Inside TensorFlow - tf.keras 笔记
最新更新于: 2024年5月24日上午11点17分
学习视频:YouTube - Inside TensorFlow: tf.Keras (Part 1),YouTube - Inside TensorFlow: tf.Keras (Part 1),这两个视频中介绍了Keras的基本实现原理和每个类的自定义方法。
头文件:
import tensorflow as tf
import tensorflow.experimental.numpy as tnp
keras = tf.keras
layers = keras.layerskeras.layers.Layer
性质
Layer 本质上就是用于计算的容器,例如传统的层(全连接层、卷积层等)或者通过层堆叠得到的块(ResNet block, Inception block),其具有一下特点:
- 将一个batch的输入转化为一个batch的输出, 维度的输入对应 维度的输出,并且层的计算中每个样本之间都是独立的,两个样本无法进行交互。(例如batch normalize,但是layer normalize如何实现?)
- 支持eager execution和graph execution(用户自定义的层只能是eager的?)
- Layer支持两种模式,training mode和inference mode(第一个为训练模式,第二个为推理模型,后者一般用于做验证evaluate或预测predict)
- 支持masking(用于时间序列填充?)
- 包含可训练参数(在反向传播中对其进行更新)和不可训练参数(
trainable=True/False) - 可用于跟踪loss和metrics(损失和度量器)
- 可自动进行类型检查(静态模型推断检查,例如计算shape和参数个数)
- 可被冻结和解冻(frozen or unfrozen,冻结该层后参数不会在梯度更新中进行更新),用于微调模型(fine-tuning),或者用于迁移学习或GANs
- 可被序列化或反序列化(通过层的配置参数进行序列化?)
- 可保存或加载(权重信息)
- 可被用于构建网络中DGAs(有向无环图)的一部分
- 支持混合精度(Mixed precision,
tf.keras.mixed_precision.set_global_policy('mixed_float16'))
例子
1. 全链接
下面给出一个全连接层的例子,并对outputs和self.b跟踪了loss(返回一个列表,顺次表示每次加入self.add_loss()的值):
class Linear(layers.Layer):
def __init__(self, units=32, init_random=True, **kwargs):
super().__init__(**kwargs)
self.units = units # 输出的神经元个数
self.init_random = init_random # 是否进行随机初始化,使用特定的初值可用于调试该层的输出
def build(self, input_shape):
if self.init_random: # 用标准正态分布初始化权重
self.w = self.add_weight(shape=(input_shape[-1], self.units), initializer='random_normal', trainable=True, name='w')
self.b = self.add_weight(shape=(self.units,), initializer='random_normal', trainable=True, name='b')
else: # w初始化为全1,b初始化为全0
self.w = tf.Variable(tf.ones(shape=(input_shape[-1], self.units), dtype='float32'), trainable=True, name='w')
self.b = tf.Variable(tf.zeros(shape=(self.units,), dtype='float32'), trainable=True, name='b')
def call(self, inputs): # 在调用__call__时会调用自定义的call
outputs = tf.matmul(inputs, self.w) + self.b
self.add_loss(tf.reduce_sum(outputs)) # 记录当前层的loss,在第二次call时候会重置
self.add_loss(tf.reduce_sum(self.b))
return outputs
linear_layer = Linear(8, init_random=False, name='MyLinear')
x = tnp.ones(shape=(1,3))
y = linear_layer(x)
print(y) # tf.Tensor([[3. 3. 3. 3. 3. 3. 3. 3.]], shape=(1, 8), dtype=float32)
tf.print(linear_layer.losses) # [24, 0]
y = linear_layer(x)
tf.print(linear_layer.losses) # [24, 0]Layer中的loss在堆叠层中会递归的对每个父类Layer记录loss,见例子3. 层堆叠代码最后一行输出结果。因为model会记录其中所有层的loss,所以可以在GradientTape中计算loss前计算sum(model.losses)(见例子4. 端到端),从而求出当前 ,也就是正则化项,使用方法见Model 例1. 层堆叠。(其他作用:weight triggerization 权重触发, KL divergence 计算KL散度)
注意:如果自定义层中加入了
add_loss,那么如果使用fit进行拟合时,则会将中间层add_loss都加到最终显示的loss当中。(Important)
自定义层中的参数一定要写name,否则无法保存模型model.save(), model.save_weight()
这里的实例化后的执行顺序是:先进行类初始化 __init__,当调用linear_layer时,如果是第一次执行,则会调用 build 对根据当前输入进行参数初始化,最后调用 call 返回该层的输出。
我们可以通过 linear_layer.trainable_weights 将该层全部可训练参数以列表的形式输出出来,在该层进行过 build 之后才会有可训练参数哦(linear_layer.trainable_variables 结果相同)
[<tf.Variable 'MyLinear/Variable:0' shape=(3, 32) dtype=float32, numpy=
array([[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]],
dtype=float32)>,
<tf.Variable 'MyLinear/Variable:0' shape=(32,) dtype=float32, numpy=
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
dtype=float32)>]2. 层求和,层均值
下面给出一个包含不可训练参数层的写法:
# 用于记录当前输入的层参数和total,层均值mean(对样本本进行平均),输出与输入相同
# 类似层归一化 layer normalize
class ComputeSum(layers.Layer):
def __init__(self, input_dim, **kwargs): # 也可以不写build方法,直接在init中初始化参数
super().__init__(**kwargs)
self.input_dim = input_dim
self.total = tf.Variable(tf.zeros(self.input_dim), dtype='float32', trainable=False)
self.mean = tf.Variable(tf.zeros(self.input_dim), dtype='float32', trainable=False)
self.count = tf.Variable(0, dtype='int32', trainable=False) # 记录总样本
def call(self, inputs):
self.total.assign_add(tf.reduce_sum(inputs, axis=0))
# 这个写法在模型中是不可取得,因为batch size不能直接通过shape[0]获取,具体写法还待研究
self.count.assign_add(tf.shape(inputs)[0])
self.mean.assign(self.total / tf.cast(self.count, dtype='float32'))
return inputs
x = tf.ones(shape=(2, 3), dtype='float32')
sum_layer = ComputeSum(3, name='SumLayer')
y = sum_layer(x)
tf.print(sum_layer.total, sum_layer.mean) # [2 2 2] [1 1 1]
y = sum_layer(x)
tf.print(sum_layer.total, sum_layer.mean) # [4 4 4] [1 1 1]3. 层堆叠
Layer的嵌套,例如卷积块,多层感知机堆叠(MLP Block)
class MLPBlock(layers.Layer): # 多层感知机模块
def __init__(self, init_random=True, **kwargs):
super().__init__(**kwargs)
self.linear_1 = Linear(32, init_random=init_random)
self.linear_2 = Linear(32, init_random=init_random)
self.linear_3 = Linear(1, init_random=init_random)
def call(self, inputs):
x = self.linear_1(inputs); x = tf.nn.relu(x)
x = self.linear_2(x); x = tf.nn.relu(x)
return self.linear_3(x)
mlp = MLPBlock(init_random=False)
y = mlp(tf.ones(shape=(1, 3)))
print(y) # 3072 = 3 * 32 * 32
tf.print(mlp.losses) # [96, 0, 3072, 0, 3072, 0] 返回了每个内部的层中的loss记录值4. 端到端应用
在Boston房价数据集上进行简单测试。
(train_X, train_y), (eval_X, eval_y) = tf.keras.datasets.boston_housing.load_data()
std_scaler = StandardScaler() # 数据集标准化
train_X = std_scaler.fit_transform(train_X)
eval_X = std_scaler.transform(eval_X)
model = MLPBlock(init_random=True) # 用多层感知机
loss_fn = tf.keras.losses.MeanSquaredError() # MSE损失函数
optimizer = tf.keras.optimizers.Adam() # 优化器
metric = tf.metrics.Mean() # 对loss的均值度量器,每个epoch计算显示一次结果
for epoch in range(5):
metric.reset_state()
for x, y in tqdm(zip(train_X, train_y)):
with tf.GradientTape() as tape:
logits = model(tf.expand_dims(x, axis=0))
loss = loss_fn(y, logits)
# 这里可以得到全部层的loss,如果我们每个层输出是self.w,那么就可以做正则化操作
weight_regular = sum(model.losses)
grads = tape.gradient(loss, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
metric.update_state(loss)
print(f"epoch: {epoch}, loss: {metric.result()}")5. 序列化(serializable)
模型的序列化是指,可以将对象转化为可存储或传输所用的格式,也就是通过模型的序列化重新序列化获得该实例(序列化不包含参数,只是每个层的神经元个数,超参数)
在例1. 全链接的基础上加入get_config()函数,并使其返回加入自定义超参数的config。
class Linear(layers.Layer):
def __init__(self, units=32, init_random=True, **kwargs):
super().__init__(**kwargs)
self.units = units
self.init_random = init_random
def build(self, input_shape):
...
def call(self, inputs):
...
def get_config(self):
config = super().get_config()
config.update({'units': self.units, 'init_random': self.init_random}) # 加入在__init__中加入的超参数
return config
linear_layer = Linear(8, init_random=False, name='MyLinear')
config = linear_layer.get_config()
print(config) # {'name': 'MyLinear', 'trainable': True, 'dtype': 'float32', 'units': 8, 'init_randdom': False}
new_layer = Linear.from_config(config)
print(new_layer.get_config()) # same as linear_layer可以看出,config就是一个字典,向其中加入在 __init__ 中自定义的初始化参数即可。
6. Batch Normalize
在批归一化中,需要判断当前模型是处于那个阶段(training mode/inference mode),训练还是预测,可以通过 call 函数中 training 来判断:
class BatchNormalization(layers.Layer):
def build(self, input_shape):
dim = input_shape[-1]
self.gamma = tf.Variable(tf.ones(shape=(dim,)), trainable=True)
self.beta = tf.Variable(tf.zeros(shape=(dim,)), trainable=True)
self.var = tf.Variable(tf.ones(shape=(dim,)), trainable=False)
self.mean = tf.Variable(tf.zeros(shape=(dim,)), trainable=False)
self.EPS = tf.constant(1e-9)
def call(self, inputs, training=False):
if training:
# 如果是NxD维,则均值方差维度为1xD
# 如果是NxHxWxC维,则均值方差维度为1x1x1xC=1xC
mean, var = tf.nn.moments(inputs, axes=[i for i in range(inputs.shape.rank-1)])
normalized = (inputs - mean) / (var + self.EPS)
# 加入动量信息,alpha=0.9,并将当前速度缩放0.1倍
self.var.assign(self.var * 0.9 + var * 0.1)
self.mean.assign(self.mean * 0.9 + mean * 0.1)
else:
normalized = (inputs - self.mean) / (self.var + self.EPS)
return self.gamma * normalized + self.beta
batch_normal = BatchNormalization()
x = tf.Variable([[1,2,3],[3,2,1]], dtype='float32')
y = batch_normal(x, training=True)
tf.print(y) # [[-1 0 1], [1 0 -1]]
tf.print(batch_normal.mean, batch_normal.var) # [0.2 0.2 0.2] [1 0.9 1]
x = tf.Variable([[1,2,3],[3,2,1]], dtype='float32')
y = batch_normal(x, training=False) # 默认training=False
tf.print(y) # [[0.8 2 2.8], [2.8 2 0.8]]keras.Model
keras.Model 包含 Layer 类的全部功能,在此基础上还有 .fit, .predict, .evaluate, .compile 等方法,使用 model.fit 前先要通过 model.compile 配置模型的超参数,包含:优化器、损失函数、度量器等。
性质
Model 一般指文献中的模型(model)或者网络(network),Model 包含所有 Layer 的功能,并且有以下额外功能:
- 训练:
.compile(), .fit(), .evaluate(), .predict() - 保存:
.save()包含拓扑(topology)形式的网络结构,模型状态(weights),优化器(optimizer)及其参数 - 模型摘要、可视化:
.summary(), keras.utils.plot_model()
graph execution & eager excution
在TF2中,如果调用 model.fit(), model.compile(),TF2将默认使用图执行方法对模型进行搭建和训练(更快),如果想立即执行模型(eagerly mode指想python代码一样,run step by step,更容易调试?)则需要使用 model.compile(..., run_eagerly=True)。
而如果自己要实现TensorFlow的梯度下降,那么就需要用到 @tf.function
例子
1. 层堆叠
以下是将Layer 例3 层堆叠简单改写得到 Model 类:
class Linear(layers.Layer):
def __init__(self, units=32, init_random=True, **kwargs):
...
def build(self, input_shape):
...
def call(self, inputs):
outputs = tf.matmul(inputs, self.w) + self.b
self.add_loss(tf.reduce_sum(self.w) * 1e-2) # 加上L1正则项
return outputs
class MLP(keras.Model): # 只需将layers.Layer改成keras.Model即可
def __init__(self, init_random=True, **kwargs):
super().__init__(**kwargs)
self.linear_1 = Linear(32, init_random=init_random)
self.linear_2 = Linear(32, init_random=init_random)
self.linear_3 = Linear(1, init_random=init_random)
def call(self, inputs):
x = self.linear_1(inputs); x = tf.nn.relu(x)
x = self.linear_2(x); x = tf.nn.relu(x)
return self.linear_3(x)
train_ds = tf.data.Dataset.from_tensor_slices((train_X, train_y)).batch(1)
mlp = MLP(name='MLP', init_random=True)
mlp.compile(optimizer=keras.optimizers.Adam(), loss=keras.losses.MeanSquaredError())
mlp.fit(train_ds, epochs=10)这里的 Linear 类中加入了 正则项 ,可以减弱过拟合。
如果使用手写实现梯度下降细节,处理相同的数据,速度会慢很多,终归还是因为每次从
train_ds中提取数据的for循环太慢
2. 模型保存与载入
在保证模型的参数都命名后,可以使用以下两种方式保存模型:
-
model.save(path):将完整模型保存到path对应的文件夹下,并保留所有的参数,包括优化器的状态(保存的详细内容) -
load_model = tf.keras.models.load_model(path):加载模型。 -
model.save_weight(fname):将模型的权重保存到文件fname下,包含三个文件checkpoint:记录最新的权重是哪个*.data-00000-of-00001:权重文件*.index:索引文件
其中第一个是每次更新权重时会覆盖掉,后面两个是权重的必要文件。(后面可以用fit中cellback参数,在每个epoch结束时,保存最新的权重)
Functional API 函数式构建模型
这是一种能够绘制出模型结构图的模型搭建方式,两个函数之间的调用相当于是在两个模块之间链接一条有向边,从而可以搭建出一个有向无环图。并且自动生成模型的序列化参数,可以通过 model.get_config() 获取。
性质
- 用于绘制层之间关系图(DAG)的API
- 让人容易理解层之间的关系,但是如果是开发者,可以不使用该构建方法
- 无需编写任何函数,只需执行API调用(接口创建),所有具体计算都在API内部实现
- 不容易出错,因为在构建图的过程中,已经自动检测了层之间是否可以连接,并且可以通过输出模型结构图进行简单debug
特点:易于检查(在建图过程中就进行DEBUG),可绘制(通过 keras.utils.plot_model() 绘制模型结构),直接序列化(通过 model.get_config())
DAG图中每个节点具体是由三元组构成:(layer, node_index, tensor_index),其中
layer:当前层所属的类node_index:当前层实例化后的节点编号tensor_index:输入与输出tensor的信息,例如shape大小
例子1
inputs = layers.Input(shape=(784,), name='Image')
x = layers.Dense(64, activation='relu', name='Dense1')(inputs)
x = layers.Dense(64, activation='relu', name='Dense2')(x)
outputs = layers.Dense(10, activation='softmax', name='Output')(x)
model = keras.Model(inputs, outputs, name='Test Model')
save_json("test.json", model.get_config()) # 模型序列化结果为dir,可转成json文件保存下来
keras.utils.plot_model(model, show_shapes=True) # 并且可以绘制模型结构图
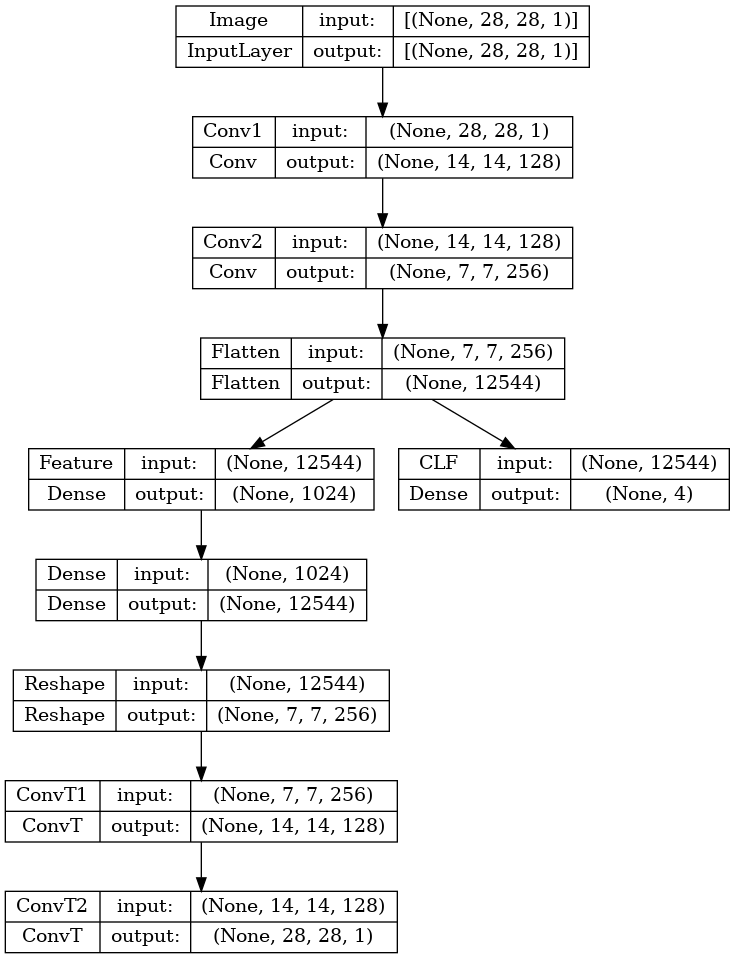
rebuild_model = keras.Model.from_config(model.get_config()) # 可通过Model.from_config重建,类似Layer.from_config进行重建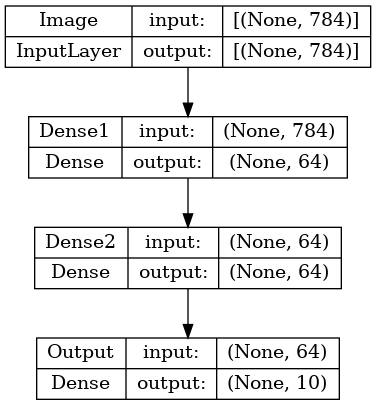
例子2
稍微复杂一点的例子如下(uNet,加上一个分类功能)
class Conv(layers.Conv2D):
def __init__(self, idx, **kwargs):
kwargs.update({'name': f"Conv{idx}", 'activation': 'relu'})
super().__init__(**kwargs)
class ConvT(layers.Conv2DTranspose):
def __init__(self, idx, **kwargs):
kwargs.update({'name': f"ConvT{idx}", 'activation': 'relu'})
super().__init__(**kwargs)
inputs = layers.Input(shape=(28,28,1), name='Image')
x = Conv(idx=1, filters=128, kernel_size=2, strides=2)(inputs)
x = Conv(idx=2, filters=256, kernel_size=2, strides=2)(x)
x = layers.Flatten(name='Flatten')(x)
outputs1 = layers.Dense(units=4, activation='softmax', name='CLF')(x)
feature = layers.Dense(units=1024, activation='relu', name='Feature')(x)
x = layers.Dense(units=7*7*256, activation='relu', name='Dense')(feature)
x = layers.Reshape(target_shape=(7,7,256), name='Reshape')(x)
x = ConvT(idx=1, filters=128, kernel_size=2, strides=2)(x)
img = ConvT(idx=2, filters=1, kernel_size=2, strides=2)(x)
model = keras.Model(inputs, (x, outputs1))
keras.utils.plot_model(model, show_shapes=True)