最新更新于: 2025年8月22日下午2点16分
参考文献:(1). Proximal Policy Optimization Algorithms - OpenAI, (2). Trust Region Policy Optimization - Berkeley,(3). Generalized Advantage Estimation - Berkeley
理论推导
基础定义
与概率论中记法一致,用大写字母表示随机变量,小写字母表示对应随机变量的观测值。
首先给出一些记号的定义:参考文献2中的记法,将一阶Markov过程记为 (S,A,P,R,ρ0,γ),其中每一项分别表示:
- S:策略空间。
- A:动作空间。
- P:一阶Markov转移概率,P:S×A→S,通常记为 P(s′∣s,a) 表示从状态 s 通过动作 a 转移到状态 s′ 的概率大小。
- R:奖励函数,R:S→R,表示达到状态 S 所获得的奖励大小。
- ρ(0):表示初始的状态分布空间,也就是一段轨迹中第一个状态所来自的分布 S0∼ρ0。
- γ:表示折扣系数,γ∼(0,1)。
记 π(a∣s) 为策略函数,Qπ(s,a),Vπ(s),Dπ(s,a) 分别为动作价值函数、状态价值函数、优势价值函数,其定义如下:
Qπ(St,At)=Vπ(St)=Dπ(St,At)= ESt+1,At+1,⋯[i=0∑∞γiR(St+i+1)] EAt,St+1,At+1,⋯[t=0∑∞γtR(St+1)]=EAt∼π(⋅∣St)[Qπ(St,At)] Qπ(St,At)−Vπ(St)
其中 St+1,At+1,⋯ 满足 ∀i⩾t 有 Si+1∼P(⋅∣Si,Ai),Ai+1∼π(⋅∣Si+1)。
用 τ=(S0,A0,S1,A1,⋯)∼π 表示由策略 π 与环境交互得到的一个轨迹,记 Rt=R(St+1),表示状态 St 通过执行动作 At 得到的奖励。
由Bellman方程可知 Qπ,Vπ 之间的关系为
Qπ(St,At)== ESt+1[R(St+1)+γVπ(St+1)] ESt+1,At+1[R(St+1)+γQπ(St+1,At+1)]
记 η(π)=ES∼ρ0[Vπ(S)] 为策略 π 的期望折后回报,故可用 η(π) 来衡量策略 π 的好坏。
策略迭代
定理1 策略回报递推关系
设策略 π~,π,则
η(π~)=η(π)+Eτ∼π~[t=0∑∞γtDπ(St,At)]
其中 τ=(S0,A0,S1,A1,⋯) 表示由策略 π~ 与环境交互得到的轨迹。
观察:该定理说明可以通过一个策略的折后回报估计另一个策略的折后回报,如果我们要得到比 π 更优的策略 π~ 则右式的第二项应该为正,所以我们期望最大化该项。
证明:(直接对优势函数进行分解即可)
Bellman方程== Eτ∼π~[t=0∑∞γtDπ(St,At)]=Eτ∼π~[t=0∑∞γt(Qπ(St,At)−Vπ(St))] Eτ∼π~[t=0∑∞γt(Rt+γVπ(St+1)−Vπ(St))] Eτ∼π~[−Vπ(S0)+t=0∑∞γtRt]=−ES0∼ρ0[Vπ(S0)]+Eτ∼π~[t=0∑∞γtRt] −η(π)+η(π~)
推论1 策略回报参数形式
下式中的参数与定理1中相同:
η(π~)=η(π)+t=0∑∞S∈S∑ρπ~(S)A∈A∑π~(A∣S)Dπ(S,A)
其中 ρπ~(S)=∑t=0∞γtP(St=S∣π~)
对ρπ(S)的理解:如果将 ρπ(S) 视为概率分布,则 ρπ(S) 表示由策略 π 走出的轨迹中,状态 S 出现的折后概率大小,如果 ρπ(S) 越大,说明 S 在轨迹中前面几个时刻出现的概率越大。
证明:(只需注意随机变量的随机性来源)由定理1可知
η(π~)==== η(π)+Eτ∼π~[t=0∑∞γtDπ(St,At)] η(π)+t=0∑∞S∈S∑P(St=S∣π~)A∈A∑π~(A∣S)γtDπ(S,A) η(π)+S∈S∑t=0∑∞γtP(St=S∣π~)A∈A∑π~(A∣S)Dπ(S,A) η(π)+S∈S∑ρπ~(S)A∈A∑π~(A∣S)Dπ(S,A)
当 π≈π~ 时,即 ρπ≈ρπ~,上式可表为
η(π~)=η(π)+t=0∑∞S∈S∑ρπ(S)A∈A∑π~(A∣S)Dπ(S,A)(1.1)
写成上式的形式可以用Monte-Carlo方法(MC方法)对其进行估计,注意到:
S∈S∑ρπ(S)[⋯]=A∈A∑π~(A∣S)[⋯]= 1−γ1ES∼ρπ[⋯] A∈A∑π(A∣S)π(A∣S)π~(A∣S)[⋯]=EA∼π[π(A∣S)π~(A∣S)[⋯]](1.2)
上式中第一个式子是先将 ρπ(⋅) 视为 S 上的概率密度函数,由于
S∈S∑ρπ(S)=S∈S∑t=0∑∞γtP(St=S∣π)=t=0∑∞γtS∈S∑P(St=S∣π)=t=0∑∞γt=1−γ1
所以先要乘上归一化系数 ρπ(S)←(1−γ)ρπ(S),故 (1.2) 式要乘 1−γ1 使等式成立。
策略迭代 最优化目标
用神经网络表示 π~,π:记 {π~(a∣s)=:π(a∣s;θ)=:π,π(a∣s)=:π(a∣s;θ−)=:π−,这里 θ,θ− 分别表示策略 π,π− 对应的神经网络的参数(这里 π,π− 的网络结构一致)。这里我们假设 π− 已知(一般是 π 的上一个迭代的参数,所以文献1,2中也记为 πold),期望能够最大化 η(π)。
策略迭代的带约束最优化目标 (Conservative Policy Iteration, CPI, 文献1中记法):
θmaxs.t.LCPI(θ):=η(π(θ))∝ES∼ρπ−EA∼π−[π−(A∣S;θ−)π(A∣S;θ)Dπ−(S,A)]ES∼ρπ−[DKL(π(⋅∣S;θ−)∣∣π(⋅∣S;θ))]⩽ε(1.3)
这里限制条件为 π,π− 的KL散度不超过给定的容许限制 ε。
于是可以用MC方法的对目标函数进行估计
LCPI(θ)≈T1(st,at)∼τ∑π(at∣st;θ−)π(at∣st;θ)Dπ−(s,a)
其中 τ=(s0,a0,⋯,sT,aT)∼π− 是策略 π− 走出的长度为 T 的轨迹,但是这样估计是有偏的,因为 S∼ρπ− 并不是在整个轨迹上的均匀采样,而是加权后的分布,越靠近初始时刻权重越大,而这里的误差应该可以由GAE缓解(文献3)。
有了目标函数的估计,下面就是如何求解带约束方程 (1.3):
- TRPO(置信域策略优化)直接通过共轭梯度法+线性搜索对其直接求解,复杂,低效。
- PPO(近似策略优化)通过加入clip函数或惩罚项,将带约束问题转化为无约束问题,简单,高效。
PPO算法
这里只介绍基于clip函数的PPO算法,也就是文献1中的第一个版本,第二个版本将 π,π− 的KL散度作为惩罚项,效果不如第一个版本,就不介绍了。
二者本质都是对(1.3)式的约束项(策略的近似度)的“惩罚”。
策略损失函数(Actor)
首先重写(1.3)式目标方程:
LCPI(θ)== ES∼ρπ−EA∼π−[π(A∣S;θ−)π~(A∣S;θ)Dπ−(S,A)]=Et[π(At∣St;θ−)π(At∣St;θ)Dt] Et[ξt(θ)Dt]
其中 ξt(θ):=π(At∣St;θ−)π(At∣St;θ),这一项可以被用来衡量策略 π,π− 的近似程度,如果 Et[ξt(θ)]→1,则说明 π≈π−,而PPO的clip函数损失函数就是这么做的。
当 ξt(θ) 超过范围 (1−ε,1+ε) 时,说明 π,π− 的差距过大,则不对 θ 进行更新,据此构造新的无约束优化目标:
θmaxLCLIP(θ):=Et[min{ξt(θ)Dt,clip(ξt(θ),1−ε,1+ε)Dt}]
其中 clip(x,a,b)=⎩⎪⎪⎨⎪⎪⎧a,x,b,x∈[b,∞),x∈[a,b),x∈(−∞,a),,我将 LCLIP 与 ξ 的关系,分 D>0 和 D<0 两种情况讨论,如下图所示:
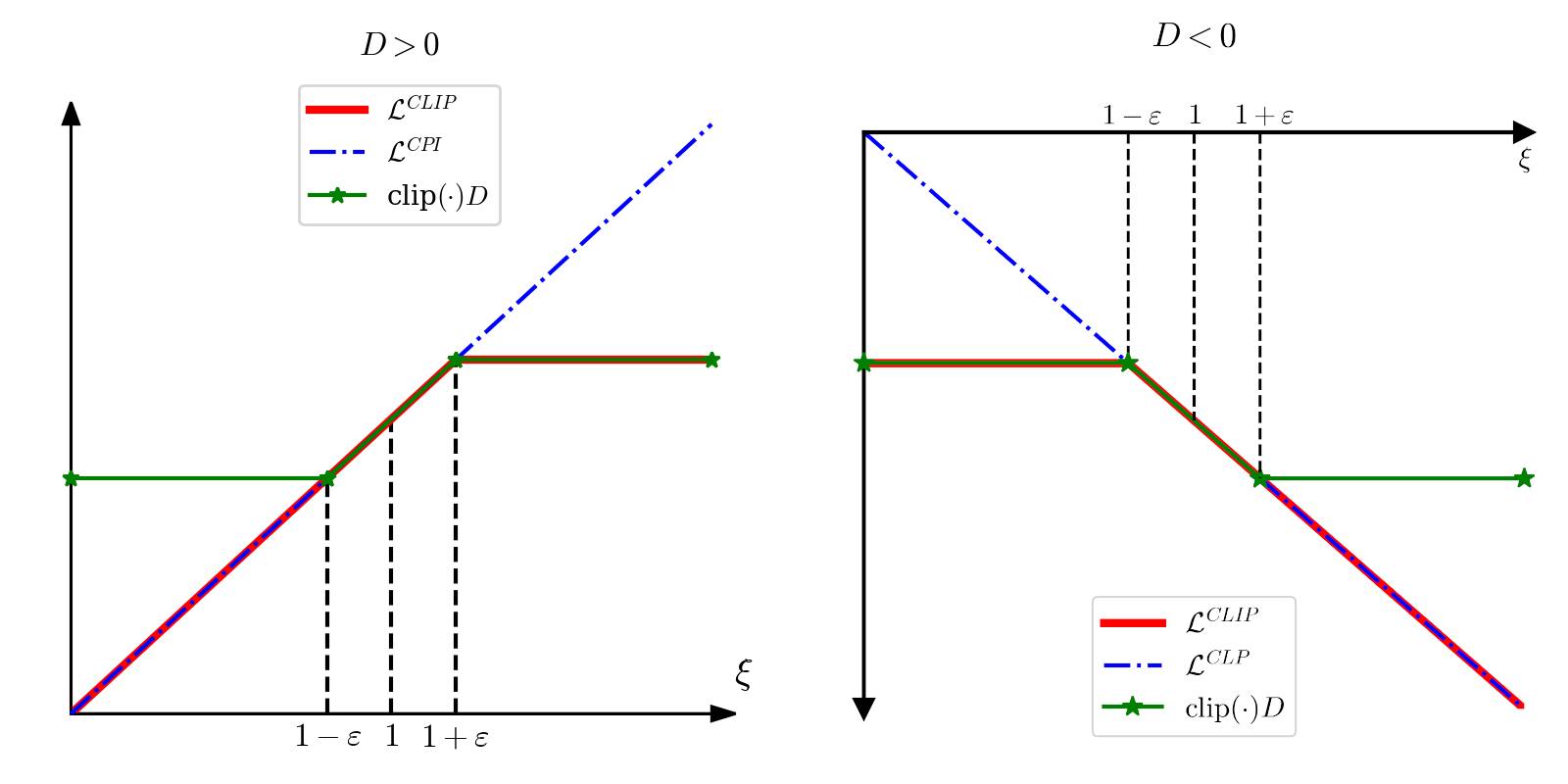
绘制右图代码
import numpy as np
import matplotlib.pyplot as plt
config = {
"font.family": 'serif',
"figure.figsize": (5, 5),
"font.size": 14,
"font.serif": ['SimSun'],
"mathtext.fontset": 'cm',
'axes.unicode_minus': False
}
plt.rcParams.update(config)
fig, ax = plt.subplots()
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
ax.spines['left'].set_position('zero')
ax.spines['left'].set_linewidth(2)
ax.spines['bottom'].set_position('zero')
ax.spines['bottom'].set_linewidth(2)
ax.xaxis.set_ticks_position('bottom')
ax.yaxis.set_ticks_position('left')
ax.set_xticks([])
ax.set_yticks([])
ax.axis([0, 2, -2, 0])
ax.plot(2, 0, ls="", marker=">", ms=10, color="k", clip_on=False)
ax.plot(0, -2, ls="", marker="v", ms=10, color="k", clip_on=False)
eps = 0.2
ax.plot([0, 1-eps], [-1+eps, -1+eps], 'r', label=r"$\mathcal{L}^{CLIP}$", lw=4)
ax.plot([1-eps, 2], [-1+eps, -2], 'r', lw=4)
ax.plot([0, 2], [0, -2], 'b-.', label=r"$\mathcal{L}^{CLP}$", lw=2)
ax.plot([0, 1-eps], [-1+eps, -1+eps], 'g*-', label=r"$\text{clip}(\cdot)D$", clip_on=False, zorder=3, lw=2, ms=10)
ax.plot([1-eps, 1+eps], [-1+eps, -1-eps], 'g*-', lw=2, ms=10)
ax.plot([1+eps, 2], [-1-eps, -1-eps], 'g*-', clip_on=False, lw=2, ms=10)
ax.plot([1-eps, 1-eps], [0, -1+eps], 'k--', lw=1.5)
ax.plot([1, 1], [0, -1], 'k--', lw=1.5)
ax.plot([1+eps, 1+eps], [0, -1-eps], 'k--', lw=1.5)
ax.text(1-eps-0.08, 0.03, r"$1-\varepsilon$")
ax.text(1-0.02, 0.03, r"$1$")
ax.text(1+eps-0.08, 0.03, r"$1+\varepsilon$")
ax.text(2-0.02, -0.12, r"$\xi$")
fig.suptitle("$D<0$")
fig.legend(loc="lower center")
fig.tight_layout()
plt.savefig("ppo_D_neg.png", dpi=300)
plt.show()
价值损失函数(Critic)
第二个问题:Dt 如何估计?和A2C的方法相同,用神经网络 v(s;w) 近似 Vπ(s),其中 w 为神经网络的参数,则
Dt==(TD)≈(MC)≈(MC)= ESt,At[Qπ−(St,At)−Vπ−(St)] ESt,At,St+1[Rt+γVπ−(St+1)−Vπ−(St)] rt+γv(st+1;w−)−v(st;w−)=δt −v(st;w−)+rt+γrt+1+⋯+γT−t+1rT−1+γT−tv(sT;w−) δt+γδt+1+⋯+γT−t+1δT−1(2.1)
其中第三行为TD估计,第四五行为MC估计,δt=rt+γv(st+1;w−)−v(st;w−),这个 δt 和Q-Learning中的TD误差有点类似,TD误差定义是
δtTD=v(st;w)−(rt+γv(st+1;w−))
注意(2.1)式中St∼ρπ−,所以 St 还是带有对轨迹进行加权平均后的概率分布,越靠近初始时刻系数越大。这就要引入GAE(Generalized Advantage Estimation,文献3)对其进行估计(这其实也是对TD和MC估计的一个综合,λ=0 时为TD估计,λ=1 时为MC估计):
D^t=δt+(γλ)δt+1+⋯+(γλ)T−t+1δT−1(2.2)
其中 λ 称为GAE系数,GAE本质上是TD-λ的应用。
对参数 w 的更新可由Bellman方程推出,关于状态价值函数的Bellman方程如下:
ESt[Vπ(St)]=ESt,At,St+1[Rt+γVπ(St+1)]
则TD估计为 Vπ(st)≈rt+γVπ(st+1),但这里可以利用更好的估计 Dt+Vπ(st),因为它是综合了TD和MC方法的估计,所以应具有更小的方差,更稳定,为了避免偏差的传递,可以利用DDQN中目标网络的方法,构造出以下价值函数的最优化目标(Value Function, VF, 文献1中记法):
wminLVF:=Et[∣∣∣Dt+v(St;w−)−v(St;w)∣∣∣2]
鼓励探索性(Regular)
最后一个问题:如何鼓励智能体去探索新的策略?
也就是说不要使决策过于绝对,用信息熵表示就是 Entropy[π(⋅∣S)],∀S∈S 不能过小,所以可以构造信息熵正则项:
θmaxLENT(θ):=Et[Entropy[π(⋅∣S)]]=Et[−a∈A∑π(a∣St;θ)lnπ(a∣St;θ)]
总损失函数
综上,我们得到了PPO算法的损失函数如下:
θ,wminLPPO(θ,w)=−LCLIP(θ)+c1LVF(w)−c2LENT(θ)
其中 c1,c2 分别为的对应损失函数的系数。
代码实现
在自己设计的RL框架下,使用TF2实现,参考了cleanrl强化学习框架的PPO代码:ppo.py - cleanrl GitHub,还有其对应的讲解视频:PPO Implementation - YouTube(但他是用PyTorch实现的)
实现的是多线程的PPO,对于CartPole环境训练30s就能得到最优策略,原代码:PPO.py
实现细节
主要难点在于Actor的写法,我采用 np.ndarray 记录Actor在每个时刻 t 下的信息,该部分需要记录:
- 四元组 (S,A,R,S′):状态 St,执行动作 At,得到奖励 Rt,以及下一个状态 St+1。
- 终止标记 T:Tt 表示 St+1 是否为终止状态。
- 优势函数(GAE) AD:ADt=∑i=0T−t−1(γλ)iδt+i⋅Tt+i,与(2.2)式一致。
- 目标价值 V:Vt=ADt+v(st;w−).
- 对数策略分布 LP:LPt=ln(π(at∣st;θ−))
需要注意的细节是计算 AD 时,终止状态无需加后继的 δ,否则会加到初始状态上,导致结果错乱,并且还需计算最后一个状态 sT 对应的价值函数 v(sT;w−)。
这部分的正确写法就是使用 numpy,使用 jax 中的数据结构保存到显存中,只会因为IO频率过高导致降速,除非能够直接将环境编译到XLA中,也就是 envpool 的实现效果。(这部分在numpy上已测试过)
numpy的memory_buffer实现
S, A, R, S_, T, AD, V, LP = \
np.zeros(shape=(self.T, self.N) + state_shape, dtype='float32'), \
np.zeros(shape=(self.T, self.N) + action_shape, dtype='int32'), \
np.zeros(shape=(self.T, self.N), dtype='float32'), \
np.zeros(shape=(self.T, self.N) + state_shape, dtype='float32'), \
np.zeros(shape=(self.T, self.N), dtype='bool'), \
np.zeros(shape=(self.T, self.N), dtype='float32'), \
np.zeros(shape=(self.T, self.N), dtype='float32'), \
np.zeros(shape=(self.T, self.N), dtype='float32')
for step in range(self.T):
v, proba = self.pred(self.state)
V[step] = v.numpy().squeeze()
action = sample_from_proba(proba.numpy())
action_one_hot = make_onehot(action, depth=self.env.action_size).astype('bool')
LP[step] = np.log(proba[action_one_hot])
state_, reward, terminal = self.env.step(action)
action = action.reshape(-1, 1)
S[step], A[step], R[step], S_[step], T[step] = \
self.state, action, reward, state_, terminal
self.state = state_
v_last, _ = self.pred(self.state)
v_last = v_last.numpy().reshape(1, self.N)
AD = R + self.gamma * np.r_[V[1:,:], v_last] * (~T) - V
for i in reversed(range(self.T-1)):
AD[i] += self.gamma * self.lambda_ * AD[i+1] * (~T[i])
V += AD
第二个在于训练函数 train_step 的写法:
jax的train_step写法
@partial(jax.jit, static_argnums=0)
def train_step(self, state:TrainState, dataset, idxs):
def loss_fn(params, dataset, idxs):
s, a, ad, v, logpi = jax.tree_map(lambda x: x[idxs], dataset)
v_now, logits = self.model.state.apply_fn(params, s)
loss_v = ((v_now - v - ad) ** 2).mean() / 2
if self.args.flag_ad_normal:
ad = (ad - ad.mean()) / (ad.std() + self.args.EPS)
logpi_now = jax.nn.log_softmax(logits)[jnp.arange(a.shape[0]), a.flatten()].reshape(-1, 1)
rate = jnp.exp(logpi_now - logpi)
loss_p = jnp.minimum(
ad * rate,
ad * jnp.clip(
rate,
1 - self.args.epsilon,
1 + self.args.epsilon
)
).mean()
loss_entropy = - (jax.nn.log_softmax(logits) * jax.nn.softmax(logits)).sum(-1).mean()
loss = - loss_p \
+ self.args.coef_value * loss_v \
- self.args.coef_entropy * loss_entropy
return loss, (v, ad, loss_p, loss_v, loss_entropy)
(loss, metrics), grads = jax.value_and_grad(loss_fn, has_aux=True)(state.params, dataset, idxs)
state = state.apply_gradients(grads=grads)
return state, metrics
tensorflow的train_step写法
第二个重点在于 @tf.function 的写法
@tf.function
def train_step(self, s, a, ad, v, logpi):
with tf.GradientTape() as tape:
v_now, p_now = self.model(s)
loss_v = tf.square(v_now-v-ad)
if self.flag_clip_value:
loss_v_clip = tf.square(
tf.clip_by_value(
v_now - v,
clip_value_min=-self.v_epsilon,
clip_value_max=self.v_epsilon
)-ad
)
loss_v = tf.maximum(loss_v, loss_v_clip)
loss_v = tf.reduce_mean(loss_v / 2)
if self.flag_ad_normal:
mean, var = tf.nn.moments(ad, axes=[0])
ad = (ad - mean) / (var + EPS)
logpi_now = tf.math.log(tf.reshape(p_now[a], (-1, 1)))
lograte = logpi_now - logpi
rate = tf.math.exp(lograte)
loss_p_clip = tf.reduce_mean(
tf.minimum(
rate*ad,
tf.clip_by_value(
rate,
clip_value_min=1-self.epsilon,
clip_value_max=1+self.epsilon
)*ad
)
)
loss_entropy = -tf.reduce_mean(
tf.reduce_sum(p_now*tf.math.log(p_now), axis=1)
)
loss = - loss_p_clip \
+ self.coef_value * loss_v \
- self.coef_entropy * loss_entropy
grads = tape.gradient(loss, self.model.get_trainable_weights())
self.model.apply_gradients(grads)
return tf.reduce_mean(v_now), loss_p_clip, loss_v, loss_entropy
- 一定要实现线性学习率下降,否则网络参数会发散。
测试结果
KataRL中用JAX实现PPO的代码ppo_jax.py,线性模型超参数文件,atari环境超参数文件,PPO在所有环境上均碾压其他算法:不同环境下算法比较。使用方法:
python katarl/run/ppo/ppo.py --train --wandb-track --capture-video
python katarl/run/ppo/ppo.py --train --wandb-track --capture-video --env-name Acrobot-v1
python katarl/run/ppo/atari_ppo.py --train --wandb-track --capture-video
总共16个超参数(CartPole超参数为例):
gamma = 0.99
lambda_ = 0.95
epsilon = 0.2
v_epsilon = 1
actor_N = 8
frames_M = int(2e5)
step_T = 512
epochs = 5
batch_size = 32
coef_value = 1
coef_entropy = 0.01
flag_ad_normal = True
flag_clip_value = False
init_lr = 3e-4
flag_anneal_lr = True
EPS = 1e-8
CartPole
30s能够达到最大的步数(500step),以上超参数训练结果,总共重启30次,每次训练用时5分钟。

Breakout
用时6h能够完成一次训练,效率还是很低,远不如jax+envpool,有待更新算法,训练轨迹如下:
