YOLOv4 笔记
最新更新于: 2024年5月24日上午11点17分
参考文献:
- YOLOv4: Optimal Speed and Accuracy of Object Detection
其中结论得到的最优模型用到的所有优化:
- CIOU, DIOU:基于IOU给出了两个损失,其中CIOU作为边界框位置的损失,DIOU为NMS新的度量标准。
- CSPNet:一种简单的对Backbone中ResBlock层进行优化的trick,可以大幅减少模型参数,同时具有稳定的泛化能力。
- SPP: Spatial Pyramid Pooling:一种用maxpool进行特征提取的trick,在Neck块开始时使用。
- PANet:一种特征聚合的方法,使用了两次特征金字塔。
YOLOv4模型部分代码用JAX实现,数据读取及增强部分由PyTorch和Albumentations实现
YOLOv4概述
YOLOv4在YOLOv3的基础上,对各种细节进行了优化调整,从而在保持推断速度的前提下(96fps)将COCO-AP提升到41.2%(YOLOv3为28.2%),而且模型大小还减少了20MB。
YOLOv4首先将整个目标识别模型划分为了三个部分:
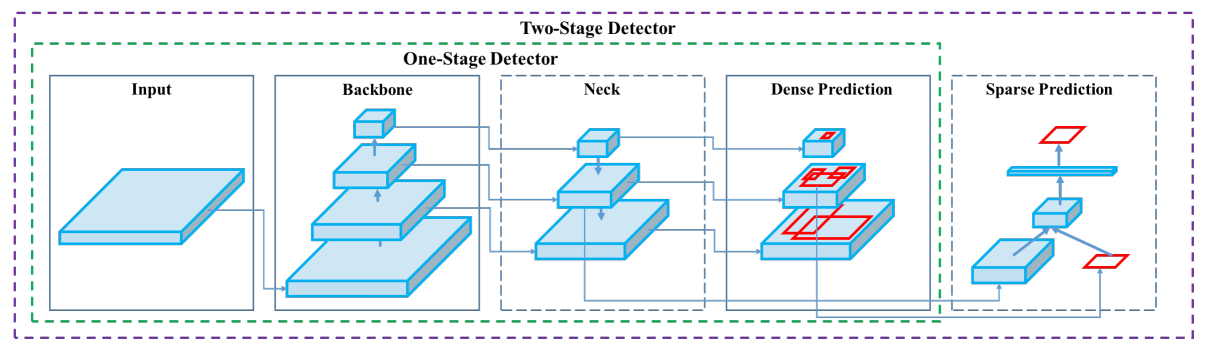
我们只考虑一阶段识别器(YOLO类型的),二阶段识别器是R-CNN之类的速度很慢。三个部分分别为:
- Backbone(主干):指对图像的特征进行提取的部分,例如:VGG16, ResNet, DarkNet等,对于一般任务是在Imagenet53上先进行预训练,用于初始化模型权重。
- Neck(特征聚合):指对提取出的图像特征进行进一步聚合,一般操作是利用不同尺度上的特征信息进行合并(特征金字塔),例如FPN, PANet等,使用多种不同maxpool的SPP方法也是一种特征聚合的trick。
- Head(预测):在上图中指的是Dense Prediction,但实际并没有用到全连接层,因为我们的模型仍然是FCN(Fully Convolutional Network),这部分是指模型预测所用到的指标:例如YOLO, SSD等。
论文对每个模块进行非常多不同的尝试,做消融实验,最后组合出来才得到最后YOLOv4模型,下面我们只对最终的最优组合细节进行介绍。
Backbone
CSPNet
论文CSPNet: A New Backbone that can Enhance Learning Capability of CNN,就是一种增强CNN泛化能力的同时,见效模型参数的trick。实现非常简单,如下图所示:
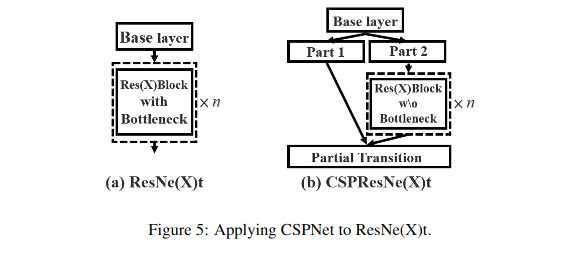
假设ResBlock输入的通道数为 ,那么首先我们用一个1x1Conv构建一个旁路(route),通道数为 ,然后再用一个1x1Conv构建一个主路通道数为 ,主路直接走过ResBlock,再将输出的结果直接和旁路保存的特征进行堆叠,就得到了一个通道数为 的特征。这样的优势在于可以接近减少一般的模型大小,同时增强学习能力。详细架构如下图所示:
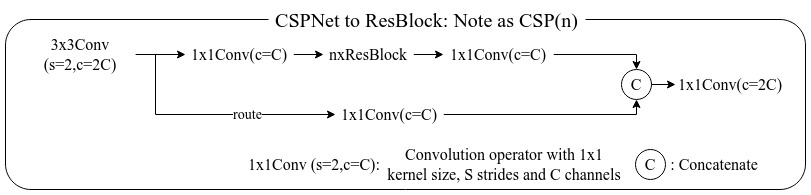
x = input
route = conv(filters=x.shape[-1]//2, kernel=(1,1))(x)
x = conv(filters=x.shape[-1]//2, kernel=(1,1))(x)
for _ in range(resblock_size):
x = resblock()(x)
x = conv(filters=x.shape[-1], kernel=(1,1))(x)
x = jnp.concatenate([x, route], axis=-1)
x = conv(filters=x.shape[-1], kernel=(1,1))(x) # Fusion the featureDarkNet53 & Mish
沿用YOLOv3中的DarkNet53,图像的按照2的倍数缩小5个尺度,每个尺度的ResBlock数目分别为 ,可参考/posts/50137/#darknet-53。
这里使用了一个称为SOTA的激活函数Mish,定义如下
和RELU很像,但他能保持梯度不消失时,缺点是由于加入了 训练速度会下降,其和激活函数对比的图像如下:
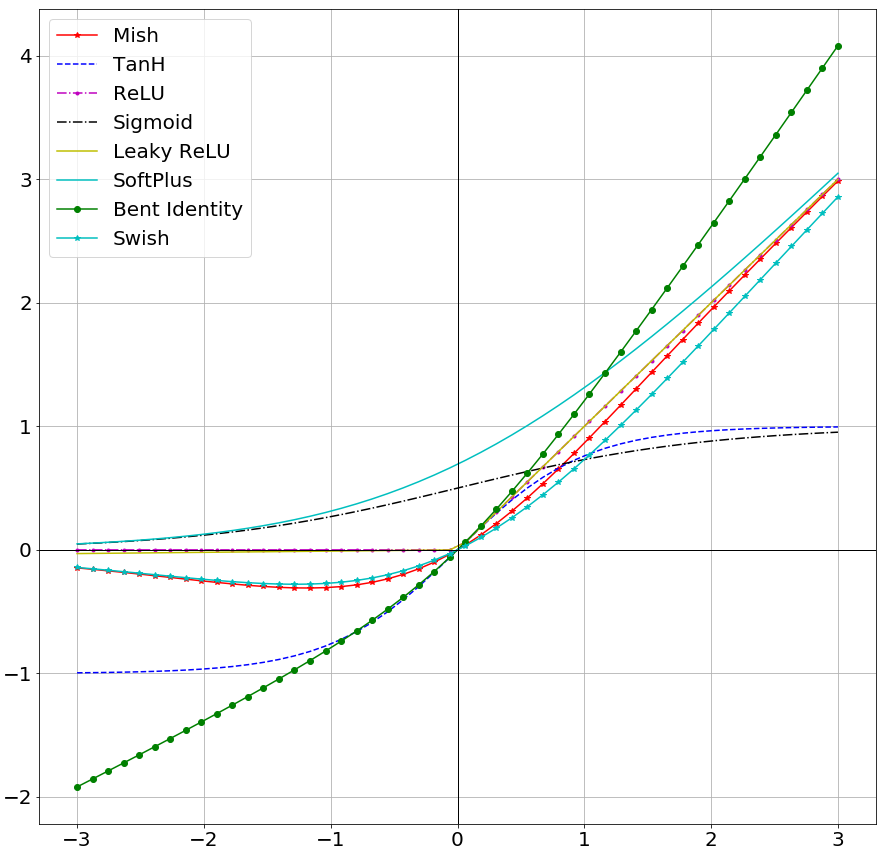
总结
将DarkNet53中的所有ResBlock中加入CSP,再将激活函数改成Mish,称之为CSP-DarkNet53,模型总参数26Millons,实际大小为110.6MB,而DarkNet53的大小为160MB。并且CSP-DarkNet53在Imagenet2012上最终训练结果为top-1=76.55%,top-5=93.16%,均优于DarkNet53的75%和92.6%。wandb-产看训练图像对比
Neck
PANet
YOLOv4将YOLOv3所使用的特征金字塔(FPN)改进为PANet,结构如下所示:
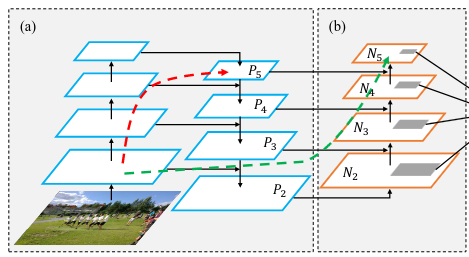
上图中(a)就是一次特征金字塔,将提取到的特征进行重新上采样,并对之前相同尺度处的特征进行合并得到,(b)就是对第一次得到的特征金字塔再做一次特征金字塔,这样的好处在于,第二次特征金字塔的同尺度图像对原图像特征保留更完整,以P5和N5为例,P5所提取的图像特征经过了整个Backbone对原始图像的低维特征信息较少,但是N5可以通过绿色的快捷通道可以更快的得到原始图像的低维尺度信息,从而相对较好一些。
当然这些都不靠谱,还是要靠实验结果说话,更复杂的链接方式还有Bi-FPN,可能链接过于复杂,导致速度太慢,所以不建议使用。
SPP
SPP本质上就是一个对图像的特征按照3个不同的maxpool窗口大小进行特征提取,再将提取出的特征进行堆叠得到的,原论文是为了要将不同尺度的特征输入保持相同的输出输出,所以还进行了不同的步长设定。但是在YOLOv4中,其中的SPP就是指:直接对特征做步长为1的不同窗口大小的maxpool操作,在进行堆叠即可。
class SPP(nn.Module): # Spatial Pyramid Pooling
@nn.compact
def __call__(self, x):
x5 = nn.max_pool(x, (5,5), padding="SAME")
x9 = nn.max_pool(x, (9,9), padding="SAME")
x13 = nn.max_pool(x, (13,13), padding="SAME")
x = jnp.concatenate([x, x5, x9, x13], axis=-1)
return x总结
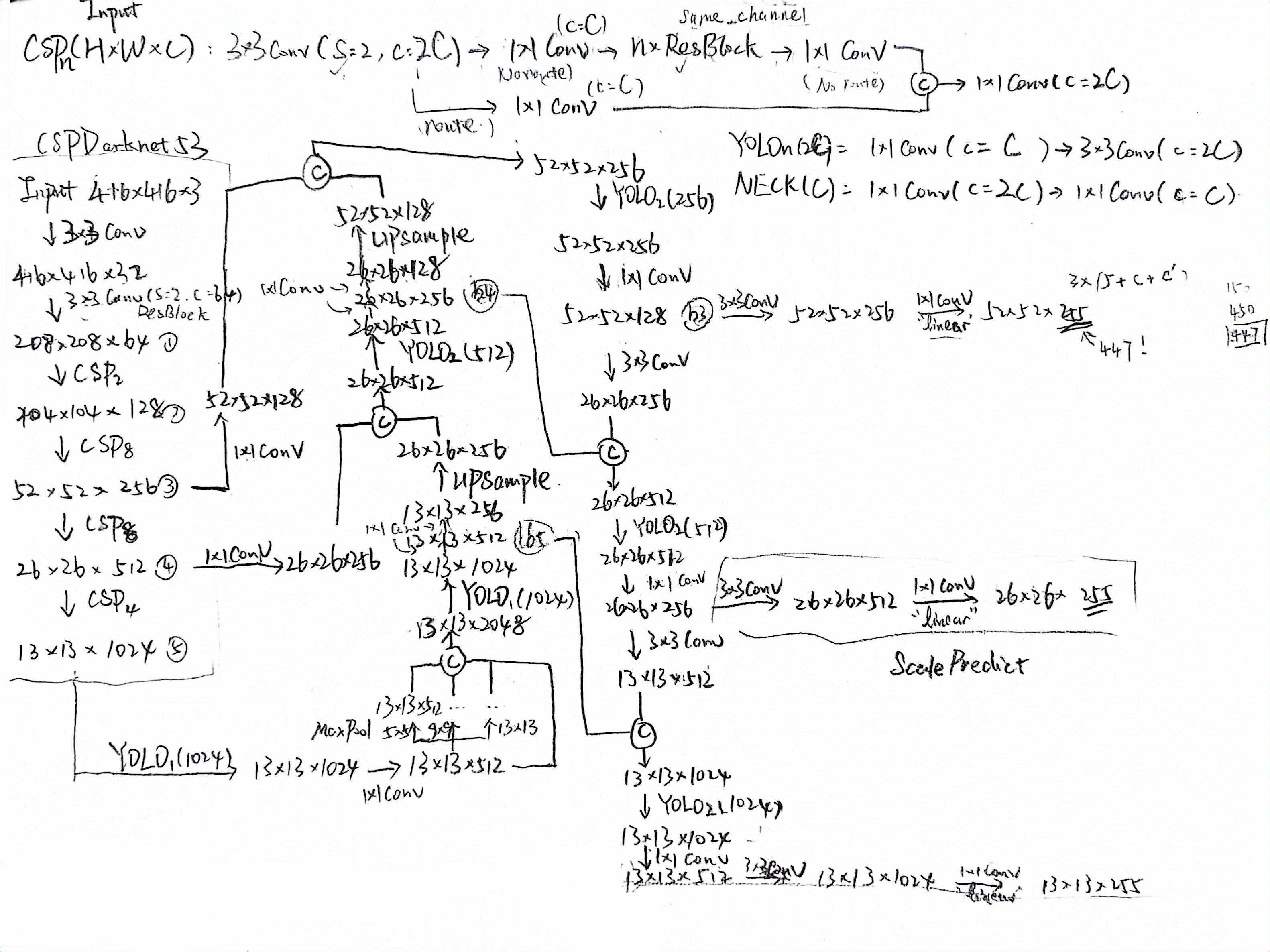
参考了pytorch-YOLOv4 model.py的代码,我将模型架构绘制如下(JAX实现):
Head
DIOU, CIOU
DIOU(Distance-IOU)和CIOU(Complete-IOU)分别是加入距离属性的IOU和带有正则项的IOU损失。
DIOU
设 为目标边界框( 表示ground truth), 为我们预测出的边界框,如果我们直接将 作为IOU损失对b进行更新,那么当 和 无交的时候,则不会对 进行更新,所以非常不好。
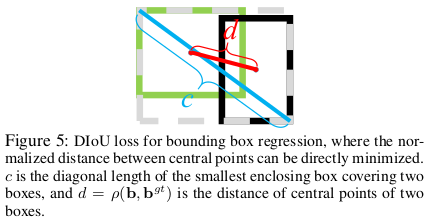
DIOU就是为了解决两者无交问题,所以直接引入了一项和边界框中心点相对位置相关的项,假设 分别表示 的中心点坐标,则:
其中 表示两个矩阵的最大对角线长度(用一个矩形恰好将两个框同时覆盖时,其对角线长度),可以用下图进行理解:
DIOU还可以作为NMS的衡量标准,原来的NMS是当两个边界框的IOU值大于某个阈值时,消去低置信度的框;而如果使用DIOU,则直接用 替换掉原有的 即可。
CIOU
CIOU就是在DIOU的基础上,加入了关于边界框长宽比的正则项,以便能加快收敛,令长宽比二范数损失及正则项系数分别为:
为归一化系数,保持 。正则项系数含义在于,如果两个框IOU接近时,我们更考虑将二者的长宽比弄成一致的,综上,CIOU定义为:
预测目标
YOLOv4的预测目标和YOLO系列保持一致,首先还是分为三个不、即 ,其中 表示坐标相对当前网格的
YOLOv4的损失其实论文中根本都没有写出,其就是将边界框的损失从二元交叉熵(xy)和二范数(wh),改成了CIOU损失,并且将wh从指数变化转为(参考scale-YOLOv4)
这样就使得 ,相比 可以实现更快速的收敛,可视化了一下COCO和PASCAL VOC中target的宽度和高度,结果如下图所示:
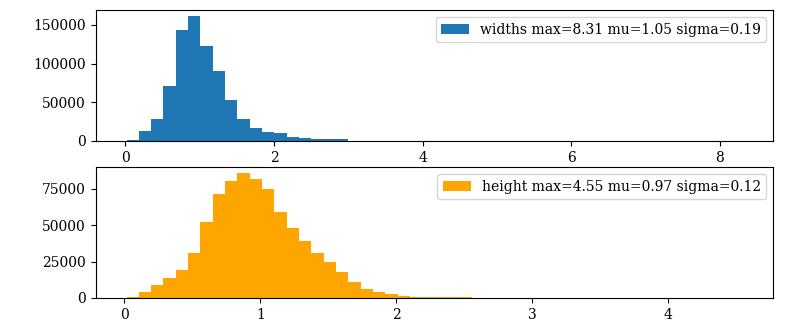
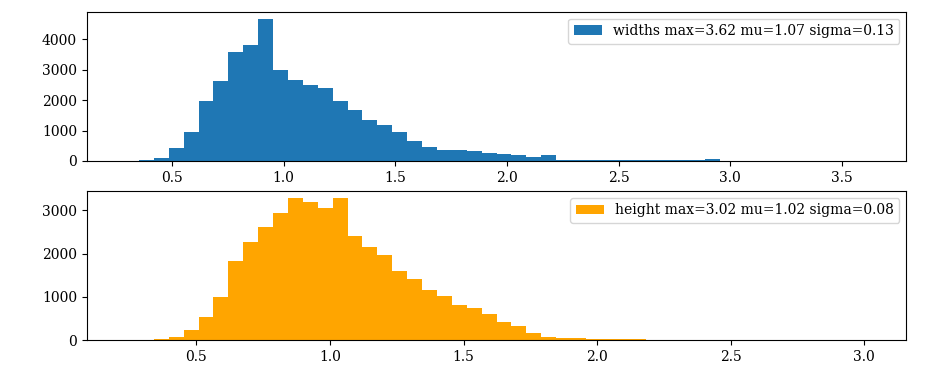
可以看出大部分的目标值都是集中在 之间的,所以上述变化没有问题。
损失函数
最后softmax也不是一定的,如果一个框有多个类别属性,那么softmax可以换成二元交叉熵(其实就只有一个属性的COCO数据集pytorch-YOLOv4也是用的二元交叉熵,不是很理解)。
数据集读取
这次相比之前使用的是PyTorch进行数据读入,并使用 albumentations 做数据增强,这次和YOLOv3有区别的地方在于,没有在构建数据集时候就生成target目标,而是只做数据增强,返回的结果包含三个 (image, bboxes, num_bboxes),其中 image 为增强后的图像数据;bboxes 为边界框集合 shape=(M,5),其中 M 为整个数据集中一张图片所包含的最大边界框上界;num_bboxes 为当前图像中的 bboxes 数目。在 bboxes 中,bboxes[num_bboxes:] 都用占位符进行占位没有实际意义,保持输入形状的相同,是为了避免JAX对训练进行重复编译。
数据增强
Albumentations
使用 albumentations 做数据增强非常方便,只需要给定bbox的格式属性(包含三种:pascal voc, yolo, coco,其中 yolo 为相对比例大小,而其他两种都是像素大小),这里我直接使用的是 coco 类型做数据增强,首先是训练集增强:
scale = 1.1
train_transform = A.Compose( # 训练集
[
A.LongestMaxSize(max_size=int(max(self.args.image_shape[:2])*scale)), # 最大边长缩放到max_size
A.PadIfNeeded( # 填充到目标大小
min_height=int(self.args.image_shape[0]*scale),
min_width=int(self.args.image_shape[1]*scale),
border_mode=cv2.BORDER_CONSTANT,
),
A.ColorJitter(brightness=0.4, contrast=0.0, saturation=0.7, hue=0.015, p=0.4), # 色彩变换,亮度brightness,对比度contrast,饱和度saturation,色调hue
A.OneOf(
[
A.ShiftScaleRotate( # 旋转
rotate_limit=10, p=0.5, border_mode=cv2.BORDER_CONSTANT
),
A.Affine(shear=10, p=0.5, mode=cv2.BORDER_CONSTANT), # 仿射变换
], p=0.4
),
A.HorizontalFlip(p=0.5), # 水平翻转
A.ToGray(p=0.05), # 灰度化
A.RandomCrop(*self.args.image_shape[:2]), # 随机裁剪成模型输入尺度
A.Normalize(mean=[0, 0, 0], std=[1, 1, 1]), # 数值归一化
],
bbox_params=A.BboxParams(format='coco', min_visibility=0.4) # 边界框编码格式,裁剪后的最小保留的边界框面积
)
val_transform = A.Compose( # 验证集
[
A.LongestMaxSize(max_size=self.args.image_shape[:2]),
A.PadIfNeeded(
min_height=self.args.image_shape[0],
min_width=self.args.image_shape[1],
border_mode=cv2.BORDER_CONSTANT,
),
A.Normalize(mean=[0, 0, 0], std=[1, 1, 1]),
],
bbox_params=A.BboxParams(format='coco', min_visibility=0.4)
)Mosaic
马赛克增强,以4张图像的mosaic为例:
- 先在目标图像大小中随机找出一个中心分界点
- 首先将当前的图像裁剪后放到左上角,再从数据集中随机抽取三个图片,分别放到图像的右上、左下、右下剩余三个地方
对每幅图片具体讲:每次都是先将图像进行传统数据增强(上一节部分),再一次预裁剪(在一个比原图像大20%的区域内进行一次裁剪,并保持裁剪后的图像长宽均不小于原图像的80%),然后先将裁剪后的图像缩放到目标图像的大小,最后对裁剪后的图像进行二次裁剪,放到mosaic图像中的对应位置上
步骤解析参考zhihu - 数据增强之Mosaic (Mixup,Cutout,CutMix),参考代码pytorch-YOLOv4
马赛克增强好处在于:
- 随机裁剪原始图像很容易将边界框消除掉,这样的操作对于小边界框的数据集有利,而COCO正好是这样的,所以应该增益较大。
- 通过马赛克增强可以减少填充所产生的边界,而且可以使一张图片的数据更加丰富。
这个方法我想了很久,但是自己实现效果总是不尽人意,所以当前还没有在训练中开启,后续在训练COCO数据集时候会开启。
实验结果
目前在COCO的小数据上进行测试后的结果是收敛的,但是在COCO上进行后发现loss根本不收敛,主要原因有:
- 我错误的将COCO类型的数据当作YOLO类型制作了target,这是根本性错误,已修正。
- Loss过大,在别人实现的YOLO中,batchsize=64,学习率只有
4e-5,而我的学习率开到了1e-4,太大了导致不收敛,可以参考flax/examples/imagenet中学习率和batchsize的关系式:
base_learning_rate = config.learning_rate * config.batch_size / 256.0
# 在Imagenet2012中config.learning_rate=0.1
# 这里我设置为config.learning_rate=2.5e-42023/11/20:重新开始在PASCAL VOC上的训练测试。