常用命令及函数
最新更新于: 2025年9月11日下午4点22分
Linux
下述简写分别表示:CMD 命令,PATH 路径,FILE 文件,FOLD 文件夹.
通用命令
man CMD # 显示CMD的帮助文档路径处理
pwd # 显示当前路径
cd PATH # 进入到PATH中
ls # 显示当前目录下的所有文件
ls -al # 显示当前目录下所有文件的详细信息
mkdir FOLD # 在当前目录下创建名为'目录名'的文件夹
vim FILE # 如果存在文件名的文件,则会使用vim编辑器打开,若不存在则会创建该文件
cp FILE1 FILE2 # 复制文件1到文件2,可以在文件名前面加上路径,则会复制到指定路径当中
rm FOLD1 # 删除文件1
mv FILE1 FILE2 # 剪切文件1到文件2文件下载压缩解压
.tar.gz 结尾的一般程序安装包,.zip 为一般压缩包.
wget -cO FILE 'URL' # 下载URL中文件,命名为FILE
zip -r FILE.zip /FOLD # 压缩/FOLD到FILE.zip
unzip FILE.zip # 解压FILE.zip
unzip -d /FOLD FILE.zip # 解压FILE.zip到FOLD目录下
tar -xf FILE.tar.gz # 解压.tar.gz压缩包使用编译安装
如果安装的文件是github上的项目,一般有后缀为 .tar.gz 的安装包,使用 weget 下载路径 或者在本机上下载下来后再使用WinSCP上传上去也行,这里以安装 ncurses 为例:
wget http://ftp.gnu.org/gnu/ncurses/ncurses-6.3.tar.gz " 下载安装包
tar -xf ncurses-6.3.tar.gz " 解压压缩包
cd ncurses-6.3/ " 进入到刚刚解压出的目录中
./configure --prefix=$HOME/apps/ " 设置安装目录为 $HOME/apps/ 文件夹下
make -j && make install " 编译并安装程序一键Tmux分屏脚本
服务器上的tmux脚本,创建三个窗口,效果如下图所示,并且每个窗口初始化bash source ~/.bashrc.
由于服务器上一般要用后台运行神经网络训练程序,而且每次新的界面要重新 scoure ~/.bashrc,所以我创建了一个一键创建tmux分屏窗口并运行 source 指令,可大幅提高效率.
使用方法,在用户目录(随便一个方便的目录)下创建 run.sh 文件,将下面代码贴进去,然后使用 chmod 777 run.sh 修改权限,以后启动服务器后,输入下面代码就能直接启动tmux进行分屏
./run.sh # 想启动新的tmux窗口
# 若已有tmux后台
source .bashrc # 先加载bash配置
tmux a # 即可启动tmux窗口
# 将tmux放到后台
# 快捷键 tmux组合键+d,tmux组合键默认为 Ctrl+b#!/bin/bash
source ~/.bashrc
# 创建seesion名称为mywork,默认创建第一个pane名称也为mywork
tmux new -d -s mywork
tmux split-window -h -t mywork # 横向分割,mywork到右侧
tmux split-window -v -t mywork # 竖向分割,mywork到底部
tmux send -t mywork "source ~/.bashrc" ENTER # 向mywork窗口发送source命令
tmux send -t "1" "source ~/.bashrc" ENTER
tmux send -t "2" "source ~/.bashrc" ENTER
# 连接上tmux会话,显示界面
tmux a -t mywork
格式化及挂载硬盘
查看存储分区
sudo lsblk -f 查看当前存储设备及分区,例如:
agx@ubuntu:~$ sudo lsblk -f
NAME FSTYPE FSVER LABEL UUID FSAVAIL FSUSE% MOUNTPOINTS
loop0 vfat FAT16 L4T-README 1234-ABCD 15.8M 1% /media/agx/L4T-README
loop1 squashfs 4.0 0 100% /snap/snapd/25205
loop2 squashfs 4.0 0 100% /snap/core22/2115
loop3 squashfs 4.0 0 100% /snap/bare/5
loop4 squashfs 4.0 0 100% /snap/gtk-common-themes/1535
loop6 squashfs 4.0 0 100% /snap/gnome-42-2204/201
mmcblk0
├─mmcblk0p1 ext4 1.0 f248f34f-6716-4f61-8ca4-8e499d9f8cc5 41.5G 22% /
├─mmcblk0p2
├─mmcblk0p3
├─mmcblk0p4
├─mmcblk0p5
├─mmcblk0p6
├─mmcblk0p7
├─mmcblk0p8
├─mmcblk0p9
├─mmcblk0p10 vfat FAT32 6F63-0441 62.9M 0% /boot/efi
├─mmcblk0p11
├─mmcblk0p12
├─mmcblk0p13
├─mmcblk0p14
└─mmcblk0p15
mmcblk0boot0
mmcblk0boot1
zram0 [SWAP]
zram1 [SWAP]
zram2 [SWAP]
zram3 [SWAP]
zram4 [SWAP]
zram5 [SWAP]
zram6 [SWAP]
zram7 [SWAP]
nvme0n1 ext4 1.0 5e2bf689-2d1d-4423-8332-d6e464aca50b 我这里就是 nvme0n1 硬盘,系统类型为 ext4,UUID为 5e2bf689-2d1d-4423-8332-d6e464aca50b
格式化硬盘
如果硬盘是全新的,则要进行格式化。如果之前已经将硬盘挂载了,则先要停止挂载,然后格式化,例如我现在已经挂载在 /mnt/ssd 上,打算格式化为 ext4 格式:
# 如果没有挂载,直接开始格式化即可
sudo umount /dev/nvme0n1
# 如果提示 umount: /*: target is busy 的报错,则通过下面代码来看当前有什么程序或终端正在使用该目录
sudo lsof +D /mnt/ssd
# 停止挂载后, 开始格式化
sudo mkfs.ext4 /dev/nvme0n1
mke2fs 1.46.5 (30-Dec-2021)
/dev/nvme0n1 contains a ext4 file system labelled 'data'
last mounted on /home/agx/data on Thu Sep 11 03:25:41 2025
Proceed anyway? (y,N) y
Discarding device blocks: done
Creating filesystem with 250051158 4k blocks and 62513152 inodes
Filesystem UUID: 5e2bf689-2d1d-4423-8332-d6e464aca50b
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968,
102400000, 214990848
Allocating group tables: done
Writing inode tables: done
Creating journal (262144 blocks): done
Writing superblocks and filesystem accounting information: done设置自动挂载
这里我打算将 nvme0n1 自动挂载到 /mnt/ssd 文件夹上,先创建文件夹,
sudo mkdir /mnt/ssd修改 /etc/fstab 文件如下(可以先另存下避免修改错误 sudo cp /etc/fstab /etc/fstab.backup):
/dev/root / ext4 defaults 0 1
UUID=6F63-0441 /boot/efi vfat defaults 0 1
# 新增了下面这一行
UUID=5e2bf689-2d1d-4423-8332-d6e464aca50b /mnt/ssd ext4 defaults 0 2启动挂载
sudo mount -a如果没有报错就说明挂载成功了,查看是否挂载成功:
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mmcblk0p1 57G 13G 42G 23% /
tmpfs 31G 120K 31G 1% /dev/shm
tmpfs 13G 51M 13G 1% /run
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
/dev/mmcblk0p10 63M 110K 63M 1% /boot/efi
tmpfs 6.2G 232K 6.2G 1% /run/user/1000
/dev/loop0 16M 112K 16M 1% /media/agx/L4T-README
/dev/nvme0n1 938G 71G 820G 8% /mnt/ssd # 成功挂载最后修改下权限即可 sudo chown $USER:$USER /mnt/ssd
Python 常用函数
re 和 fnmatch
re是用于表示正则表达式,而fnmatch是用于处理shell样式通配符. 更多正则表达式内容可以参考 regex101,该网页还能解释给出的正则表达式非常智能.
pattern = re.compile(pattern):编译正则表达式pattern.pattern.search(string):在string中搜索pattern所包含的第一个正则表达位置及长度.pattern.findall(string): 在string中搜索每一个pattern匹配得到的串.
fnmatch.translate(pattern):将shell样式通配符转化为正则表达式.fnmatch.fnmatch(string, pattern):判断pattern是否匹配字符串string.
shell样式通配符比较简单常用:
- ‘*’: 匹配任意数量的字符,包括零字符.
- ‘?’: 匹配任何单个字符.
- ‘[sequence]’: 匹配任意字符序列.
- ‘[!sequence]’: 匹配任何非顺序的字符.
# 一些ChatGPT举的例子
print(fnmatch.fnmatch("test.txt", "*.txt")) # prints True
print(fnmatch.fnmatch("test.txt", "test*")) # prints True
print(fnmatch.fnmatch("test.txt", "*.doc")) # prints False
# *[0-9]* 匹配包含数字的字符串下述内容来自ChatGPT:
shell样式的通配符模式是一种用于匹配文件名或路径名的模式,它可以包含特殊字符,如'*', '?', '[sequence]'. 这些特殊字符在shell样式通配符模式中具有特定的含义,它们分别用于匹配任意数量的字符、任意单个字符或给定序列中的任意字符. 另一方面,正则表达式是一种用于匹配字符串的模式,它可以包含广泛的特殊字符和语法元素,允许您指定用于匹配字符串的复杂模式. 正则表达式比shell样式的通配符模式更强大、更灵活,但它们也更难以阅读和理解。
另一方面,正则表达式是一种用于匹配字符串的模式,它可以包含广泛的特殊字符和语法元素,允许您指定用于匹配字符串的复杂模式。正则表达式比shell样式的通配符模式更强大、更灵活,但它们也更难以阅读和理解。
下面是一些shell样式通配符模式和等价正则表达式模式的例子:
| Shell-style wildcard pattern | Regular expression pattern |
|---|---|
*.txt |
.*\.txt |
test* |
test.* |
[0-9]* |
[0-9].* |
warning
自定义 warning 信息,用于给出警告,但是默认的 warning 输出信息非常丑陋,难以识别,在文件开头处加上以下代码
import warnings
def custom_warning_message(message, category, filename, lineno, file=None, line=None):
return '%s, line %s,\n%s\n\n' % (filename, lineno, message)
warnings.formatwarning = custom_warning_message使用方法 warnings.warn('警号信息'),一个例子:
warnings.warn(f"\
Warning: {self.model_name}'s {self.data_name} \
dataset don't have 'epoch_sizes.json' file, \
default by 1")效果:(可以给出warning的文件路径、行号、warning信息)
/home/wty/Coding/GitHub/RL-framework/utils/logs_manager.py, line 366,
Warning: /home/wty/Coding/GitHub/RL-framework/logs/DQN-1's history-0002 dataset don't have 'epoch_sizes.json' file, default by 1pathlib
-
pathlib.Path(directory):directory为文件的路径,返回pathlib.Path对象,该对象存储的为directory这条路径. -
pathlib.Path.cwd():cwd为Current working directory的缩写,即返回当前运行程序所在的目录. -
pathlib.Path.glob(pattern):pattern是一个shell类型的通配符(shell-style wildcard pattern),则该函数会返回该路径下所有符合该pattern的文件路径. 如*.py就会返回全体以.py为后缀的文件,*可以理解为任一的一个前缀(文件名). -
path.mkdir(parents=True, exist_ok):path为pathlib.Path对象即当前创建目录的路径,parents=True若父目录不存在,则创建父目录;exist_ok=True若当前目录不存在时才会进行创建,不会抛出异常. -
path.is_file():判断path是否是文件. -
path.is_dir():判断path是否是文件夹.
from pathlib import Path
Path.cwd() # 当前工作路径
Path.home() # home路径
fname = r'D:\fold1\fold2'
path = Path(fname)
folds = [f for f in path.iterdir() if f.is_dir()] # 获取path下的全部文件夹路径
files = [f for f in path.iterdir() if f.is_file()] # 获取path下的全部文件路径
files[0].name # 返回文件的名称(前缀)
files[0].suffix # 返回文件的名称(后缀)
path.parent # 父级目录
path.joinpath(fold[0].name) # 进入子文件夹路径urllib
用于文件下载,主要使用 urllib.request.urlretrieve(url, path) 对url链接进行下载,下载到 path 路径下. 一般与 tarfile 一同使用.
tarfile
用于解压 .tgz, .tar.bz2 文件.
path = '文件路径'
tgz = tarfile.open(path) # 创建文件路径
tgz.extractall(path=path) # 将文件解压到path
tgz.close()from pathlib import Path
import tarfile
import urllib.request
DOWNLOAD_ROOT = "https://spamassassin.apache.org/old/publiccorpus/" # 下载源的根路径
HAM_URL = DOWNLOAD_ROOT + "20030228_easy_ham.tar.bz2" # 下载文件的url链接
SPAM_URL = DOWNLOAD_ROOT + "20030228_spam.tar.bz2"
SPAM_PATH = Path.cwd().joinpath("datasets/spam") # 本地保存路径
def fetch_spam_data(ham_url=HAM_URL, spam_url=SPAM_URL, spam_path=SPAM_PATH): # 自义下载函数
spam_path.mkdir(parents=True, exist_ok=True) # 若文件夹不存在,创建文件夹
for filename, url in (("ham.tar.bz2", ham_url), ("spam.tar.bz2", spam_url)): # 设定保存的文件名和对应的url
path = spam_path.joinpath(filename) # 文件保存的位置
if not path.exists(): # 若文件以存在,则不重复下载
urllib.request.urlretrieve(url, path) # 文件下载
tar_bz2_file = tarfile.open(path) # 创建解压tarfile实例
tar_bz2_file.extractall(path=spam_path) # 解压文件到指定目录下
tar_bz2_file.close() # 关闭解压实例
fetch_spam_data()datatime
主要是处理时间字符串所用.
- 时间字符串读入:
data = datetime.strptime(string, time_format),将格式化时间信息字符串string根据格式time_format转化为datatime时间格式.
例如time_format = '%Y-%m-%d %H:%M:%S',则可以读入类似2157-11-21 03:16:00的年份. 具体time_format格式请见下面折叠内容. - 获取两个时间的相对天数:
relative_days = (data1 - data2).days - 获取两个时间的相对秒数:
relative_seconds = (data1 - data2).seconds(不足一天的则化为秒计算)
通过24 * relative_days + relative_seconds / 3600即可求出相对小时数.
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身matplotlib
import matplotlib as mpl
import matplotlib.pyplot as plt显示中文
只需将下述配置放置在包导入之后即可,有以下两种配置方案,第一个使用的是宋体,更加正规;第二个使用的是黑体,也很清晰好用,推荐第二种。
config = {
"font.family": 'serif', # 衬线字体
"figure.figsize": (6, 6), # 图像大小
"font.size": 14, # 字号大小
"font.serif": ['SimSun'], # 宋体
"mathtext.fontset": 'cm', # 渲染数学公式字体
'axes.unicode_minus': False # 显示负号
}
plt.rcParams.update(config)
config = { # 另一种配置
"figure.figsize": (8, 6), # 图像大小
"font.size": 16, # 字号大小
"mathtext.fontset": 'cm', # 渲染数学公式字体
"font.sans-serif": ['SimHei'], # 用黑体显示中文
'axes.unicode_minus': False # 显示负号
}
plt.rcParams.update(config)绘图参数
绘图一般以以下顺序逐步进行,多次使用 plt.plot 后绘制的图像会覆盖之前绘制的图像.
plt.figure(figsize=(6, 4), dpi):创建长宽为6x4大小的幕布,在此基础上乘上单位分辨率dpi,即为图像分辨率.plt.plot(X, y, 'r-s', markersize=8, lw=2, label='SGD'):依(X, y)绘制二维图像,第三个参数用于控制图像属性,r表示红色,-表示直线,s表示方块点,markersize表示描点所用图形的大小(即方块的大小),lw是linewidth的缩写,用于调整线的宽度,label表示该图形的标签,需要使用plt.legend()显示标签. 以下为几种常用图像属性:'r-s'红色,直线,方块描点.'g--^'绿色,虚线,上三角描点.b.蓝色,散点图.r:红色,虚线.
plt.legend(loc=None):显示图例,loc表示固定图例位置,默认为自动选择适合的位置,常用位置有:upper left, lower right, center left ...plt.axis([x1, x2, y1, y2]):用于控制显示坐标系范围,横坐标限制在[x1, x2]范围内,纵坐标限制在[y1, y2]范围内.plt.xlabel("Xname"), plt.ylabel("Yname", rotation=0):设定x,y轴坐标名称,rotation表示逆时针旋转角度,由于y轴标签默认旋转90度,如果标签内容较少,建议不要旋转.plt.axhline(y=0, color='k'):以y=0绘制黑色竖线,表示y轴.plt.axvline(x=0, color='k'):以x=0绘制黑色竖线,表示x轴.plt.text(x, y, text, fontsize=16, ha='center', color='k'):在(x,y)点处以16号字体居中绘制黑色字符串text,ha表示字符串位置,默认为left.plt.tight_layout():在保存图像前,建议使用该api,可以将多余边界去除,使图像更美观,其具有参数w_pad, h_pad用于子图的宽度和高度的填充.plt.savefig("figure/fname.png", dpi=300):将图像保存到./figure/fname.png文件中,单位分辨率为dpi=300,如果figsize=(3,2)则输出图像的分辨率为900x600. 支持图片类型还有.jpg .pdf .svg.plt.show():显示图像,并关闭当前幕布,完成全部绘图.
结合以上方法进行绘图的例子:
import matplotlib.pyplot as plt
import numpy as np
from pathlib import Path
PATH_FIGURES = "./figures"
Path(PATH_FIGURES).mkdir(parents=True, exist_ok=True) # 若存储图片的文件夹不存在,则进行创建
np.random.seed(42)
m = int(1e5)
X_normal = np.random.randn(m, 1)
hists, bins = np.histogram(X_normal, bins=50, density=True)
bins = bins[:-1] + (bins[1] - bins[0]) / 2 # 取每个小区间的中位数
plt.figure(figsize=(8, 4))
plt.hist(X_normal, bins=50, density=True, alpha=0.8) # 绘制直方图,alpha为透明度
plt.plot(bins, hists, 'r--o', markersize=6, label="高斯采样")
plt.text(2.5, 0.3, r"$f(x) = \frac{exp\left(\frac{-x^2}{2}\right)}{\sqrt{2\pi}}$",
fontsize=25, ha='center', color='w', math_fontfamily='cm')
plt.axhline(y=0, color='k')
plt.axvline(x=0, color='k')
plt.axis([-4, 4, -0.02, 0.42])
plt.xlabel("$x$")
plt.ylabel("$P$", rotation=0)
plt.legend(loc='upper left')
plt.title("$10^5$个来自标准正态分布的样本")
plt.tight_layout()
plt.savefig(PATH_FIGURES + "normal_distribution_density_plot.png", dpi=300)
plt.show()
print("曲线下近似面积:", np.trapz(hists, bins)) # 0.9999800000000001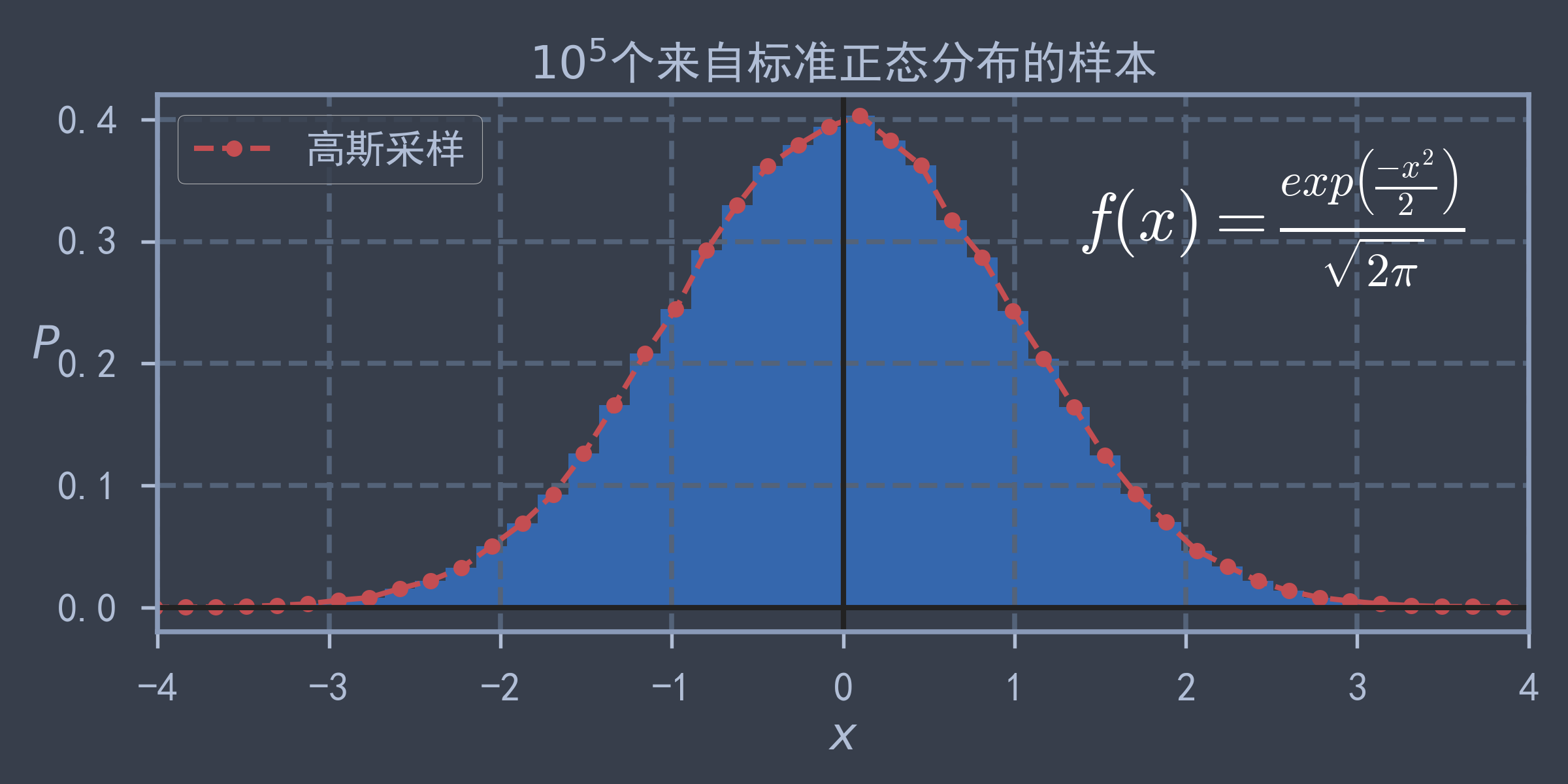
同时绘制多个图像
# 同时绘制多个图像
def plot_figures(instances, images_per_row=10, **options):
# 图像大小
size = 28
# 每行显示的图像,取图像总数和每行预设值的较小值
images_per_row = min(len(instances), images_per_row)
# 总共的行数,下行等价于 ceil(len(instances) / image_per_row)
n_rows = (len(instances) - 1) // images_per_row + 1
# 如果有空余位置没有填充,用空白进行填充
n_empty = n_rows * images_per_row - len(instances)
padded_instances = np.concatenate([instances, np.zeros([n_empty, size * size])], axis=0)
# 将图像排列成网格
image_grid = padded_instances.reshape([n_rows, images_per_row, size, size])
# 使用np.transpose对图像网格进行重新排序,并拉伸成一张大图像用于绘制
big_image = image_grid.transpose([0, 2, 1, 3]).reshape([n_rows * size, images_per_row * size])
plt.imshow(big_image, cmap='binary', **options)
plt.axis('off')
plt.tight_layout()
plt.figure(figsize=(6, 6))
plot_figures(train_x[:100])
plt.savefig('figure/MNIST前100张图像')
plt.show()
绘制等高线
等高线图主要有两种:
- 等高线填充背景:
plt.contourf(x1, x2, z, levels=levelz, cmap='viridis'):x1, x2为网格划分后的对应坐标,z对应网格点的高度值,levels表示等高线的划分点,在两个等高线之间的区域用同种颜色填充,cmap表示填充使用的颜色带.plt.colorbar(label):通过绘制颜色柱为等高线提供每种颜色对应的高度值.
- 绘制等高线:
contour = plt.contour(x1, x2, z, levels=levelz, cmap='viridis'):用法与plt.contourf类似,只不过是在对应levels处绘制等高线.plt.clabel(contour, fontsize=14, inline=True):使用plt.contour返回值,使用fontsize字号在等高线内绘制对应的高度.(inline默认为True,一般无需添加)
常用的
cmap选项:viridis, jet, rainbow, summer, autumn等.
plt.figure(figsize=(8, 5))
x1, x2 = np.meshgrid( # 创建离散网格点
np.linspace(-3.5, 3.5, 500),
np.linspace(-3, 3, 500)
)
# 计算高度值
z = np.exp(-((x1+1)**2 + x2**2) / 2) / (2 * np.pi) - np.exp(-((x1-1)**2 + x2**2) / 2) / (2 * np.pi)
# 设置等高线划分点,会根据情况绘制等高线,若没有相应的数据点,则不会进行绘制
levelz = (np.linspace(-0.1, 1.1, 17) * (z.max() - z.min()) + z.min()).round(2)
plt.contourf(x1, x2, z, levels=levelz, cmap='viridis') # 向由等高线划分的区域填充颜色
plt.colorbar(label='概率') # 制作右侧颜色柱,表示每种颜色对应的值
contour = plt.contour(x1, x2, z, cmap='jet', levels=levelz) # 绘制等高线
plt.clabel(contour, fontsize=14) # 在等高线上绘制对应高度值
plt.xlabel('$x_1$')
plt.ylabel('$x_2$', rotation=0)
plt.grid(False)
plt.tight_layout()
plt.savefig("figure/bivariate_normal_distribution_density_plot.png", dpi=300)
plt.show()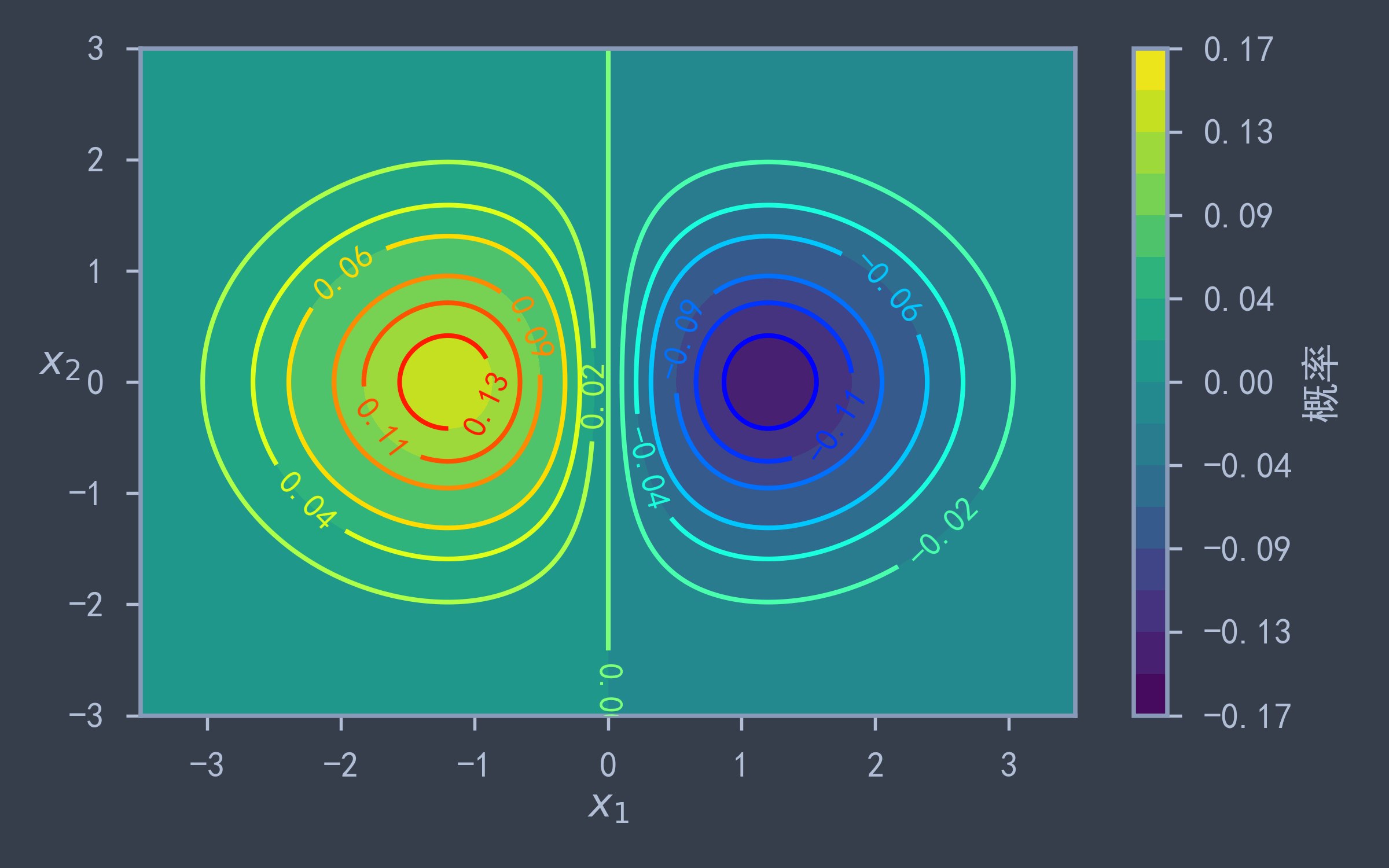
更多等高线的例子请见:训练线性模型 - 代码实现
多个子图共享图例,绘制均值+方差
子图绘制方法主要使用 fig, axs = plt.subplots(nrows, ncols, figsize=(w,h)) 进行图初始化,其中 fig 表示整幅图的实例化句柄,axs 是一个 np.ndarray 坐标系数组的实例化数组,满足 axs.shape=(nrows, ncols),ax=axs[i,j] 表示图中 行 列的子图对应的坐标系,本质上使用 plt.func 都是间接地调用 fig.func1 或 ax.func2 中的函数,func1, func2 的名称可能和 func 函数名有小部分差异,例如:
fig.tight_layout(...):等价于plt.tight_layout(...)fig.savefig(...):等价于plt.savefig(...)fig.legend(...):等价于plt.legend(...)ax.plot(...):等价于plt.plot(...)ax.set_xlabel(...):等价于plt.xlabel(...)ax.set_ylabel(...):等价于plt.ylabel(...)ax.set_xlim(...):等价于plt.xlim(...)ax.set_ylim(...):等价于plt.ylim(...)ax.set_xticks(...):等价于plt.xticks(...)ax.set_yticks(...):等价于plt.yticks(...)
想要制定图像绘制的子图,只需使用 axs[i,j].plot(...) 对曲线进行绘制(hist, bar 类似);图例的合并方法如下:
- 绘制均值曲线:
line, = ax.plot(x, y, label=label, c=color, lw=3),line能够将当前绘制的曲线记录下来,line.get_color()可获取其对应的颜色; - 绘制方差曲线范围:
ax.fill_between(x, y-stds, y+stds, color=line.get_color(), alpha=0.2),y-stds, y+stds分别为曲线范围的下边界与上边界,并保持颜色和中间绘制的均值曲线相同的,再加上0.2的透明度; handles, labels = ax.get_legend_handles_labels()可以从当前坐标系中绘制的曲线对应图例的句柄handles和句柄对应的图例名称labels(二者都是列表);- 图例共享:
fig.legend(handles, labels, loc='lower center', ncols=3, frameon=False),handles表示共享图例对应的句柄,labels表示图例句柄所对应的标签,loc表示图例的放置位置,ncols表示图例的列数(默认为1),frameon表示是否启用图例的边界框; - 由于直接绘制图例会导致和子图的下半部分重叠的问题,需要将子图向上进行平移,使用
fig.subplots_adjust(bottom=0.20)可以将底部向上扩展 20%(注意plt.tight_layout()要在其前调用)。
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'serif'
plt.rcParams['font.size'] = 20
np.random.seed(42)
fig, axs = plt.subplots(1, 2, figsize=(12, 5))
x = np.arange(-np.pi, np.pi+0.01, 0.01)
print(x.shape[0])
std_interval = 30
assert x.shape[0] % std_interval == 0, f"{x.shape[0]} should be {std_interval} times."
gauss_fn = lambda mu, sigma, x: np.exp(-0.5 * ((x-mu)/sigma)**2) / (sigma * np.sqrt(2 * np.pi))
handles, labels = [], []
for i, fn, label, color in zip([0,0,1], [np.sin, np.cos, np.tanh],
['sin', 'cos', 'tanh'], ['tab:red', 'tab:green', 'tab:blue']):
ax = axs[i]
y = fn(x)
std = np.random.randn(x.shape[0]) * 100
stds = np.zeros_like(x)
for j in range(x.shape[0]):
stds += gauss_fn(x[j], std[j], x)
line, = ax.plot(x, y, label=label, c=color, lw=3)
ax.fill_between(x, y-stds, y+stds, color=line.get_color(), alpha=0.2)
ax.set_xlim(-np.pi, np.pi)
ax.set_xticks([-np.pi, -np.pi/2, 0, np.pi/2, np.pi], ['$-\pi$', '$-\pi/2$', '$0$', '$\pi/2$', '$\pi$'])
for ax in axs:
hs, ls = ax.get_legend_handles_labels()
handles += hs; labels += ls
fig.legend(handles, labels, loc='lower center', ncols=3, frameon=False)
plt.tight_layout()
fig.subplots_adjust(bottom=0.20)
plt.savefig("subplot_and_merge_handles.png", dpi=300)
plt.show()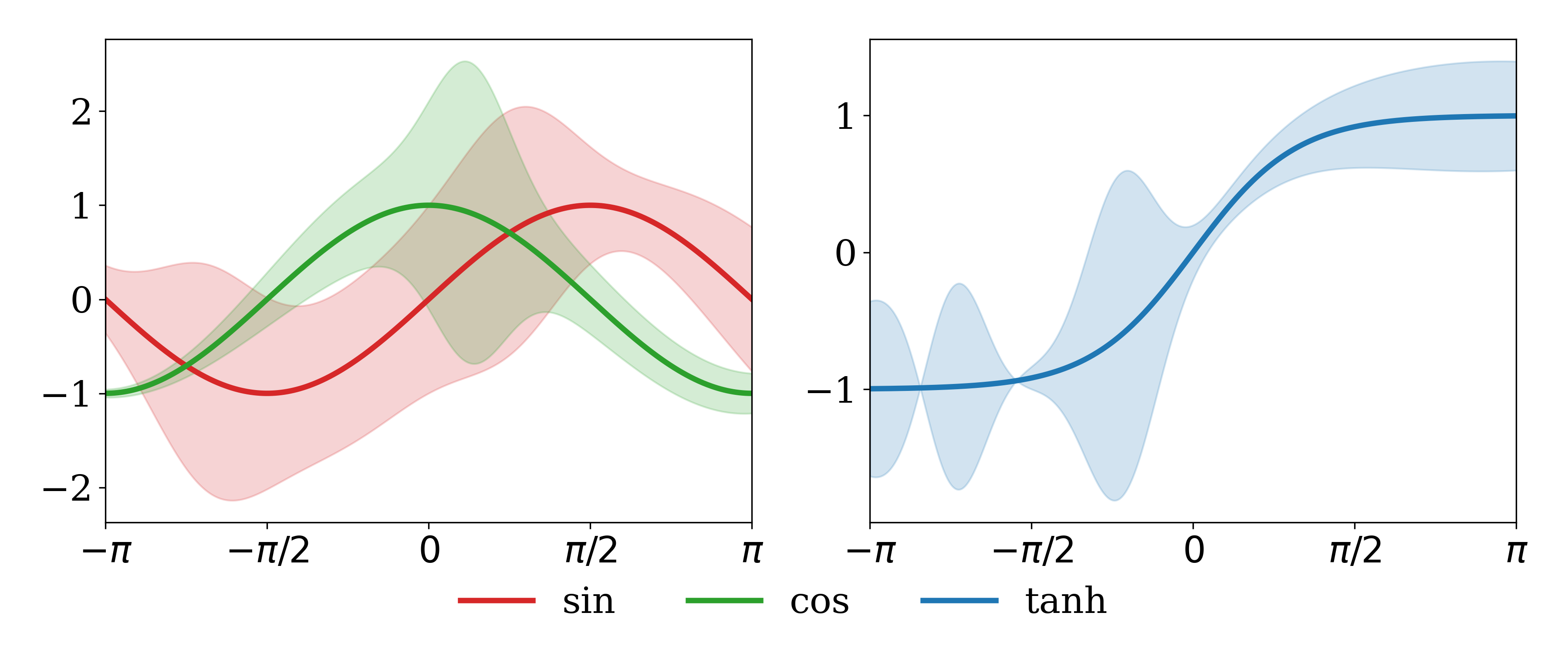
在坐标系上绘制箭头
通过ax.spines修改坐标轴的相关参数,用marker方式绘制箭头的头部。
import numpy as np
import matplotlib.pyplot as plt
config = {
"font.family": 'serif', # 衬线字体
"figure.figsize": (5, 5), # 图像大小
"font.size": 14, # 字号大小
"font.serif": ['SimSun'], # 宋体
"mathtext.fontset": 'cm', # 渲染数学公式字体
'axes.unicode_minus': False # 显示负号
}
plt.rcParams.update(config)
fig, ax = plt.subplots()
# 关闭默认坐标轴右侧和上侧的边框
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
# 将左侧和底侧的边框固定在零上, 设置线宽度为2
ax.spines['left'].set_position('zero')
ax.spines['left'].set_linewidth(2)
ax.spines['bottom'].set_position('zero')
ax.spines['bottom'].set_linewidth(2)
ax.xaxis.set_ticks_position('bottom')
ax.yaxis.set_ticks_position('left')
# 关闭刻度
ax.set_xticks([])
ax.set_yticks([])
# 设置显示(x_min, x_max, y_min, y_max)范围
ax.axis([0, 2, -2, 0])
# 设置箭头符号
ax.plot(2, 0, ls="", marker=">", ms=10, color="k", clip_on=False)
ax.plot(0, -2, ls="", marker="v", ms=10, color="k", clip_on=False)
eps = 0.2
ax.plot([0, 1-eps], [-1+eps, -1+eps], 'r', label=r"$\mathcal{L}^{CLIP}$", lw=4)
ax.plot([1-eps, 2], [-1+eps, -2], 'r', lw=4)
ax.plot([0, 2], [0, -2], 'b-.', label=r"$\mathcal{L}^{CLP}$", lw=2)
ax.plot([0, 1-eps], [-1+eps, -1+eps], 'g*-', label=r"$\text{clip}(\cdot)D$", clip_on=False, zorder=3, lw=2, ms=10)
ax.plot([1-eps, 1+eps], [-1+eps, -1-eps], 'g*-', lw=2, ms=10)
ax.plot([1+eps, 2], [-1-eps, -1-eps], 'g*-', clip_on=False, lw=2, ms=10)
ax.plot([1-eps, 1-eps], [0, -1+eps], 'k--', lw=1.5)
ax.plot([1, 1], [0, -1], 'k--', lw=1.5)
ax.plot([1+eps, 1+eps], [0, -1-eps], 'k--', lw=1.5)
ax.text(1-eps-0.08, 0.03, r"$1-\varepsilon$")
ax.text(1-0.02, 0.03, r"$1$")
ax.text(1+eps-0.08, 0.03, r"$1+\varepsilon$")
ax.text(2-0.02, -0.12, r"$\xi$")
fig.suptitle("$D<0$")
fig.legend(loc="lower center")
fig.tight_layout()
plt.savefig("ppo_D_neg.png", dpi=300)
plt.show()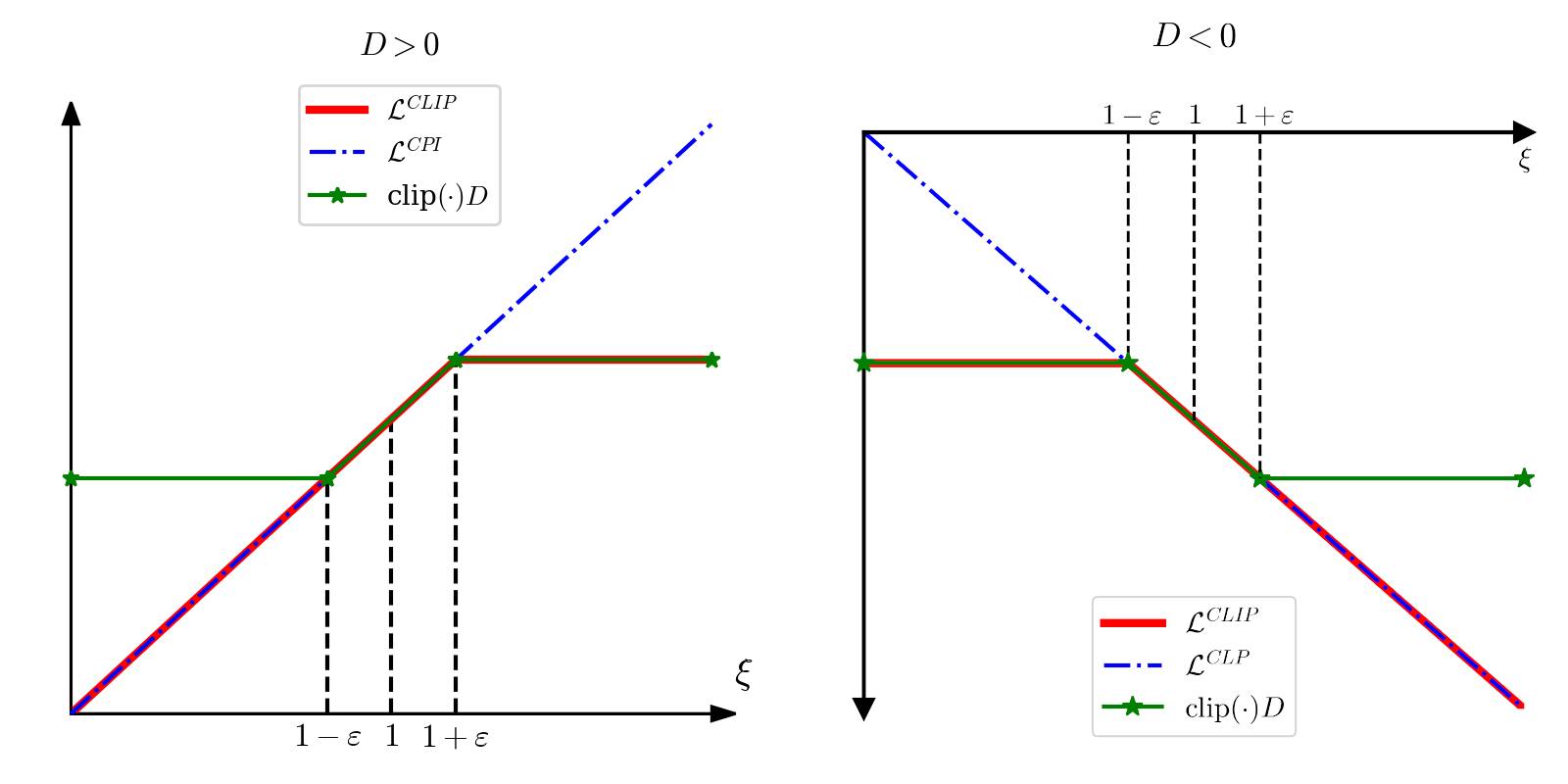
numpy
随机
np.random.permutation(n):生成1,...,n的随机排列.
pandas
pandas读取的文件类型为 pandas.core.frame.DataFrame 一般记为 df. 空单元格记为 None,是一种二维数组的形式,只不过可以通过索引获取元素值,索引分为两种,行与列:
- 行索引默认从0开始顺次编号,一般为数字;
- 列索引默认为原表格中的第0行的列名称,一般为字符串.
实参与形参:如果是单行单列的切片,则返回的数据类型为 pandas.core.series.Series,大部分api和 DataFrame 类似,而且是形参,做多行多列的切片返回的仍然是 DataFrame 数据类型,也是形参. 如果直接将 DataFrame 传入到函数中则是实参则是实参.
读取查找操作及修改行列索引
以下为读入 .csv 文件为例,若为 excel 表格(文件后缀为 .xls 或 xlsx)只需将 read_csv() 改为 read_excel().
-
df = pd.read_csv(path, header=0):从path路径中读取.csv文件,header=0表示以第0行作为列索引,若header=None则默认以序号作为列索引,数据内容从表格的第一行开始. -
获取列表元素有如下两种方式:
-
根据行索引与列索引进行查找,例如查找列索引为
col1索引为i对应的元素:df.loc[i, col1]. -
根据表格的相对位置进行查找(即将原表格视为二维数组进行查找),例如查找第
i行第j列的元素:df.iloc[i, j].切片的方法和通常做法相同,例如取出前100行:
df.iloc[:100],取出50到99行:df.iloc[50:100].
注:使用
iloc速度会比loc速度快非常多,处理较大表格时建议使用iloc.
- 修改行列的方法:
-
修改列名称有两种方法:
- 通过
df.columns = ['rename_col1', 'rename_col2', ...]直接修改列名称,此方法一般在对全部列名进行修改时使用. - 通过
df.rename(columns={'col1': 'rename_col1'})通过字典映射修改列名,此方法一般对部分列名进行修改时使用.
- 通过
-
设定行索引的方法:
df.set_index('col')以col列作为新的索引列. -
删除某个行或列的方法:
df.drop(['col1, col2', ...], axis=1)删除掉'col1', 'col2', ...列;df.drop([index1, index2, ...], axis=0)删除掉行索引为index1, index2, ...的行. 如果加上replace=True的参数,则会在原表格上进行操作,无需重新赋值.
可以使用 len(df) 获取行数,或者 df.shape 获取行与列数,使用 list(df) 可以方便地获得列索引.
如果想直接将DataFrame转化为numpy数组格式,则可以通过 df.values 获得.
但需要注意的是,如果
df中存在字符串,则df.values会转化为字符数组,需要自行转化数据格式.
查看数据结构
-
df.head(n=5):显示前n行内容,默认显示5行. -
df.info():显示文件相关信息,包括:列索引,每列Non-Null的个数,每列的数据类型. -
df.describe():显示数字列的相关信息,包括:行数,中位数,标准差,最小最大值,1/4,1/2,3/4分位数. -
df['col1'].value_counts():对第col1求去重后的元素个数(一般用于处理字符串数据). -
df.hist(bins=50, figsize=(18, 12):显示每一列的直方图结果,使用matplotlib.pyplot进行绘制成多个子图形式,使用plt.show()显示.
数据可视化
主要使用 df.plot 函数,以下为散点图使用方法.
df.plot(kind='scatter', x='col1', y='col2', alpha=0.1, s=df['col3'], c=df['col4'], cmap='jet', colorbar=False, xlabel=, ylabel=):kind='scatter'表示使用散点图进行绘制,以col1列作为x轴,col2列作为y轴,绘制散点图,每个点的透明度为alpha,每个点的大小为df['col3']控制,每个点的颜色由df['col4']控制,色彩分布使用jet类型,不显示色彩带colorbar=False,后面的参数为plt的常用参数配置,例如xlabel为x轴标签,等等.
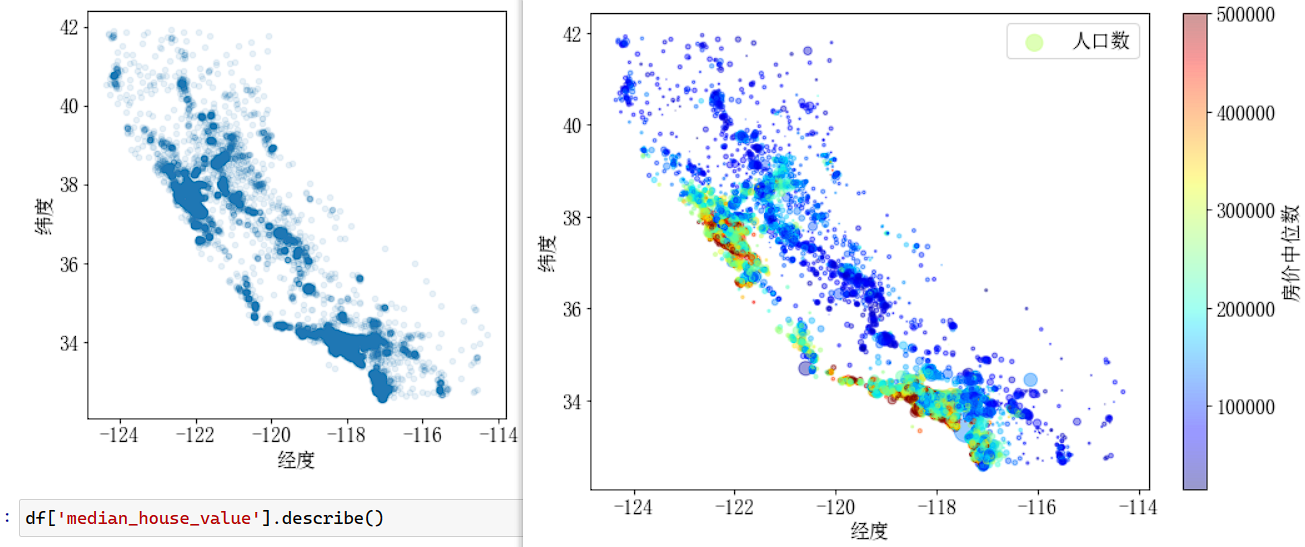
df.plot(kind='scatter', x='longitude', y='latitude', alpha=0.1, xlabel='经度', ylabel='纬度', figsize=(6, 6))
plt.show() # 左图
import matplotlib as mpl
ax = df.plot(kind='scatter', x='longitude', y='latitude', alpha=0.4,
s=df['population']/100, label='人口数', figsize=(10, 7),
c='median_house_value', cmap=plt.get_cmap('jet'), colorbar=False,
xlabel='经度', ylabel='纬度') # 这里不使用pandas自带的colorbar显示,因为有bug,显示后x轴标签无法显示
ax.figure.colorbar(plt.cm.ScalarMappable( # 自定义colorbar的显示效果
norm=mpl.colors.Normalize(vmin=df['median_house_value'].min(), vmax=df['median_house_value'].max()), cmap='jet'), # 设定色彩范围
label='房价中位数', alpha=0.4) # 设定colorbar的标签和透明度,保持和pandas绘制时相同即可
plt.legend()
plt.show() # 右图相关性分析
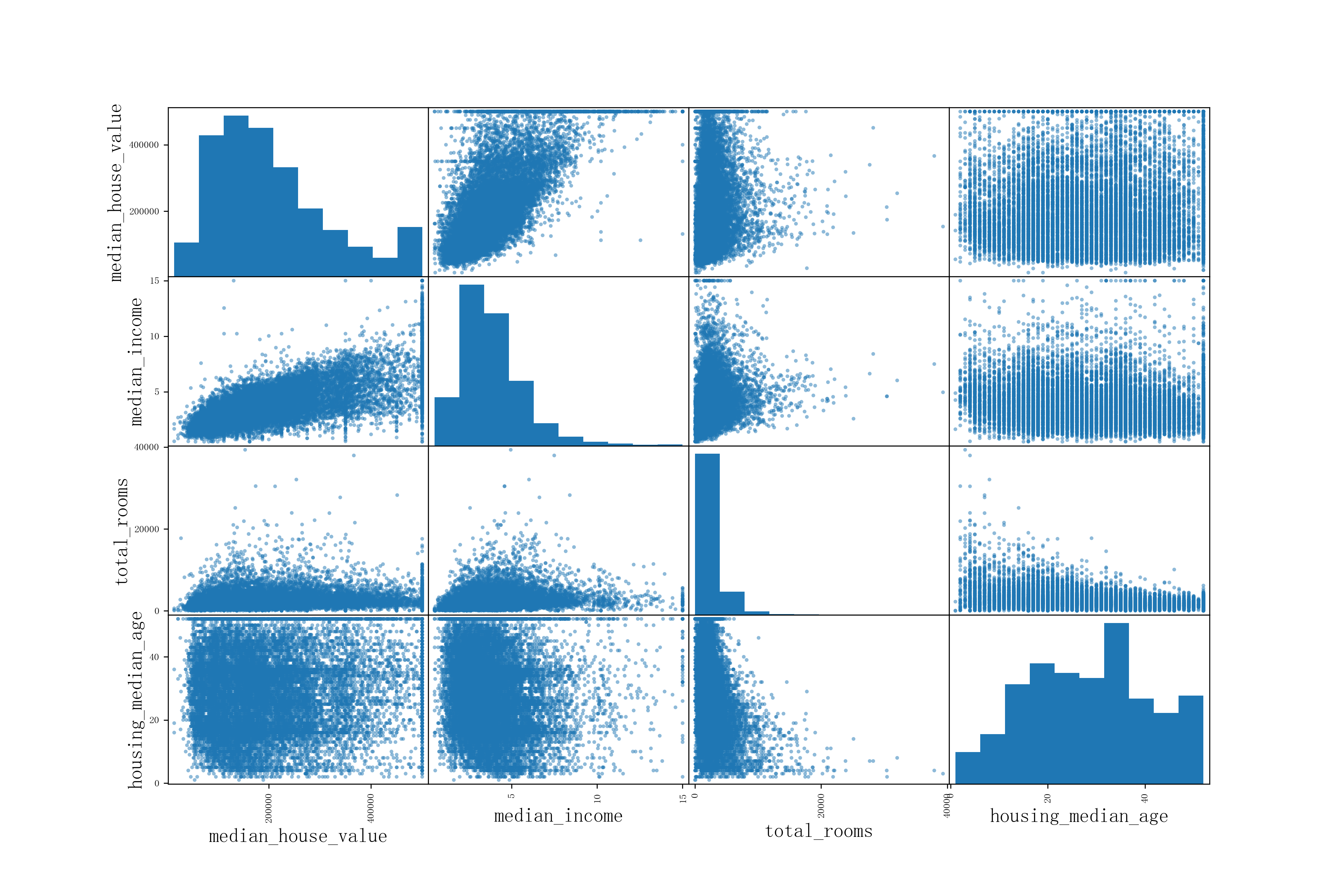
-
计算相关系数矩阵:
df.corr(),返回每个数值列与数值列之间的相关系数值.(wikipedia上相关性介绍) -
绘制散点图矩阵
scatter_matrix(df[attributes]),其中attributes为要显示的列索引,将每列与每列之间绘制散点图,可视化两两数据之间的相关性.
数据处理
-
df.reset_index(drop=False):重新对列表的索引值进行设置,从0开始一次递增,若drop=False则保留原索引为index列,默认保留,若为drop=True则不保留.(该api也可用于创建索引列) -
df.value_counts():统计每种值出现的个数. -
pd.cut(df['col1'], bins=[a1,a2,...,a9], labels=[1,2,...,8]):对df['col1']列按照(a1,a2], (a2,a3], ..., (a8, a9]划分为 段,每一段均为左开右闭,第i段的标签记为i(默认标签为这一段的数值范围). -
df.apply(function, args=(arg1, ...), **kargs, axis=0):对表格df中的每一行切片提取出来,传入到function函数中进行处理,如果function函数有其他参数,则切片为第一个传入参数,后面的无初始化值的参数可以通过args传入,而有初始化参数可以直接传入参数及其对应的值,默认放到function函数中. 可以参考下图:
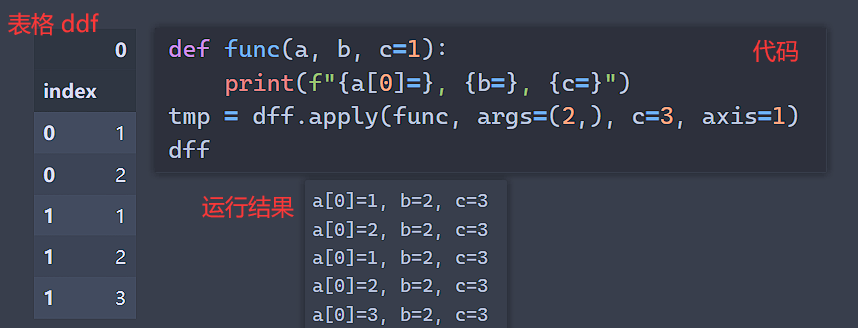
注:apply处理每行的信息速度要比逐个遍历每行做切片速度快得多.
-
df.grouby('col').apply(function):对表格df中的'col'列相同元素进行提取,然后传入到function函数中进行处理. 适用于具有连续性数据处理,满足某种性质的数据均具有某个相同的属性值. -
df.drop_duplicates():对行进行去重,完全相同的行会只保留一个. -
df1.merge(df2, how='outer', on=['col1']):将表格df1, df2进行外合并,on=['col1']表示以col1列作为每行的基准值(可以有多个基准值,例如['col1', 'col2'],默认以行索引作为基准值)逐行进行合并,how='outer'时为外合并,即对于两个表格中的全部基准值,相同基准值则会进行合并,不同基准值会用None填补,如果有多个相同基准值,则会添加额外的列显示;how='inner'时为内合并,即只对两个表格中同时具有的基准值进行合并,如果某个基准值仅在一个表格中出现,则会将其丢弃. -
df.sort_values('col', ascending=True):表示将表格中的每行按照'col'列的元素递增形式进行排序,若ascending=False则以递降形式进行排序.
数据清理
处理缺失的特征,有如下三种选择:
-
丢弃缺失值对应的整行:
df.dropna(axis=0, subset=None),axis=0表示清除规则为按行清除,subset可以指定清除某一列的缺失值,默认为行清除,清除整个表格中的全部缺失值. -
丢弃缺失值对应的整列:
df.dropna(axis=1). -
将缺失值补全为某个值(0、平均数或中位数等):例如,按0补全
df['col1'].fillna(0)
如此操作可能对于新数据处理不方便,因为可能出现新的列有缺失值,而上述补全方式不适用于对于新的一列进行补全,所以使用Scikit-Learn中的SimpleImputer方式可以更好的进行数据补全,参见另一篇文章Scikit-Learn SimpleImputer类
dask
dask是一个支持对numpy,pandas高效并行处理的包,常用于处理超大文件,可以分块处理超大表格.
由于dask的使用方法和numpy,pandas类似,只需将 np.array 改为 dask.Array,pd.DataFrame 改为 dask.DataFrame,而且在操作命令上都基本相同,只不过并不会根据命令立刻执行操作,而是会产生一个延迟包 dask.delayed,会将操作的结果的框架返回,而不会计算出具体的数值,只有在操作的最后加上 .compute() 命令才会执行计算.
使用 dask.diagnostics.ProgressBar 包裹计算的命令即可显示处理的进度条:
from dask.diagnostics import ProgressBar
with ProgressBar():
out = delayed.compute()DataFrame
import dask.dataframe as dd 读入包,读入到 dask.dataframe 之后的处理,与pandas基本完全一致,只需最后在计算时加上 .compute() 即可.
-
文件读取:
ddf = dd.read_csv(file_path, dtype=None),dask会根据每列的第一个数据对一整列的数据类型进行猜测,如果后续出现不同的数据类型,则会报出错误,会给出推荐的dtype类型指定,只需将其给出的建议加入到dtype参数位置即可. -
通过
pd.DataFrame转化:ddf = dd.from_pandas(df, npartitions=32),从df转化为dask.DataFrame文件,划分为npartitions个块. -
文件保存:
ddf.to_csv(save_path, single_file=True),保存也和pandas类似,但是如果直接调用保存api,则会根据划分的块,保存出多个文件,如果希望单个文件保存,可使用single_file=True.
cv2
绘制滑动窗口
from skimage import transform
import cv2
im = cv2.imread(r'mini_fox.jpg')
downscale=1.5 # Guass金字塔以1.5倍进行缩放
def sliding_window(im, window_size, step_size):
for x in range(0, im.shape[0], step_size[0]):
for y in range(0, im.shape[1], step_size[1]):
yield x, y, im[x:x+window_size[0], y:y+window_size[1]]
# Gauss金字塔
for i, im_scaled in enumerate(transform.pyramid_gaussian(im, downscale=downscale, channel_axis=-1)):
# 滑动窗口
for x, y, im_window in sliding_window(im_scaled, (30, 100), (30, 10)):
if im_window.shape[0] != 30 or im_window.shape[1] != 100:
continue
clone = im_scaled.copy() # 在原图上重新绘制
cv2.rectangle(clone, (y, x), (y + 100, x + 30), (255,255,255), thickness=2) # 绘制窗口
cv2.imshow(f"Sliding Window {im_scaled.shape}", clone) # 显示窗口
cv2.waitKey(20) # 控制每帧长度
cv2.waitKey()
实时保存mp4视频
import cv2
import subprocess
import numpy as np
from pathlib import Path
np.random.seed(42)
USE_MP4V = False
### Create video writer
fps = 30
width, height = 540, 360
if USE_MP4V: # 文件更小, 如果创建过程中中止可能出现花屏
path_video = Path("./logs/test.mp4")
writer = cv2.VideoWriter(str(path_video), cv2.VideoWriter_fourcc(*'mp4v'), fps=fps, frameSize=(width, height))
else: # 文件稍微大, 如果创建过程中中止不会出现问题
path_video = Path("./logs/test.avi")
writer = cv2.VideoWriter(str(path_video), cv2.VideoWriter_fourcc(*'XVID'), fps=fps, frameSize=(width, height))
duration_sec = 3
total_frames = duration_sec * fps
update_freq = 30
img = np.zeros((height, width, 3), dtype=np.uint8)
delta = np.ones((1, 1, 3), dtype=np.int32)
scale = 5
for i in range(total_frames):
# Write image (RGB -> BGR)
writer.write(img[..., ::-1])
img = np.clip(img + delta * scale, 0, 255).astype(np.uint8)
if i % update_freq == 0:
delta = np.random.randint(-1, 2, size=(1, 1, 3), dtype=np.int32)
# Release writer
writer.release()
# Option: Use ffmpeg to compress video into mp4, for example: 202.8kB -> 7.3kB
subprocess.run(['ffmpeg', '-y', '-i', str(path_video), str(path_video.with_stem(path_video.stem+'_small').with_suffix('.mp4'))])生成效果:
Nvidia显卡信息查看
nvidia-smi # 显示显卡相关信息
watch -n 1 nvidia-smi # 以1s刷新显卡使用情况,持续观察显卡使用情况Scikit-Learn
TensorFLow
Jax+Flax+Optax
请见 Jax+Flax+Optax 学习笔记,Jax+Flax+Optax 常用API
tensorboard 和 wandb 使用方法
请见 Jax+Flax+Optax 学习笔记 - 利用tensorboar和wandb可视化训练过程
ffmpeg
请见 ffmpeg常用命令