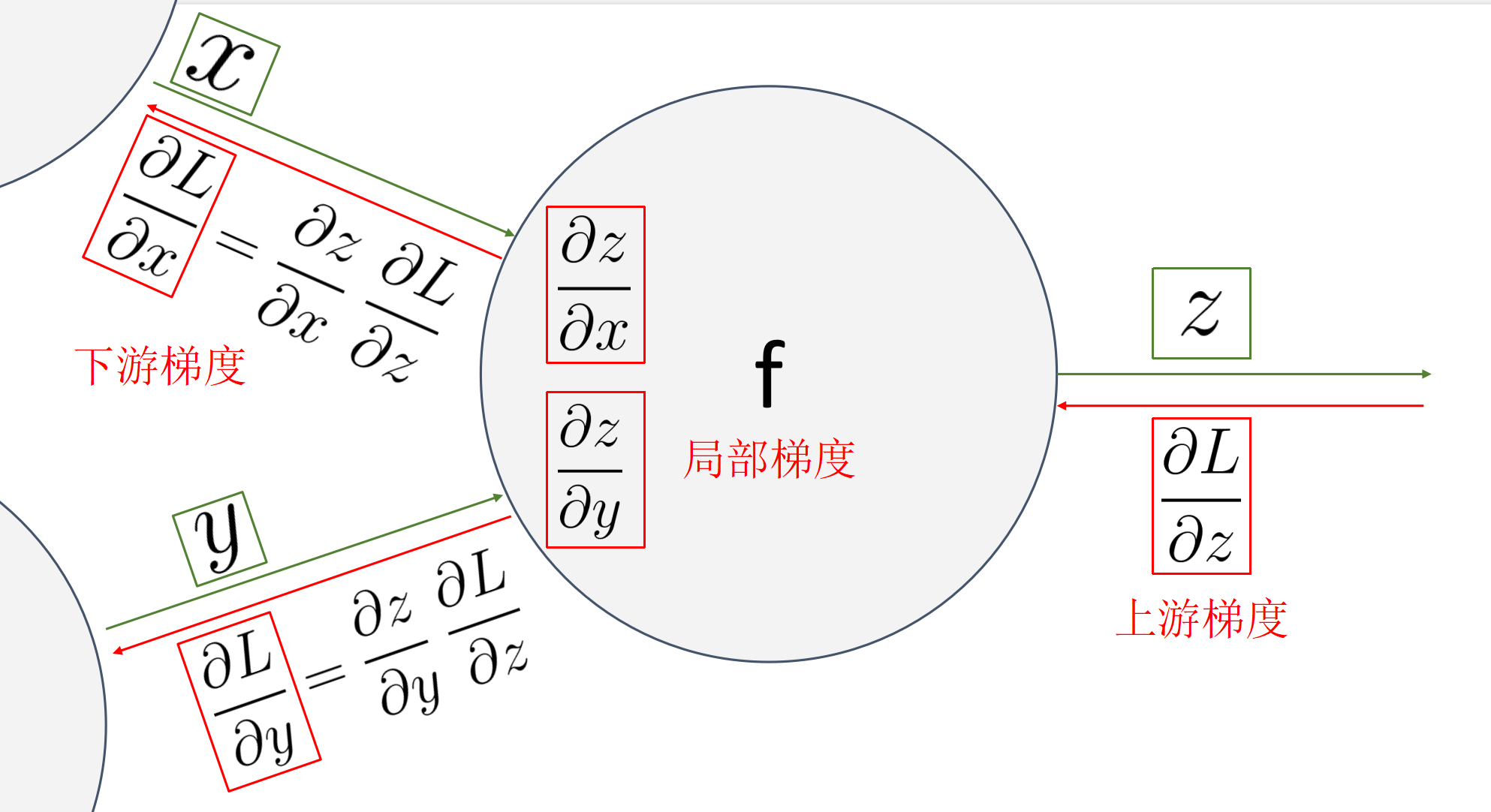
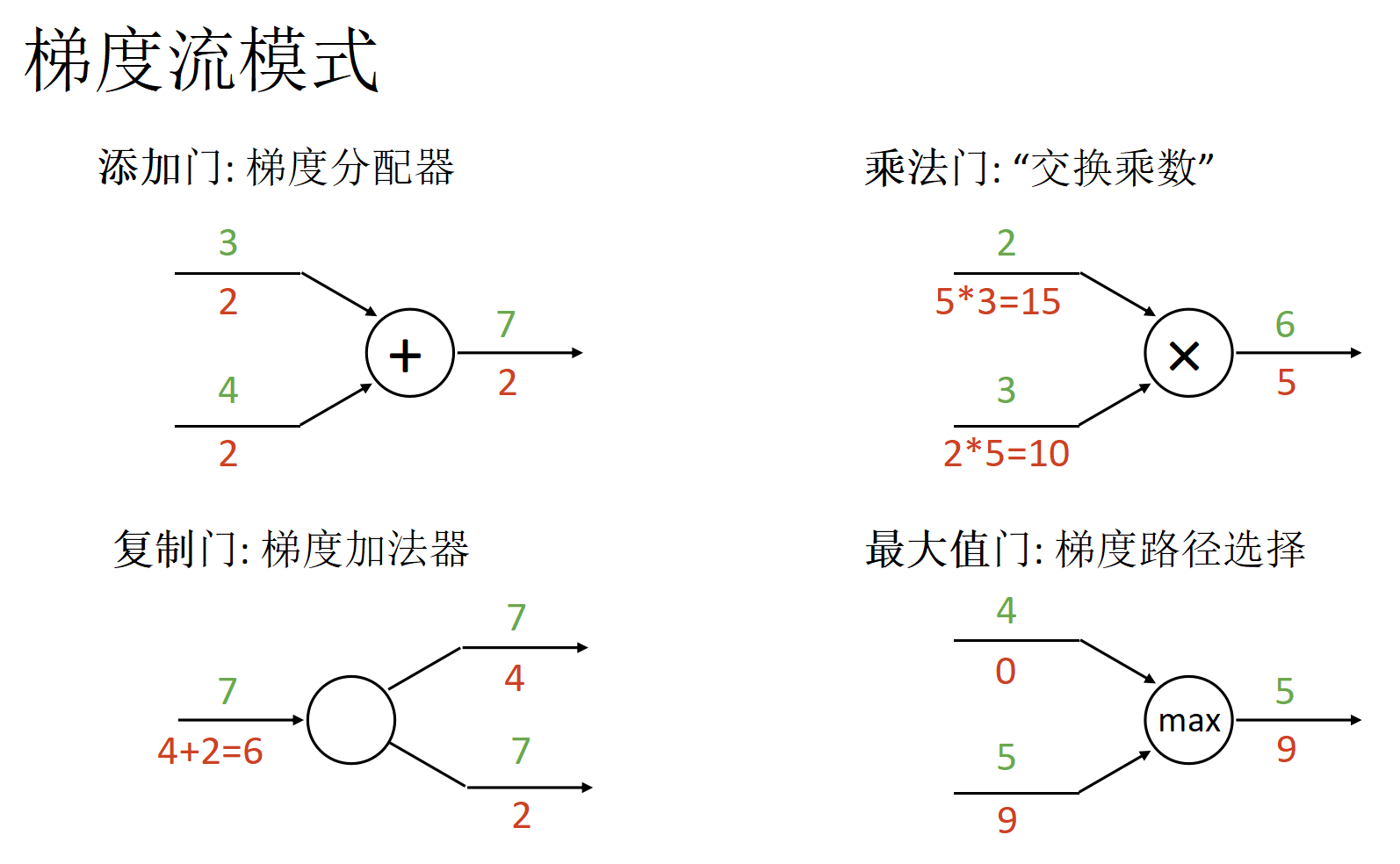
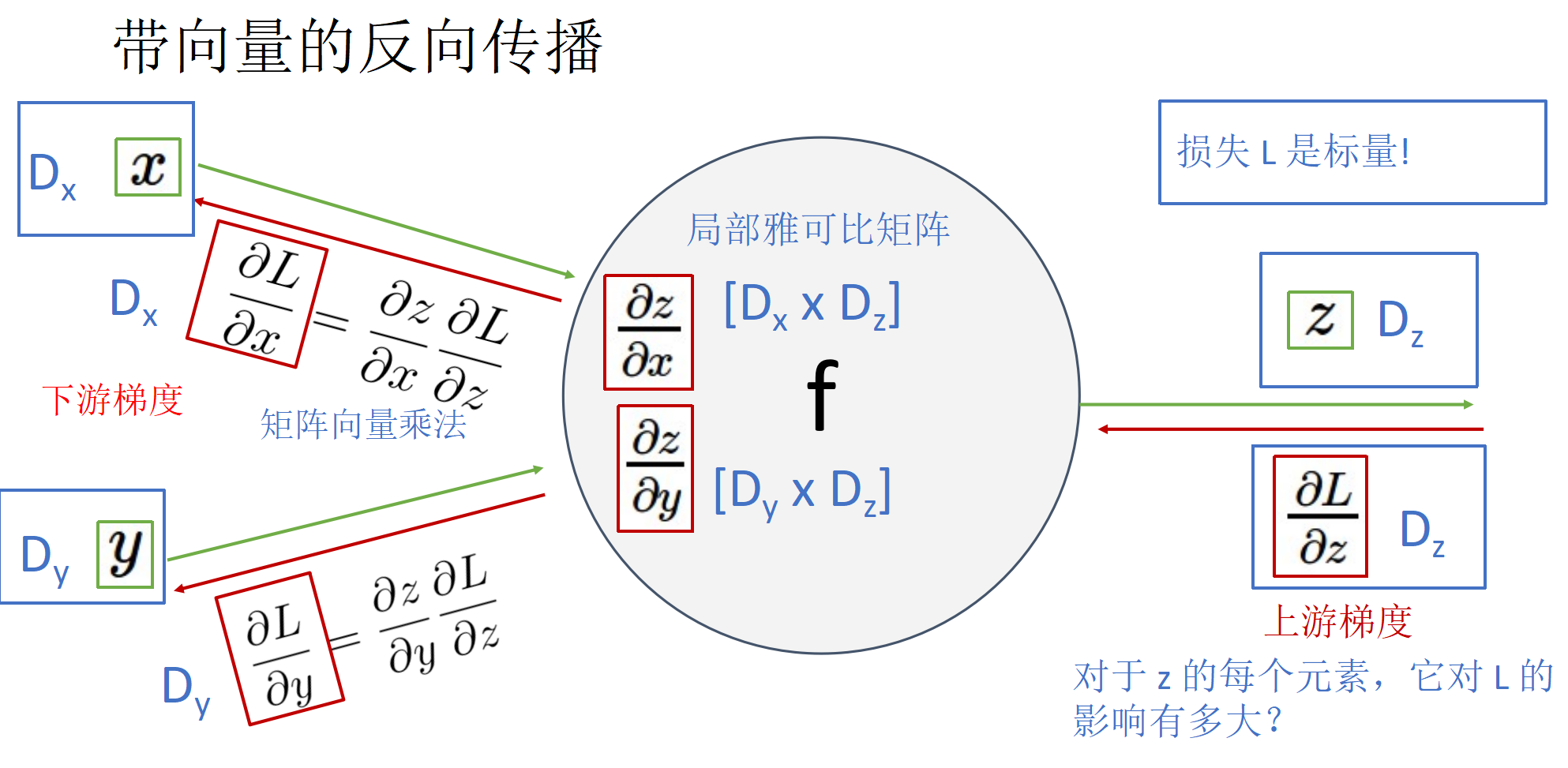
梯度下降法(重点)
通过上游梯度计算下游梯度,掌握梯度反向传播原理. 可能考察标量和矢量计算,不会考察矩阵计算.
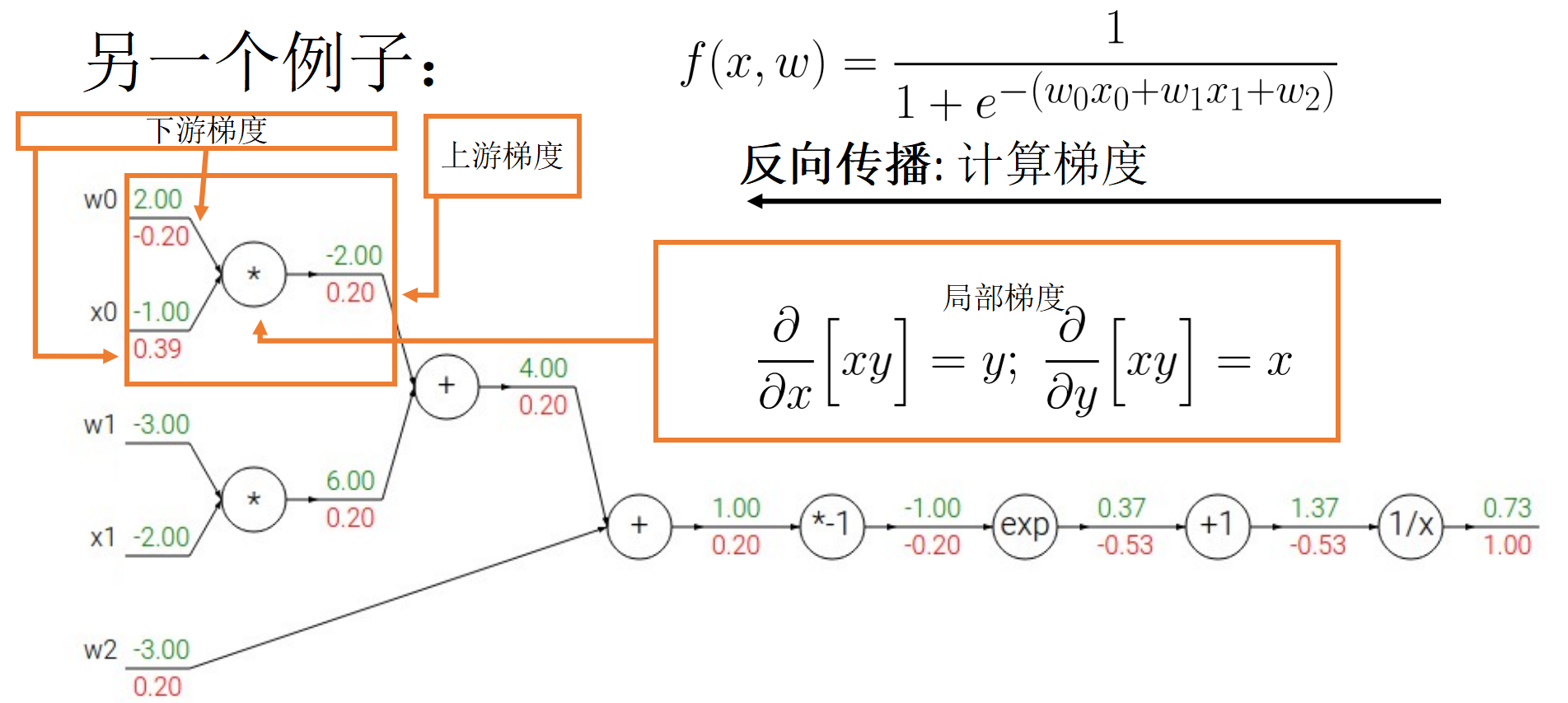
流式传播可以便于求解梯度,计算速度更快.
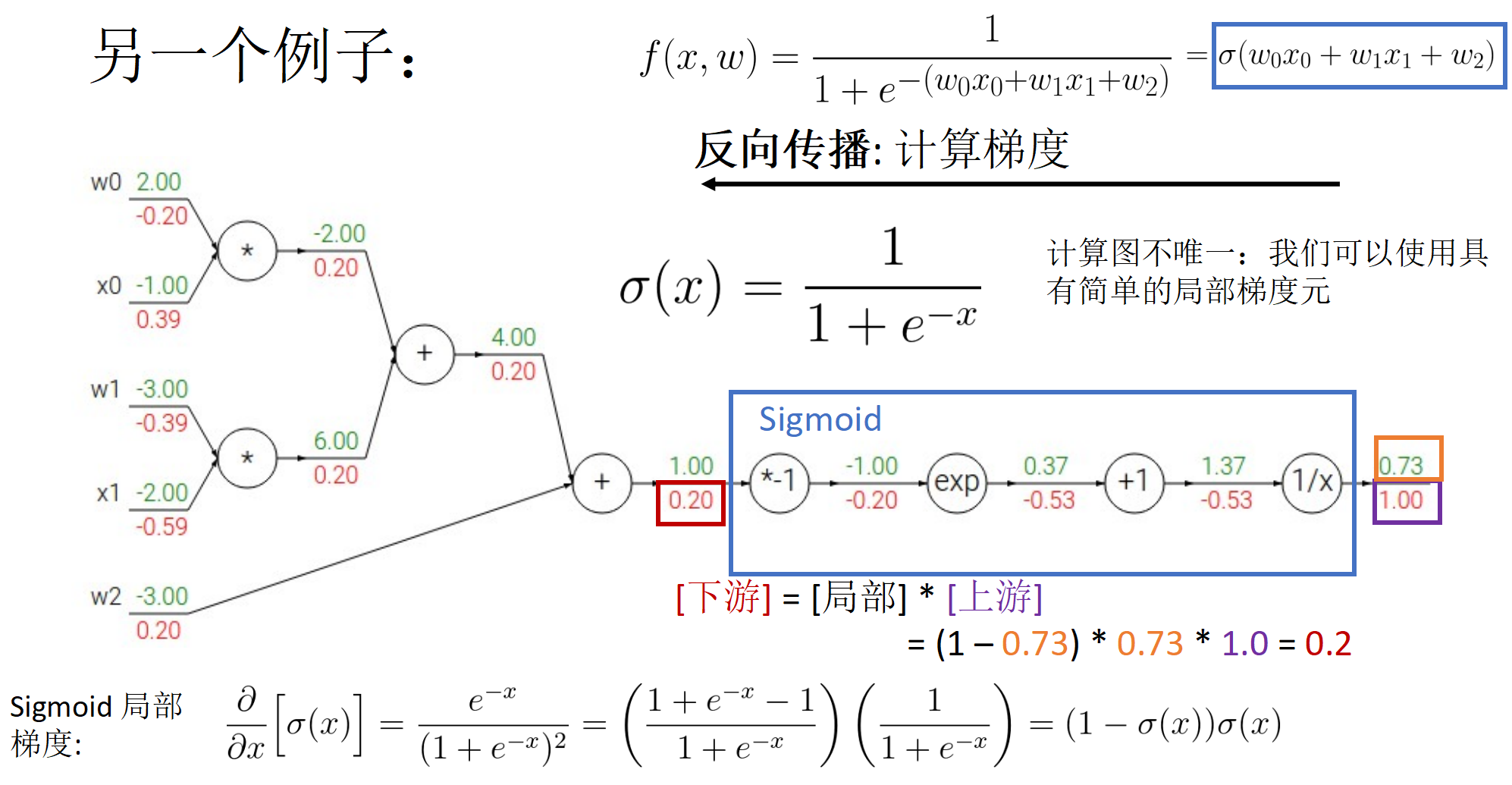
其他激活函数的梯度
优化算法
数值梯度,解析梯度.

随机梯度下降法(SGD)
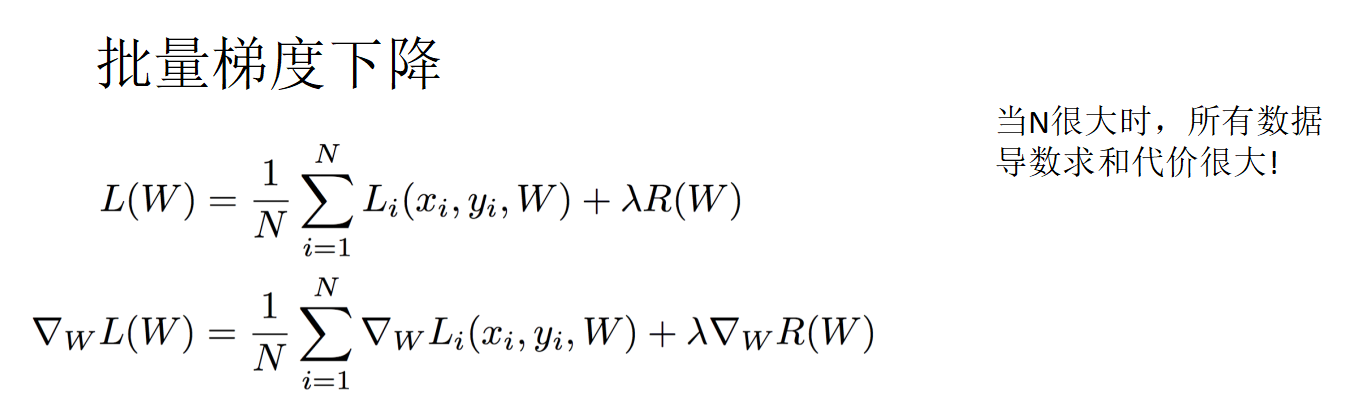


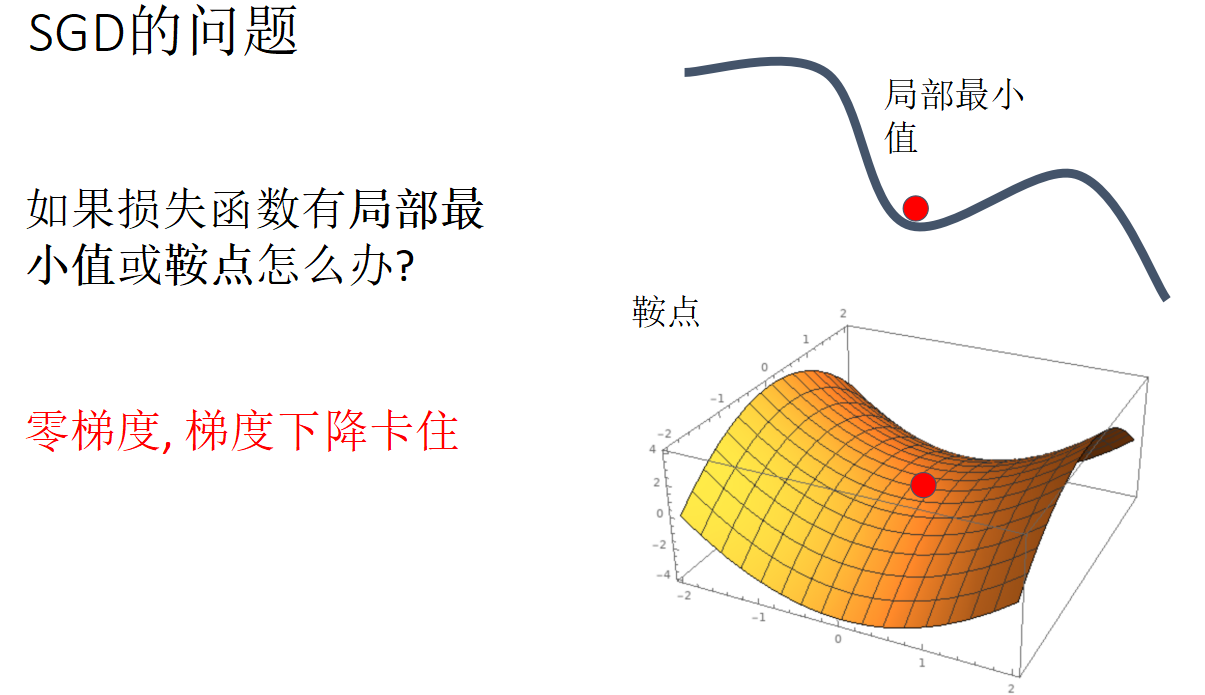
动量(Momentum)的定义,掌握Adam算法原理,解释优化的道理.

上述定义中 称为学习率(步长),两种动量定义:

牛顿动量:使用速度更新到达新的一点,计算这一点的梯度并与速度混合作为当前的更新方向, 为Newton动量中的参数位置,主要因为只想去更新

AdaGrad归一化原理:缩放每个参数反比于其所有梯度历史平方值总和的平方根,也称为“参数学习率”或“自适应学习率”。特点:沿着“陡峭”方向的前进受到阻碍; 沿“平坦”方向前进加快 .
其中 表示第 次更新前的梯度值, 表示第 次更新前全部梯度的二范数平方.
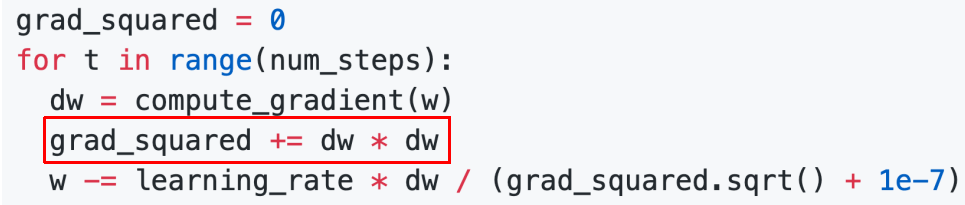
RMSProp: “Leaky Adagrad”,带有衰减系数的Adagrad,令衰减系数为 .

自适应矩估计(Adam):RMSProp + Momentum,Adam同时兼顾了动量 和RMSProp(动量修正 )的优点.
将 称为一阶矩(向量), 称为二阶矩(常量)
当 时,算法无法启动 几乎为 ,所以还需进行偏置修正(修正从原点初始化的一阶矩和二阶矩的估计):
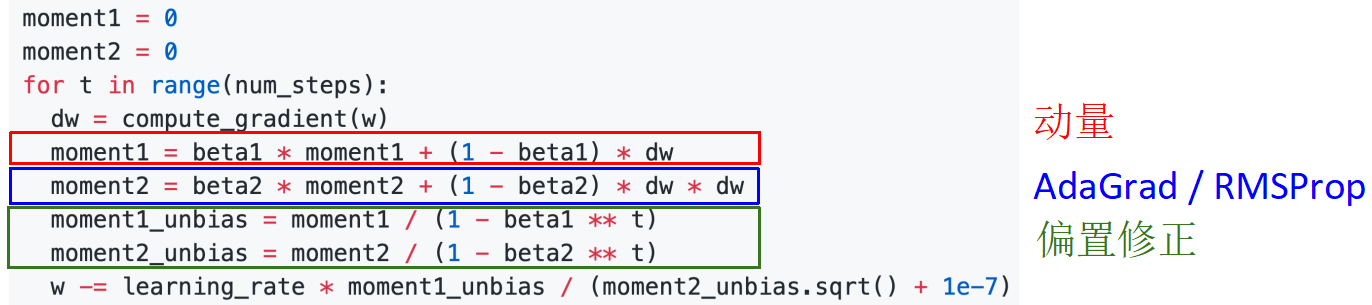
Adam算法中取beta1 = 0.9, beta2 = 0.999, learning_rate = 1e-3, 5e-4, 1e-4对于很多模型来说是一个好的起始点!
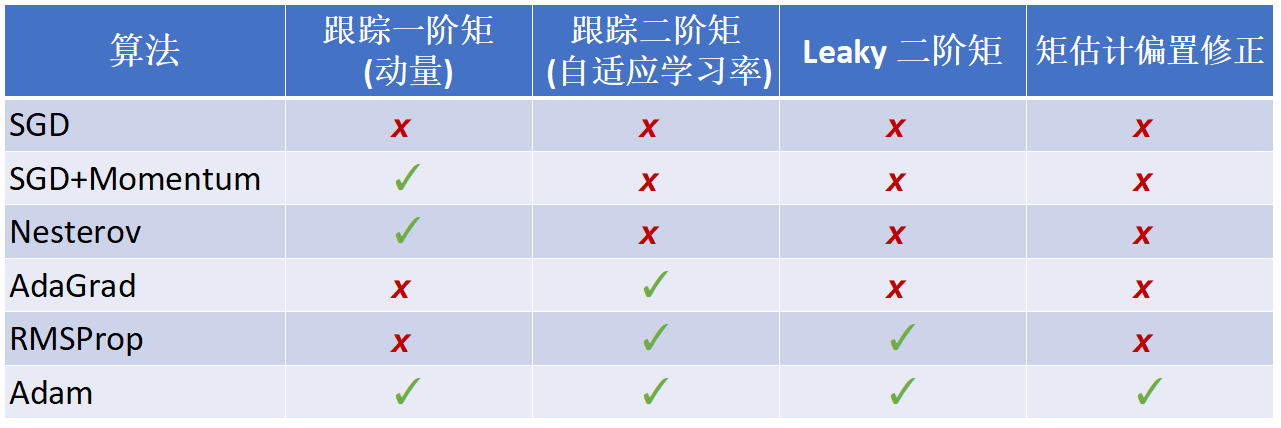
- Adam 在很多情况下都是不错的默认选择
- SGD+Momentum 可以优于Adam,但是需要更多的调整
- 如果你可以进行完整的批量更新,可以尝试使用 L-BFGS (不要忘记禁用所有噪声源)
二阶牛顿法难于计算不考.
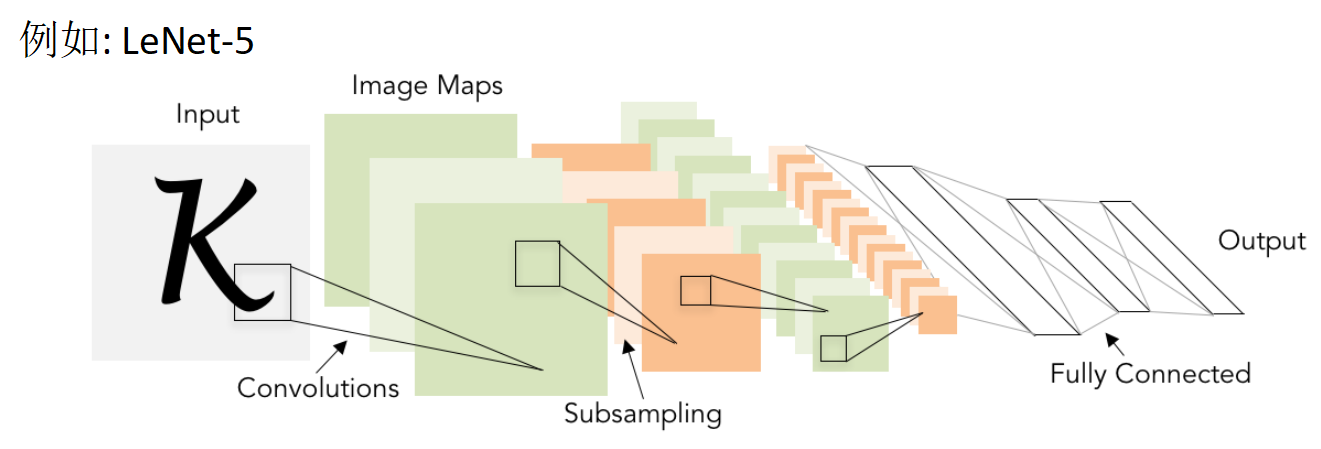
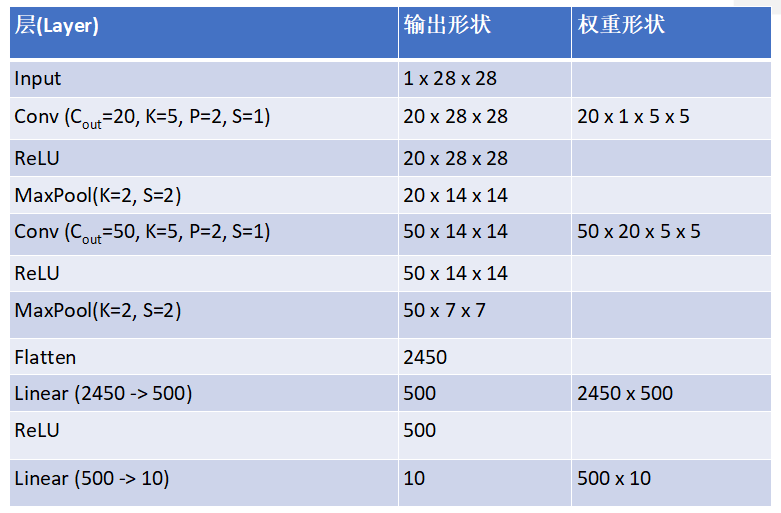
卷积神经网络 CNN
卷积的计算
卷积核加入填充(padding),步伐(stride)后计算输出结果的大小.

掌握例子:



1x1卷积:堆叠1x1卷积层等价于对每个位置进行 全连接层。

池化的原理
池化层: 另外一种下采样(downsmaple)方式,输出结果的大小:

RNN的经典架构
经典架构:[Conv, ReLU, Pool] x N, flatten, [FC, ReLU] x N, FC
[Conv, ReLU, Pool]:称为一个卷积块,由卷积层,非线性函数(ReLU)和池化层组成.
flatten:将卷积的输出图像 展平为一维向量.
[FC, ReLU]:全连接层(Full connect)与非线性函数(ReLU)构成的全连接块.
FC:最后用一个全连接层作为输出层.
归一化原理
批归一化(Batch Normalization)

前面一层的输出维度为 ,如果是图像 ,则可以将 展平后视为 , 表示 mini-batch的大小.
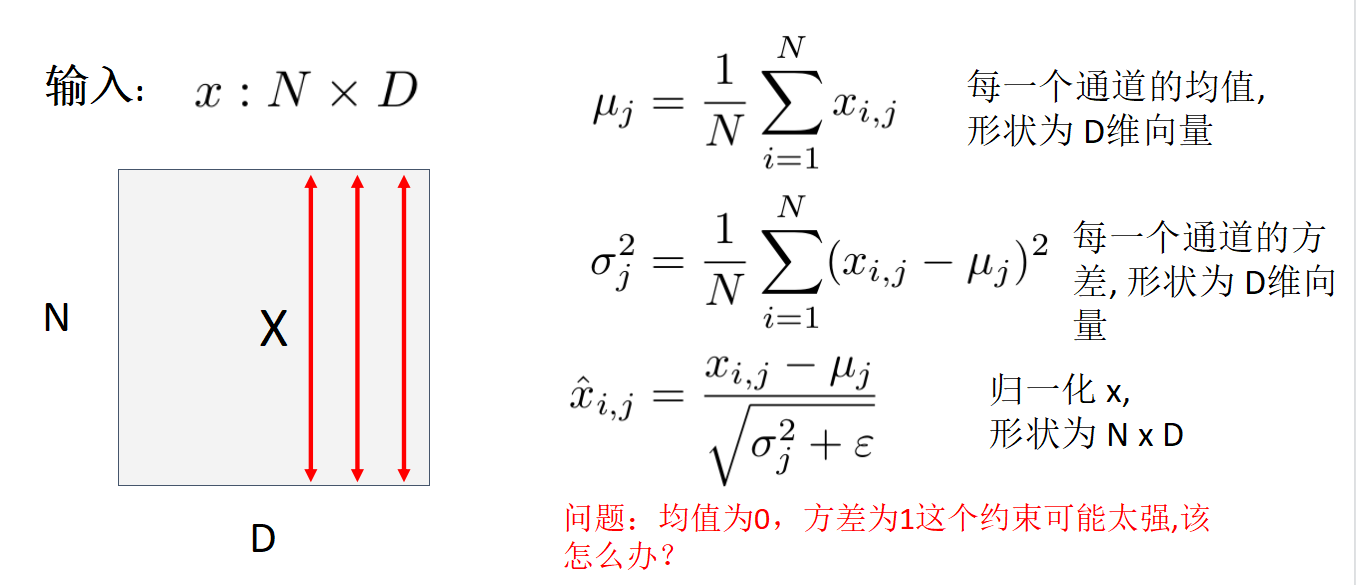

估计参数时依赖整个mini-batch的数据,但在测试时不能这样做! 所以在测试时需利用训练数据的平均值进行代替.


批归一化优点:
- 使得网络更加容易训练!
- 允许使用更大的学习率,使网络收敛速度加快;
- 网络对于不同初始化值更加鲁棒;
- 归一化在训练的过程中起到正则化的作用;
- 测试时零开销: 可以与卷积层融合!
批归一化缺点:
- 至今为止没有很好的理论上的解释;(仅能解释为减少“内部方差偏移”)
- 训练和测试上的操作行为不一致: 这是日常代码中一种常见的bug来源!
层归一化(Layer Normalization):

实例归一化(Instance Normalization):

CNN 网络结构
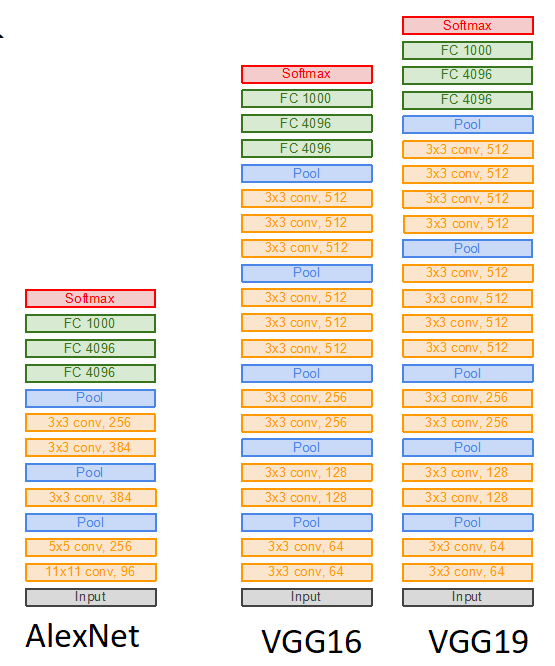
神经网络架构:AlexNet,VGG,GoogleNet,ResNet.
掌握道理,每个神经网络解决了什么问题?通过神经网络结构判别神经网络架构.
AlexNet
227 x 227 的输入,5 个卷积层,最大池化层,3 个全联接层,ReLU 非线性激活函数.
特点:
- 多数存储开销是在位置靠前的卷积层;
- 接近所有参数都在全联接层;
- 大多数浮点运算计算量出现在卷积层上.
VGG
VGG-16比AlexNet大得多!VGG 设计规则:
- 所有卷积层为 3x3 大小,stride为1,pad为1;
- 所有最大池化层为 2x2 大小,stride为2;
- 池化层后,通道数加倍.
GoogLeNet
GoogLeNet为了实现高效性的创新: 减少参数量,存储空间和计算量.
Stem network:在开始阶段积极地对输入进行下采样(回想在 VGG-16: 大多数计算集中在初始阶段)
Inception 模块:局部单元由多个分支组成,局部结构在网络中重复出现多次,使用 1x1 “Bottleneck” 来在卷积操作前减少通道数.
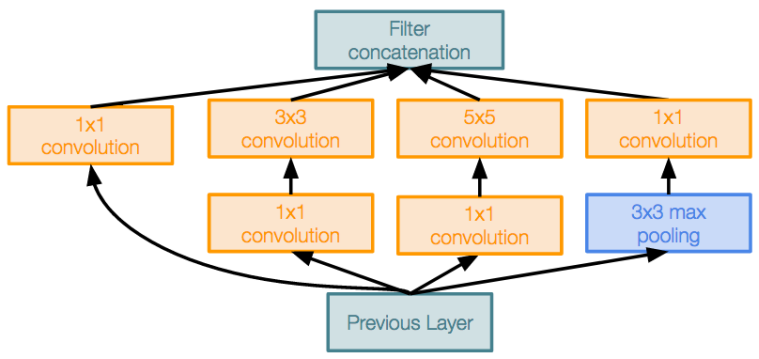
Global Average Pooling(全局均值池化层):不再在最后使用大型FC层! 改为使用 global average pooling 来进行维度压缩,并使用一个liner层计算分数.
Auxiliary Classifiers(辅助分类器):使用loss没有将网络的靠后位置训练好:网络太大了,梯度无法精准传播,使用“auxiliary classifiers” 在网络的几个中间节点来对图片分类和接收loss. 但是,使用 BatchNorm 就不需要这个技巧了.
ResNet 残差网络
Residual Networks(ResNet) 是从一个问题上发现的:更深的网络比前层网络表现差!事实上,深层网络表现的是欠拟合,因为其在训练集上的效果仍然比浅层网络差. 但是理论上深层神经网络可以通过恒等变换来模拟浅层网络,至少比浅层网络效果要好. 所以考虑加入快捷通道,直接让神经网络自动选择是否直接使用恒等变换(复制上一层的结果).
问题:更深的模型更难优化,而且实际中无法得到恒等变换(identity functions)来模拟浅层网络.
解决:改变网络结构使多余的层能够容易的利用 identity functions!
残差层(Residual Block):加入shortcut通道直接跨过卷积层. Residual network 是多个residual blocks的堆叠
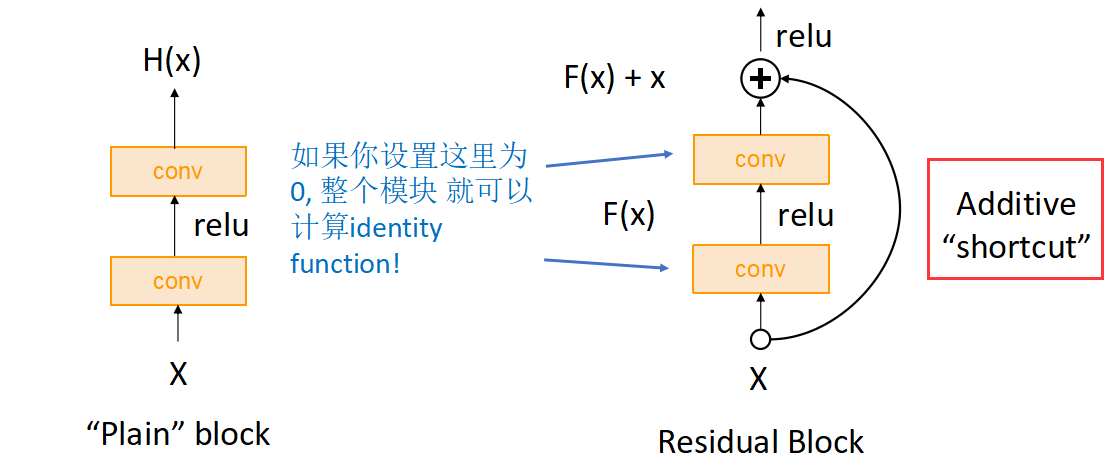
瓶颈模块(Bottleneck Block):通过 1x1 的卷积层,减少卷积计算量:

其他特点:
- 类似 GoogleNet 使用同样的 aggressive stem来在residual block;
- 类似 GoogLeNet, 没有大型全联接层: 而是在模型末端使用 global average pooling 和一个linear 层;
优点:
- 可以训练非常深的网络;
- 更深的网络表现比浅层网络好 (同预期中一样);
- 在所有 ILSVRC 和 COCO 2015 比赛获得第一名;
- 现在还是广泛应用!
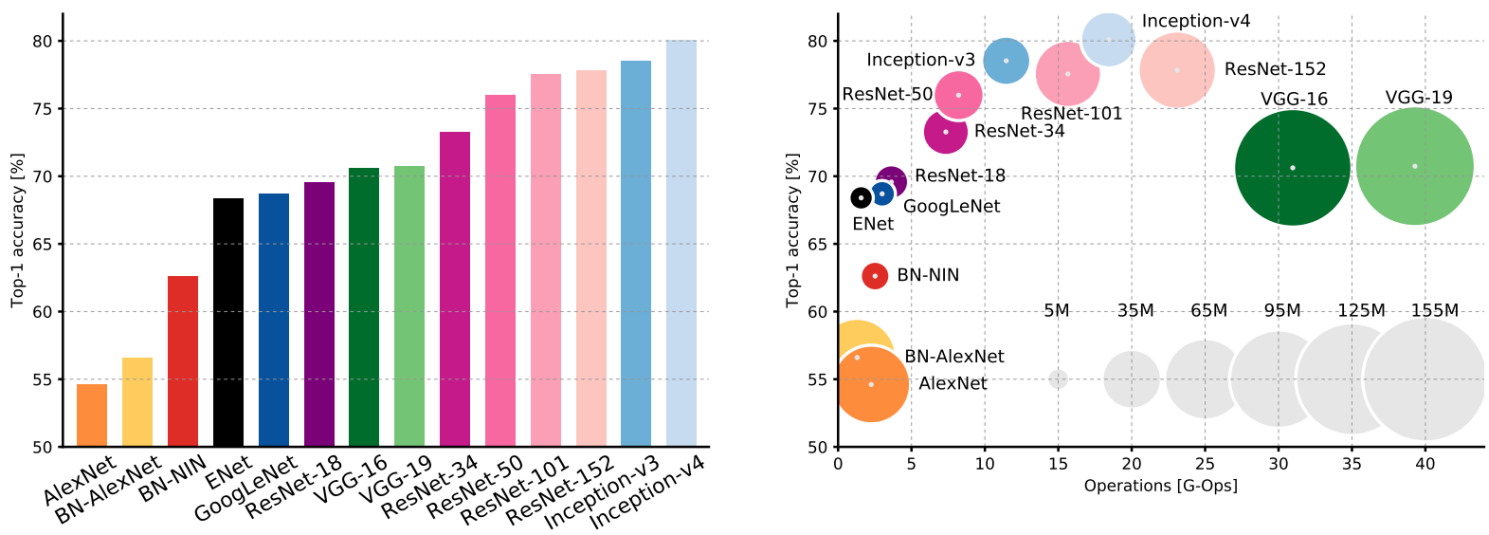
比赛总结:
- VGG: 最多的存储和计算量
- Inception-v4: Resnet + Inception:效果最好,利用Resnet加上Inceptio模块达到的.
- GoogLeNet: 非常高效!
- AlexNet: 低计算量, 高参数量.
- ResNet: 简单设计, 比较高效,高准确率.
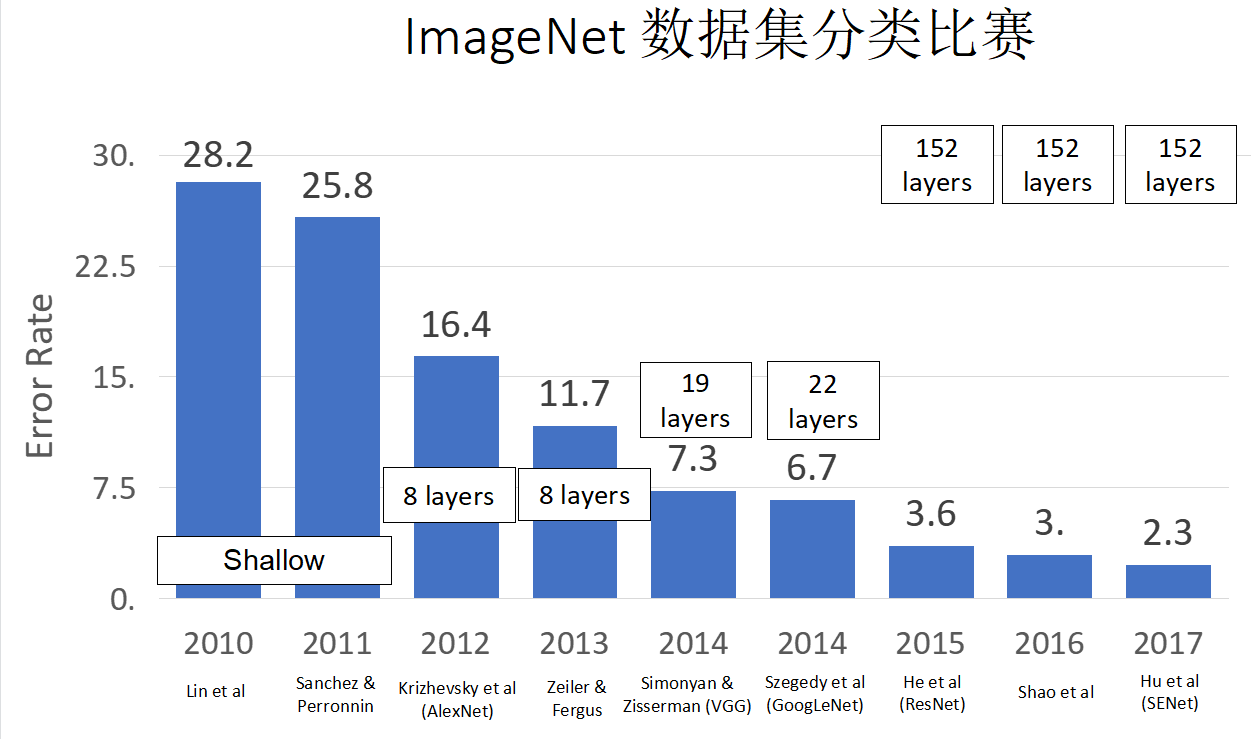
年度 ImageNet在2017后不再举办,改为Kaggle.
CNN Architectures 总结:
- 早期工作 (AlexNet -> ZFNet -> VGG) 表明更大的网络效果更好
- GoogLeNet 最开始关注于 efficiency (aggressive stem, 1x1 bottleneck convolutions, global avg pool 代替 FC layers)
- ResNet 告诉我们如何训练超大型网络– 被 GPU 的内存所限制!
- ResNet之后: Efficient networks 更加受重视: 我们应该如何在不增加复杂度的基础上提升准确率?
- 很多tiny networks 聚焦于移动设备: MobileNet, ShuffleNet, etc
- Neural Architecture Search 自动实现网络设计
网络使用建议:
- 如果非常在意精度,可以使用 ResNet-50 或者 ResNet-101;
- 如果想要一个高效网络(比如要求实时,或移动端运行) 可以尝试 MobileNets 或者 ShuffleNets.
开放性问题:根据题目条件选择网络结构.
人脸识别
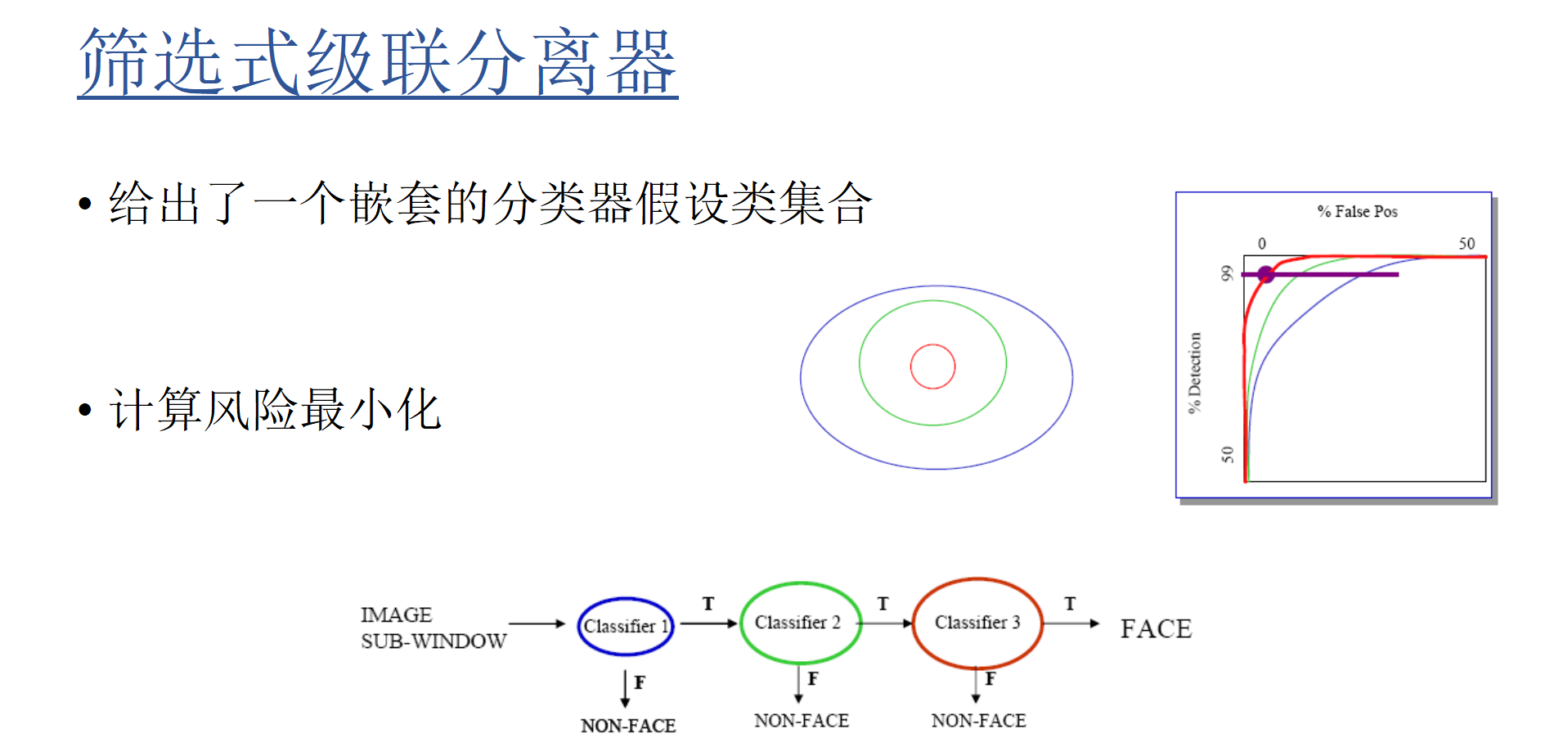
Viola-Jones人脸识别算法:
- 使用AdaBoost进行高效的特征选择
- 矩形特征+积分图像可以用于快速图像分析
- 快速分类产生级联分类器
灰度图像最快速已知人脸检测器,
Adaboost(Adaptive Boosting)
Adaboost算法关键点:
- 强(非线性)分类器是由所有弱(线性)分类器的组合构建的。
- 前一个错误分类的样本将在以后的轮次中得到更多的强调。

特征,积分图像


级联处理
把二个以上的设备通过某种方式连接起来,能起到扩容的效果就是级联。
语义分割
没啥想考的,理解对网络的要求

目标检测
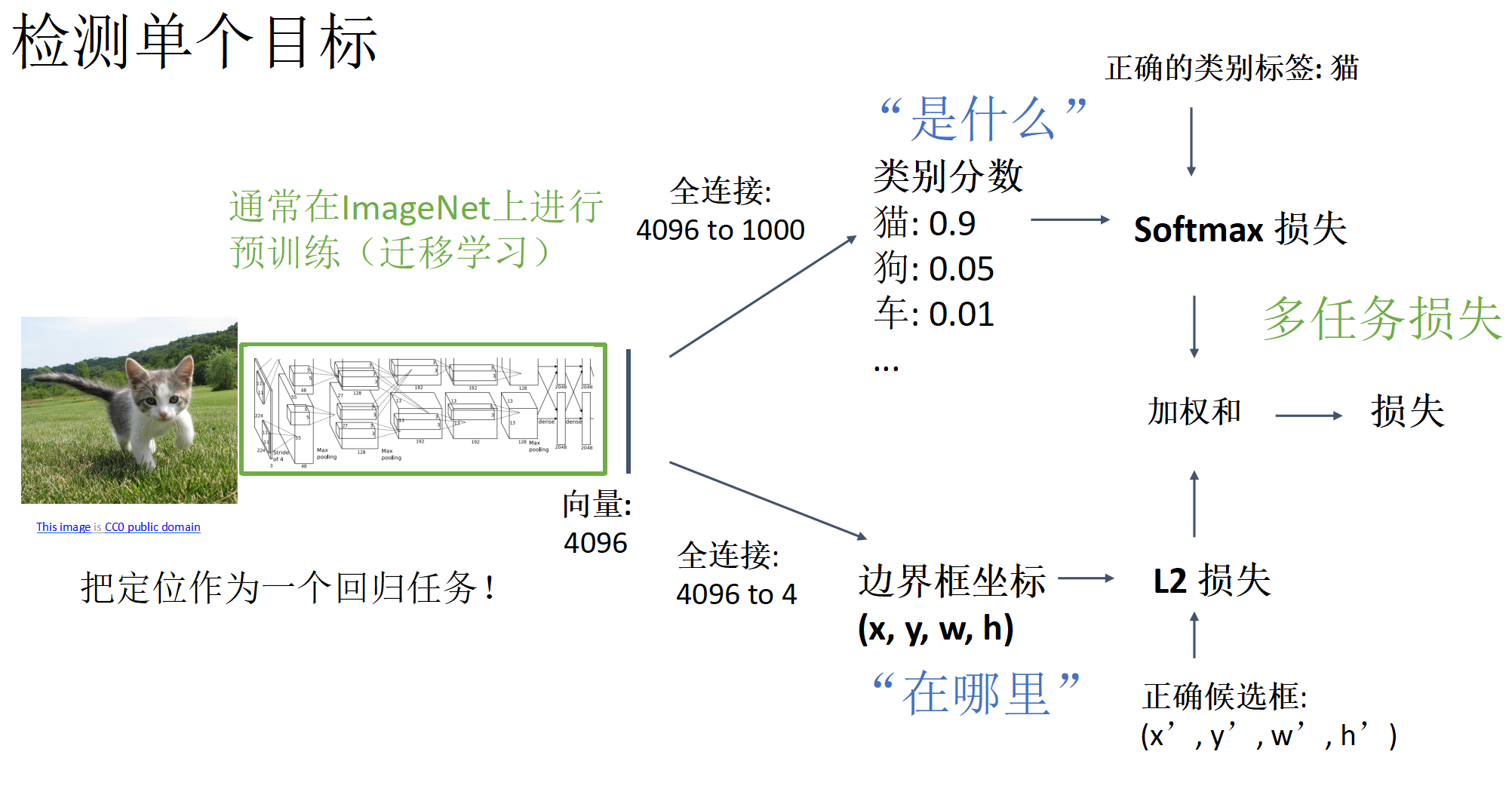
上述算法问题在于如果图中存在多个目标时,每张图片具有不同数量的输出值,难以处理.
滑动窗口
将 CNN 应用于图像的许多不同裁剪(滑动窗口裁剪结果),CNN 将每个裁剪分类为对象或背景.
提问:考虑边界框的大小为h×w,在大小为H×W的图像中有多少个可能的边界框?
位置x的可能性: W – w + ,位置y的可能性: H – h + 1,全部可能的位置: (W – w + 1) * (H – h + 1)
可能的边界总数:
遍历所有可能的区域太慢,所以需要生成候选区域:找到一小组的候选框尽可能地覆盖所有的目标对象;基于启发式:例如寻找类似斑点的图像区域;运行速度相对较快:例如在CPU上能几秒钟地选择性搜索出 2000 个候选区域.
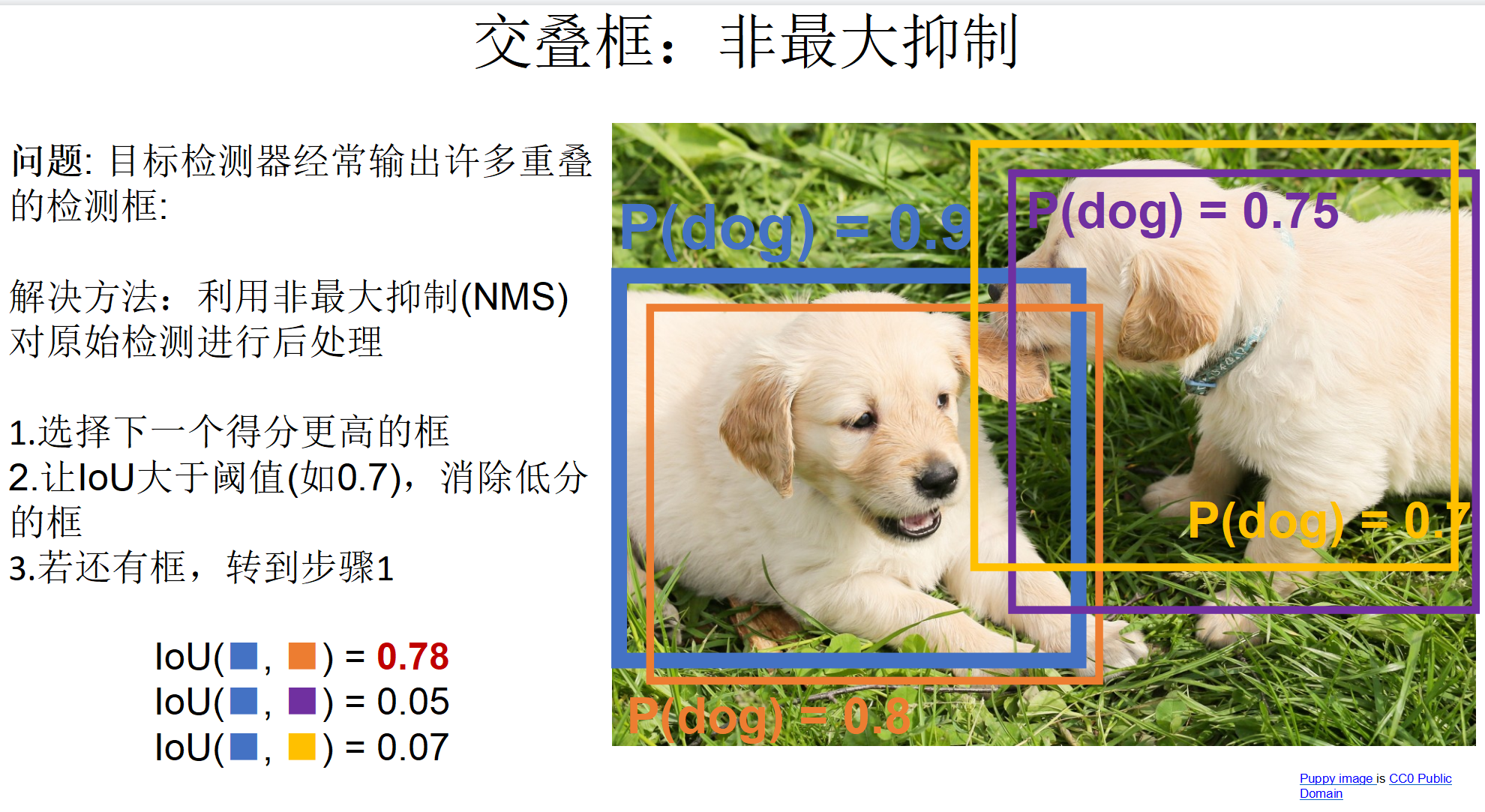
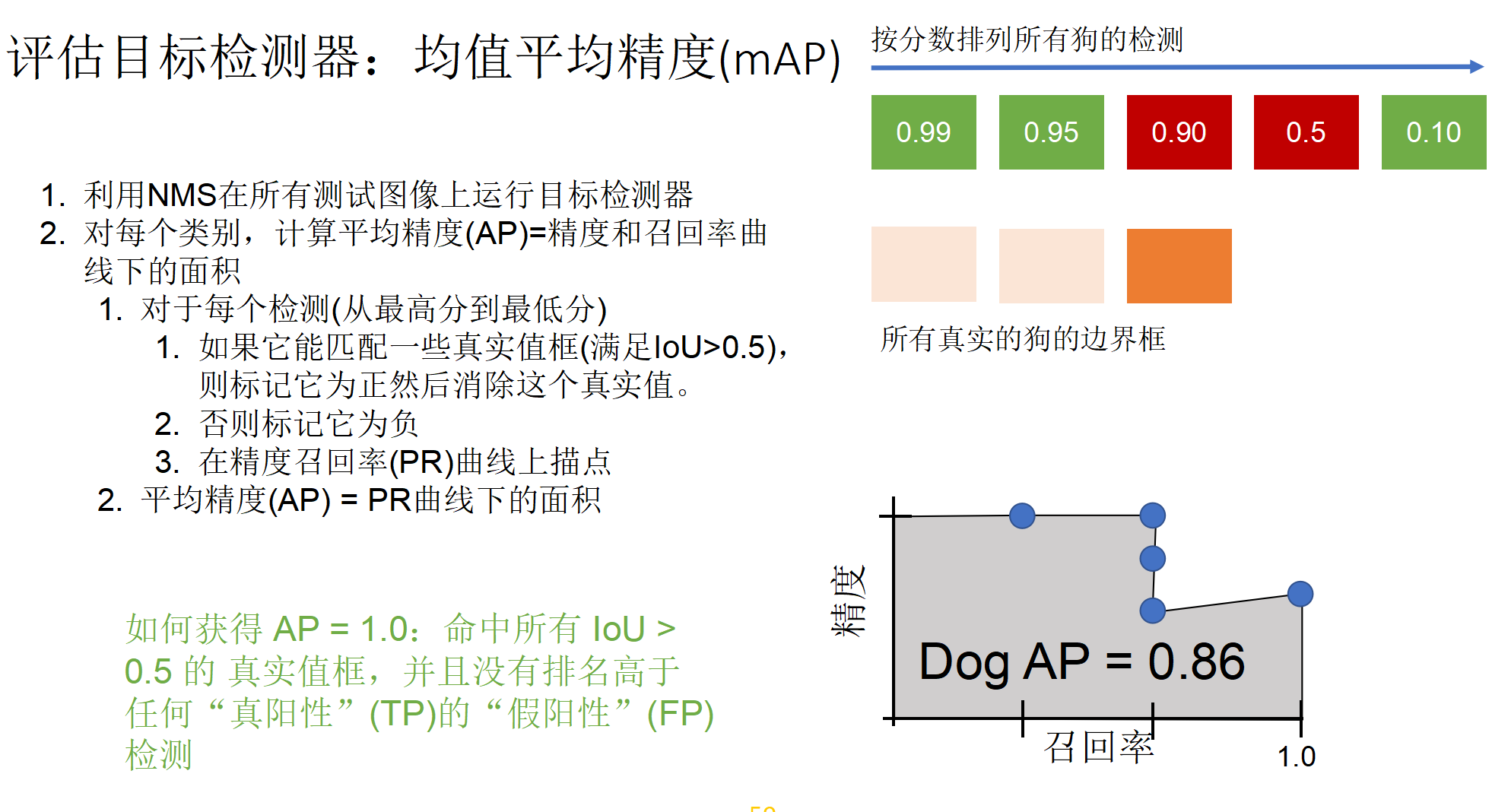
检测评估标准


R-CNN
R-CNN(Region-based CNN)是基于区域的CNN. 分为四种:
- “Slow” R-CNN: 每个区域独立通过CNN
- Fast R-CNN: 将可区分裁剪应用于共享的图像特征
- Faster R-CNN: 利用CNN来计算候选区域
- Single-Stage:全卷积检测器

深度学习:R-CNN,每个版本解决了什么问题(要非常清楚). 细节:计算IoU,NMS,AP,mAP原理.
Transformer
比较新,前沿知识,知道原理,问答题借鉴它的思路.