《机器学习实战》第三章 分类
最新更新于: 2024年5月24日上午11点17分
MNIST 数据集进行分类
《机器学习实战:基于Scikit-Learn,Keras和TensorFlow》中第三章内容,英文代码可参考github - handson-ml2/03_classification.ipynb
下面内容对应的Jupyter Notebook代码位于github:3.classification.ipynb
数据集导入
使用Scikit-Learn中的 sklearn.datasets.fetch_openml 进行数据读取. 可以下载的数据集可以在开放数据集网址 www.openml.org 上找到.
下载的数据集位于 〜/ scikit_learn_data,加载的数据集具有字典的结构,加载速度太慢可以使用本地打开方式(推荐):
直接到 OpenML - mnist_784 中下载数据集,然后发下下载下来的格式是 .arff,可以使用 scipy.io.arff.loadarff 打开,然后将数据集中第0个用DataFrame打开即可看到数据集.
# from sklearn.datasets import fetch_openml
# mnist = fetch_openml('mnist_784', version=1)
# mnist.keys()from scipy.io.arff import loadarff
import pandas as pd
mnist = loadarff('C:/Users/yy/scikit_learn_data/openml/mnist_784.arff')
df = pd.DataFrame(mnist[0])
df| pixel1 | pixel2 | pixel3 | pixel4 | pixel5 | pixel6 | pixel7 | pixel8 | pixel9 | pixel10 | ... | pixel776 | pixel777 | pixel778 | pixel779 | pixel780 | pixel781 | pixel782 | pixel783 | pixel784 | class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | b'5' |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | b'0' |
| 2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | b'4' |
| 3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | b'1' |
| 4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | b'9' |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 69995 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | b'2' |
| 69996 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | b'3' |
| 69997 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | b'4' |
| 69998 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | b'5' |
| 69999 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | b'6' |
70000 rows × 785 columns
数据集转化,将上述表格划分为数据集与验证集,需要注意的是:由于标签是字符串,所以转化后的结果还需要进一步转化数据格式.
import numpy as np
x, y = df.values[:, :-1].astype(np.float32) / 255, df.values[:, -1].astype(np.uint8)
train_x, test_x, train_y, test_y = x[:60000], x[60000:], y[:60000], y[60000:]
print(train_x.shape, test_x.shape, train_y.shape, test_y.shape)(60000, 784) (10000, 784) (60000,) (10000,)
# 显示一张图片
import matplotlib as mpl
import matplotlib.pyplot as plt
sample_x, sample_y = x[0], y[0]
sample_x_figure = sample_x.reshape((28, 28))
plt.imshow(sample_x_figure, cmap='binary')
plt.axis('off')
plt.show()
print("标签:", sample_y)
标签: 5
def plot_figures(instances, images_per_row=10, **options):
# 图像大小
size = 28
# 每行显示的图像,取图像总数和每行预设值的较小值
image_per_row = min(len(instances), images_per_row)
# 总共的行数,下行等价于 ceil(len(instances) / image_per_row)
n_rows = (len(instances) - 1) // image_per_row + 1
# 如果有空余位置没有填充,用空白进行填充
n_empty = n_rows * image_per_row - len(instances)
padded_instances = np.concatenate([instances, np.zeros([n_empty, size * size])], axis=0)
# 将图像排列成网格
image_grid = padded_instances.reshape([n_rows, images_per_row, size, size])
# 使用np.transpose对图像网格进行重新排序,并拉伸成一张大图像用于绘制
big_image = image_grid.transpose([0, 2, 1, 3]).reshape([n_rows * size, images_per_row * size])
plt.imshow(big_image, cmap='binary', **options)
plt.axis('off')
plt.tight_layout()
plt.figure(figsize=(6, 6))
plot_figures(train_x[:100])
plt.savefig('figure/MNIST前100张图像')
plt.show()
训练二元分类器
先从简单的问题开始,如何分类一张图片是5还不是5. 可以使用随机梯度下降优化的线性分类器 SGDClassifier.
from sklearn.linear_model import SGDClassifier
train_y_5 = (train_y == 5)
test_y_5 = (test_y == 5)
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(train_x, train_y_5)print("简单预测一个样例:", sgd_clf.predict([sample_x]))简单预测一个样例: [ True]
评估性能
K-折交叉验证
下面使用 sklearn.model_selection.StratifiedKFold 实现自定义的交叉验证,使用方法和 cross_val_score() 类似,只不过这里将折叠数参数记为 n_splits(默认为5).
from sklearn.model_selection import StratifiedKFold
from sklearn.base import clone
skfolds = StratifiedKFold(n_splits=3, random_state=42, shuffle=True)
for train_idx, test_idx in skfolds.split(train_x, train_y_5):
clone_clf = clone(sgd_clf) # 每次新创建一个模型
train_x_folds = train_x[train_idx]
train_y_folds = train_y_5[train_idx]
test_x_folds = train_x[test_idx]
test_y_folds = train_y_5[test_idx]
clone_clf.fit(train_x_folds, train_y_folds)
pred = clone_clf.predict(test_x_folds)
accuracy = sum(pred == test_y_folds)
print(accuracy / len(pred)) # 输出准确率0.97305
0.97465
0.9731
from sklearn.model_selection import cross_val_score
cross_val_score(sgd_clf, train_x, train_y_5, cv=3, scoring='accuracy')array([0.9748, 0.9657, 0.9692])
print("全部非5图像的占比:", sum(~train_y_5) / len(train_y))全部非5图像的占比: 0.90965
使用交叉验证效果感觉不错,但是其实如果一个分类器将所有图像都判断为非5,其实就可以达到90.9%的正确率,所以上述分类结果没有很强的说服力,下面使用混淆矩阵进一步说明结果.
混淆矩阵
混淆矩阵的列是真实值,行是预测值, 处的值表示真实值为 时,模型预测结果为 的个数.
使用 sklearn.metrics.confusion_matrix(true_y, pred_y) 可以很容易地获得混淆矩阵. 而获得预测值的很好的一个方法是通过交叉验证返回的预测结果 sklearn.model_selection.cross_val_predict. 由于只使用了训练集,使用交叉验证可以保证将训练集进一步划分为更小的训练集与验证集,保证了预测的干净(预测数据没有再训练中出现)
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import confusion_matrix
train_y_pred = cross_val_predict(sgd_clf, train_x, train_y_5, cv=3)
confusion_matrix(train_y_5, train_y_pred)array([[53613, 966],
[ 840, 4581]], dtype=int64)
定义
在二分类的混淆矩阵的每个元素都有对应的名称:假设真实值与预测结果的列表排列均为 [假, 真],则每个位置的元素对应名称如下所示:
(1,1)表示真负类(TN).(1,2)表示假正类(FP).(2,1)表示假负类(FN).(2,2)表示真正类(TP).
记忆方法非常简单,名称中第一个“真与假”表示是否预测正确,第二个“正与负”表示预测结果的类别.
有两个常用参数:
- 精度(Precision):预测结果是真的时候,有多大概率是对的.
- 召回率(Recall):标签为真的时候,能有多大的概率预测对.(如果用假设检验的第一类错误来理解,设原假设为样本标签为真,那么“1-召回率”就是第一类错误)
一种评估精度与召回率的方法是 参数(两者的调和平均数):
用法:使用F1一般是希望精度与召回率同时较高时所用,但是对于特定问题,可能仅需要某一种参数越高越好. 例如检测小偷,肯定希望召回率越高越好,也就是所谓的“宁可错杀一千,不可放过一个”;而视频筛选中,希望精度越高越好,因为我们希望即使错筛了很多好的视频,但是留下来的都是好的就行.
精度-召回率曲线:模型通过得分是否超过阈值判断样本属于的类别,通过设定不同的阈值,从而可以得到不同的PR值,绘制出的曲线,一般称为P-R曲线,一般也用P-R曲线与x轴围成的面积(Area Under Curve, AUC)评估模型好坏(越大越好),面积计算可以使用 sklearn.metrics.auc.
实现
Scikit-Learn中可以很容易地计算出精度,召回率和 参数,分别为 sklearn.metrics 中的 precision_score, recall_score, f1_score,代入预测值与真实值即可计算出结果.
from sklearn.metrics import precision_score, recall_score, f1_score
print("精度:", precision_score(train_y_5, train_y_pred))
print("召回率:", recall_score(train_y_5, train_y_pred))
print("F1:", f1_score(train_y_5, train_y_pred))精度: 0.8258518117901569
召回率: 0.8450470392916436
F1: 0.8353391684901532
PR曲线
SGD 模型输出的是对样本的打分,而判断是否属于哪类则是通过阈值来确定的,默认阈值为 0,对于二分类问题,阈值与召回率成负相关关系(因为如果将所有都预测为真,则召回率一定很好),我们可以根据不同的阈值从而获得不同的预测结果,对应不同的模型,从而绘制出精度与召回率的关系图.
首先需要求出模型对每个样本的打分,还是用过 cross_val_predict 获得,但是这里需要从模型的 decision_function 获得评分,而不是最后的预测结果,使用 method 可以选择最后模型输出的函数,默认为 method='predict'.
最后使用 sklearn.metrics.precision_recall_curve 不同阈值下的精度与召回率的值,使用方法为
precision_recall_curve(y_true, probas_pred),第一个参数为标签真实值,第二个参数为所有可能的得分. 于是阈值会根据全部得分从小到大逐一选择,并求出对应精度与召回率. 返回值:精度,召回率,阈值.
注意:精度和召回率的维数为
(n_thresholds + 1,)比阈值大1,精度最后一个元素为1,而召回率最后一个元素为0,绘图时记得将其删去.
# 使用decision_function获得样本的打分
sgd_clf.decision_function(train_x[:10])array([ 0.49010364, -5.79399718, -8.1066338 , -4.37994204, -4.7884292 ,
-4.57067767, -4.47894354, -5.7897907 , -2.49371734, -3.34911346])
from sklearn.metrics import precision_recall_curve
train_y_scores = cross_val_predict(sgd_clf, train_x, train_y_5, cv=3, method='decision_function')
precisions, recalls, thresholds = precision_recall_curve(train_y_5, train_y_scores)def plot_precision_recall_vs_threshold(precisions, recalls, thresholds):
plt.figure(figsize=(10, 5))
plt.plot(thresholds, precisions[:-1], "b--", label="精度")
plt.plot(thresholds, recalls[:-1], "g-", label="召回率")
plt.legend()
plt.xlabel("阈值")
plt.axis([thresholds.min(), thresholds.max(), 0, 1.05])
plot_precision_recall_vs_threshold(precisions, recalls, thresholds)
plt.show()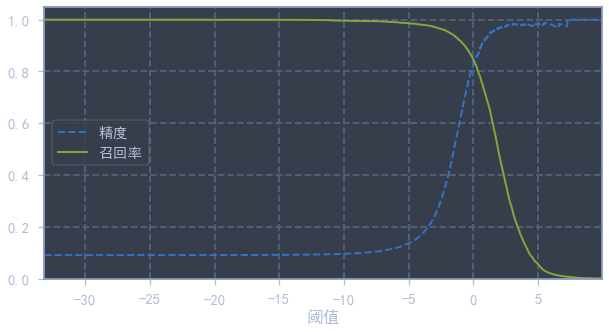
recall_for_90_precision = recalls[np.argmax(precisions >= 0.90)] # 利用np.argmax可以找到第一个true的下标from sklearn.metrics import auc
def plot_precision_vs_recall(precisions, recalls):
plt.figure(figsize=(6, 6))
plt.plot(recalls, precisions, 'b-', lw=2)
plt.xlabel('召回率(Recall)')
plt.ylabel('精度(Precision)')
plt.axis([0, 1, 0, 1])
plt.title('P-R曲线')
plot_precision_vs_recall(precisions, recalls)
plt.plot([recall_for_90_precision, recall_for_90_precision], [0, 0.9], 'r--')
plt.plot([0, recall_for_90_precision], [0.9, 0.9], 'r--')
plt.plot([recall_for_90_precision], [0.9], 'ro')
print("曲线下面积为:", auc(recalls, precisions))曲线下面积为: 0.8907556859354993
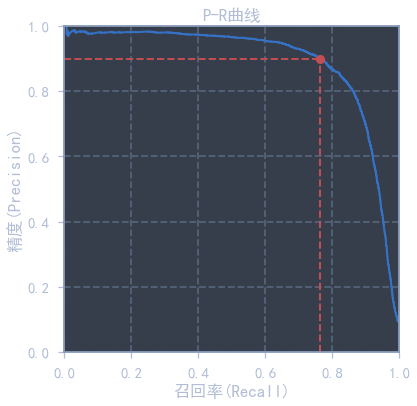
红点为90%精度对应的召回率,下面还会用到.
ROC曲线
另一种常用的曲线称为 受试者工作特征曲线(Receiver Operating Characteristic Curve, ROC),绘制的是真正类率(召回率)和假正类率(FPR),它们的定义如下
不难发现,这种什么率就是按照混淆矩阵的行占比来定义的,例如上述两个FPR和TPR就分别是全部负类样本中被错误预测的概率的和被正确预测的概率,特别的TPR还被称为特异度.
实际使用中,我们会直接画出ROC曲线,然后用曲线下面积AUC来评判模型的好坏.
使用 sklearn.metrics.roc_curve 获得 fpr, tpr, theresholds 对应结果(与 precision_recall_curve 曲线返回值相同)
注:由于有
drop_intermediatebool=True参数,会自动舍弃一些次优阈值,使得曲线显示更加清晰,所以返回结果中阈值个数可能远小于输入的样本个数.
from sklearn.metrics import roc_curve
from sklearn.metrics import roc_auc_score
fpr, tpr, thresholds = roc_curve(train_y_5, train_y_scores)
print("ROC得分:", roc_auc_score(train_y_5, train_y_scores))ROC得分: 0.970452271342763
def plot_roc_curve(fpr, tpr, label=None):
plt.plot(fpr, tpr, lw=2, label=label)
plt.plot([0, 1], [0, 1], 'k--')
plt.axis([0, 1, 0, 1])
plt.xlabel('FPR(1-特异度)')
plt.ylabel('TPR(召回率)')
plt.figure(figsize=(8, 6))
plot_roc_curve(fpr, tpr, label='SGD')
plt.savefig("./figure/ROC曲线")
plt.show()
print("ROC得分:", auc(fpr, tpr))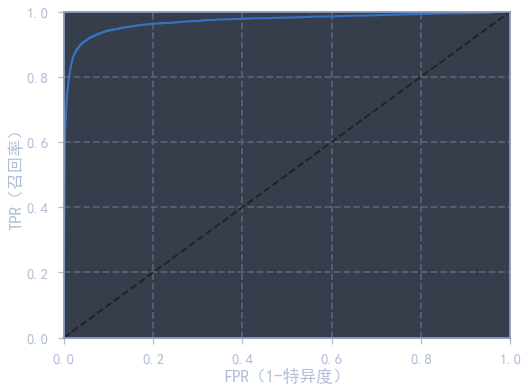
ROC得分: 0.970452271342763
使用随机森林 RandomForestClassifier 与 SGD 进行对比实验. 在随机森林模型中,打分是根据概率分布得到的,使用 .predict_proba() 可以得到样本对应的标签概率分布率,然后做正例列的切片即可得到得分.
from sklearn.ensemble import RandomForestClassifier
forest_clf = RandomForestClassifier(random_state=42)
y_probas_forest = cross_val_predict(forest_clf, train_x, train_y_5, cv=3, method='predict_proba')y_scores_forest = y_probas_forest[:, 1]
fpr_forest, tpr_forest, thresholds_forest = roc_curve(train_y_5, y_scores_forest)
print("随机森林ROC评分:", roc_auc_score(train_y_5, y_scores_forest)) # 从得分可以明显看出,随机森林的二分类效果好于SGD随机森林ROC评分: 0.9983400347444625
plt.figure(figsize=(8, 6))
plot_roc_curve(fpr, tpr, label='SGD')
plot_roc_curve(fpr_forest, tpr_forest, label='随机森林')
fpr_for_90_percision_sgd = fpr[np.argmax(tpr >= recall_for_90_precision)]
tpr_for_sgd_fpr_forest = tpr_forest[np.argmax(fpr_forest >= fpr_for_90_percision_sgd)]
plt.plot([fpr_for_90_percision_sgd, fpr_for_90_percision_sgd], [0, recall_for_90_precision], 'r--', lw=2)
plt.plot([0, fpr_for_90_percision_sgd], [recall_for_90_precision, recall_for_90_precision], 'r--', lw=2)
plt.plot([fpr_for_90_percision_sgd], [recall_for_90_precision], 'ro', label='SGD 90%精度对应点')
plt.plot([fpr_for_90_percision_sgd, fpr_for_90_percision_sgd], [0, tpr_for_sgd_fpr_forest], 'r--', lw=2)
plt.plot([0, fpr_for_90_percision_sgd], [tpr_for_sgd_fpr_forest, tpr_for_sgd_fpr_forest], 'r--', lw=2)
plt.plot([fpr_for_90_percision_sgd], [tpr_for_sgd_fpr_forest], 'yo', label='随机森林同FPR对应点')
plt.legend()
plt.show()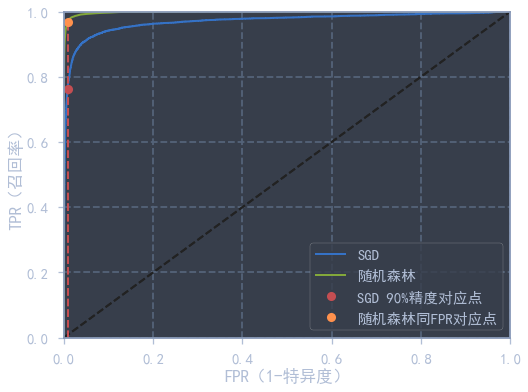
多类分类器
一些严格的二元分类器(SVM,线性分类器)也可以用于分类,有以下两种策略可以通过多个二元分类器实现多分类的目的:(例如创建一个模型将数字图像分类为0到9)
-
一对多(One vs Rest):训练10个二元分类器,每种数字一个,用于区分是或不是该数字,例如一个分类器用于划分是数字0或不是数字0,最后取最高的分类器对特定数字的决策分数作为整个模型的预测结果.
-
一对一(One vs One):训练 个二元分类器,每个分类器用于区分两种数字,例如区分0和1,0和2,1和2等等. 每个分类器得到一个预测结果,最后通过判断哪个类获胜最多作为模型的预测结果.
# SVM二分类器默认为OvO多分类策略
from sklearn.svm import SVC
svm_clf = SVC()
svm_clf.fit(train_x, train_y)# 使用OvR策略22.8min
from sklearn.multiclass import OneVsRestClassifier
svm_clf_ovr = OneVsRestClassifier(SVC(), verbose=2)
svm_clf_ovr.fit(train_x, train_y)# SGD多分类默认使用OvR策略
sgd_clf = SGDClassifier()
sgd_clf.fit(train_x, train_y)cross_val_score(sgd_clf, train_x, train_y, cv=3, scoring='accuracy')array([0.9069 , 0.9061 , 0.90995])
# 使用SVM在测试集上的正确率竟然有98%!!!
from sklearn.metrics import accuracy_score
accuracy_score(test_y, svm_clf_ovr.predict(test_x))0.98
accuracy_score(test_y, svm_clf.predict(test_x))0.9792
# 保存一下模型
import joblib
joblib.dump(svm_clf_ovr, 'svm_ovr_mnist.pkl')['svm_ovr_mnist.pkl']
误差分析
利用混淆矩阵进行多分类的误差分析,使用 plt.matshow() 对混淆矩阵进行可视化,在按每行除以对应标签总样本数目,再将对角线上值置为0,即可获得每种类别分类的错误率了.
train_y_pred = cross_val_predict(sgd_clf, train_x, train_y, cv=3)
confuse_matrix = confusion_matrix(train_y, train_y_pred)
confuse_matrixarray([[5743, 2, 20, 12, 16, 44, 39, 10, 32, 5],
[ 2, 6463, 53, 22, 9, 43, 15, 18, 103, 14],
[ 49, 33, 5328, 93, 87, 47, 88, 73, 136, 24],
[ 35, 16, 185, 5325, 12, 288, 28, 62, 110, 70],
[ 19, 16, 28, 14, 5413, 14, 49, 18, 67, 204],
[ 61, 13, 42, 173, 68, 4792, 85, 30, 98, 59],
[ 47, 12, 50, 4, 45, 125, 5599, 4, 28, 4],
[ 23, 22, 68, 29, 77, 20, 4, 5830, 23, 169],
[ 60, 92, 98, 186, 67, 340, 53, 33, 4832, 90],
[ 42, 16, 24, 113, 222, 84, 2, 215, 66, 5165]],
dtype=int64)
plt.matshow(confuse_matrix, cmap='gray')
plt.show()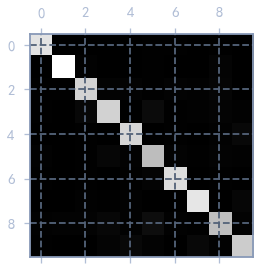
row_sums = conf_mx.sum(axis=1)
norm_confuse_matrix = confuse_matrix / row_sums
np.fill_diagonal(norm_confuse_matrix, 0)
plt.matshow(norm_confuse_matrix, cmap='gray')
plt.show() # 可以看出,3很容易被分类成5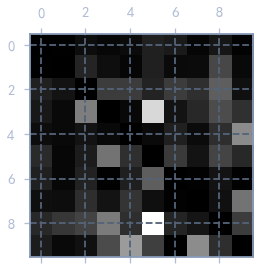
通过上面的混淆矩阵可以看出,3很容易被识别成5,下面我们来看看3与5的混淆矩阵中的部分图像.
cl_a, cl_b = 3, 5 # class a and class b
aa_x = train_x[(train_y == cl_a) & (train_y_pred == cl_a)]
ab_x = train_x[(train_y == cl_a) & (train_y_pred == cl_b)]
ba_x = train_x[(train_y == cl_b) & (train_y_pred == cl_a)]
bb_x = train_x[(train_y == cl_b) & (train_y_pred == cl_b)]
plt.figure(figsize=(6, 6))
plt.subplot(221); plot_figures(aa_x[:25], images_per_row=5)
plt.subplot(222); plot_figures(ab_x[:25], images_per_row=5)
plt.subplot(223); plot_figures(ba_x[:25], images_per_row=5)
plt.subplot(224); plot_figures(bb_x[:25], images_per_row=5)
plt.savefig('figure/混淆矩阵实例图')
plt.show()
多输出分类
使用K近邻对图像进行降噪处理.
# 生成随机噪声图像
import numpy as np
np.random.seed(42)
noise = np.random.randint(0, 100, (len(train_x), 784)) / 255
train_x_modify = train_x + noise
noise = np.random.randint(0, 100, (len(test_x), 784)) / 255
test_x_modify = test_x + noise
train_y_modify = train_x
test_y_modify = test_xplot_figures([test_x_modify[0], test_y_modify[0]])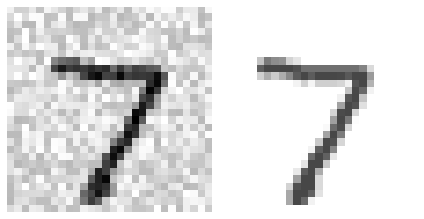
from sklearn.neighbors import KNeighborsRegressor
knn_reg = KNeighborsRegressor()
knn_reg.fit(train_x_modify, train_y_modify)some_idx = [0, 6, 10]
sample_x_modify = test_x_modify[some_idx]
sample_y_modify = test_y_modify[some_idx]
plt.figure(figsize=(4, 4))
clean_image = knn_reg.predict(sample_x_modify)
plot_figures(np.concatenate([(sample_x_modify[i], sample_y_modify[i], clean_image[i]) for i in range(len(some_idx))]), images_per_row=3)
plt.savefig('figure/MNIST降噪效果')
plt.show()
练习题
1.在测试集上达到97%正确率
使用 sklearn.neighbors.KNeighborsClassifier 获得MNIST数据集在测试集上超过 的正确率. 通过对 weights, n_neighbors 进行网格搜素度.
n_neighbors默认值为 ,表示分类的个数.weights表示每个类中点对质心权重的计算方法:uniform权重全部为1,distance权重与到质心距离的反比相关.
from sklearn.model_selection import GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
params_grid = [
{'weights': ['uniform', 'distance'], 'n_neighbors': list(range(5, 11))},
]
knn_clf = KNeighborsClassifier()
grid_search = GridSearchCV(knn_clf, params_grid, cv=5, scoring='accuracy', verbose=2, error_score='raise')
grid_search.fit(train_x, train_y)Fitting 5 folds for each of 12 candidates, totalling 60 fits
[CV] END .....................n_neighbors=5, weights=uniform; total time= 22.4s
[CV] END .....................n_neighbors=5, weights=uniform; total time= 21.2s
[CV] END .....................n_neighbors=5, weights=uniform; total time= 22.0s
...
[CV] END ...................n_neighbors=10, weights=distance; total time= 20.4s
[CV] END ...................n_neighbors=10, weights=distance; total time= 22.8s
[CV] END ...................n_neighbors=10, weights=distance; total time= 21.0s
from sklearn.metrics import accuracy_score
print("最佳参数:", grid_search.best_params_)
print("最佳准确率:", grid_search.best_score_)
best_knn_clf = grid_search.best_estimator_
test_predict = best_knn_clf.predict(test_x)
print("测试集准确率:", accuracy_score(test_y, test_predict))最佳参数: {'n_neighbors': 6, 'weights': 'distance'}
最佳准确率: 0.9712333333333334
测试集准确率: 0.9709
2. 数据增强
通过对原式数据集进行一个上下左右一个像素的平移后,对模型进行训练.
from scipy.ndimage.interpolation import shift
def shift_image(image_vector, direction):
image = image_vector.reshape(28, 28)
shift_image = shift(image, direction, cval=0)
return shift_image.reshape(-1)
sample_x_shifted = shift_image(train_x[0], [0, 10])
plot_figures([train_x[0], sample_x_shifted])
def shift_image_dataset(dataset, direction):
dataset_shifted = np.apply_along_axis(func1d=shift_image, axis=1, arr=dataset, direction=direction)
return dataset_shifted
train_x_shifted = train_x.copy()
train_y_shifted = train_y.copy()
for direction in ([0, 1], [0, -1], [1, 0], [-1, 0]):
train_x_shifted = np.concatenate([train_x_shifted, shift_image_dataset(train_x, direction)], axis=0)
train_y_shifted = np.concatenate([train_y_shifted, train_y], axis=0)
print(train_x_shifted.shape, train_y_shifted.shape)(300000, 784) (300000,)
# 用时约为2min,可以看到正确率提高了0.7%
from sklearn.model_selection import cross_val_score
knn_clf= KNeighborsClassifier(**grid_search.best_params_)
knn_clf.fit(train_x_shifted, train_y_shifted)
print('测试集准确率:', accuracy_score(test_y, knn_clf.predict(test_x)))测试集准确率: 0.9772
后面两道练习题请见github代码,第三题完成,但第四题难度较高没有完整实现.