本科毕设《基于非嵌入式强化学习的卡牌游戏AI研究》相关技术
最新更新于: 2024年6月18日上午10点14分
代码:KataCR,图像数据集(切片图像,分类图像):Clash-Royale-Detection-Dataset,离线数据集:Clash-Royale-Replay-Dataset
本文主要对我的本科毕设流程、算法细节进行简要介绍,首先给出本科毕设论文作为参考(有非常多冗余内容):
英文论文(投稿到 ICIRA 2024):
结题答辩PPT:
本文将按照论文讲解的顺序进行介绍:生成式目标识别数据集,图像感知融合,决策模型设计。
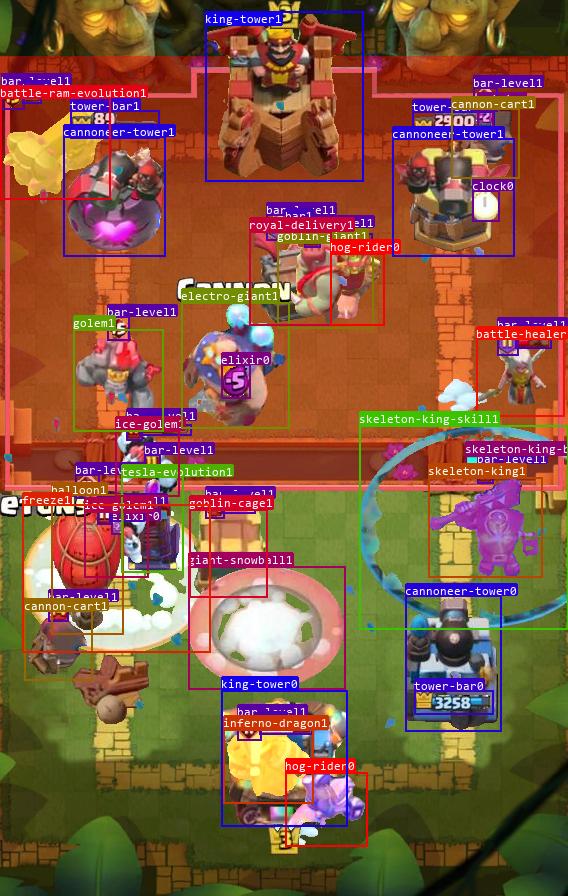
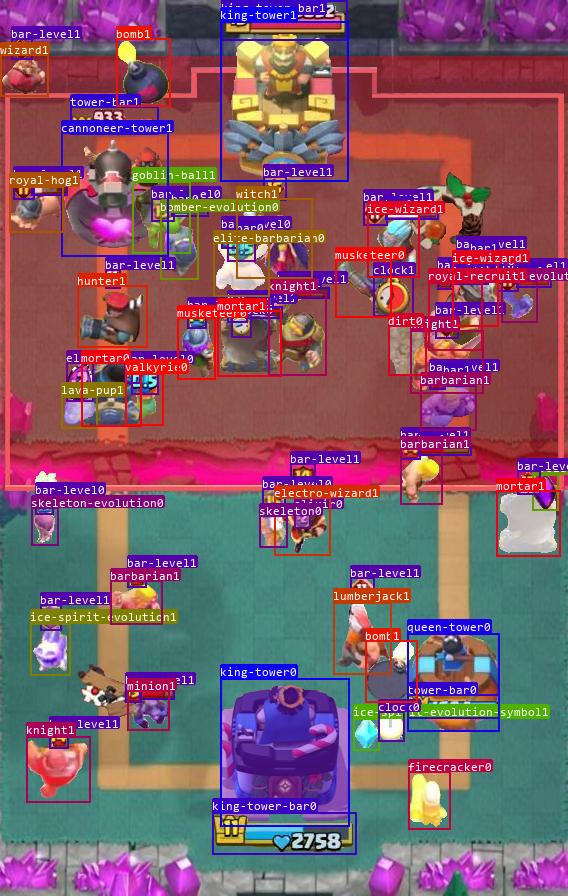
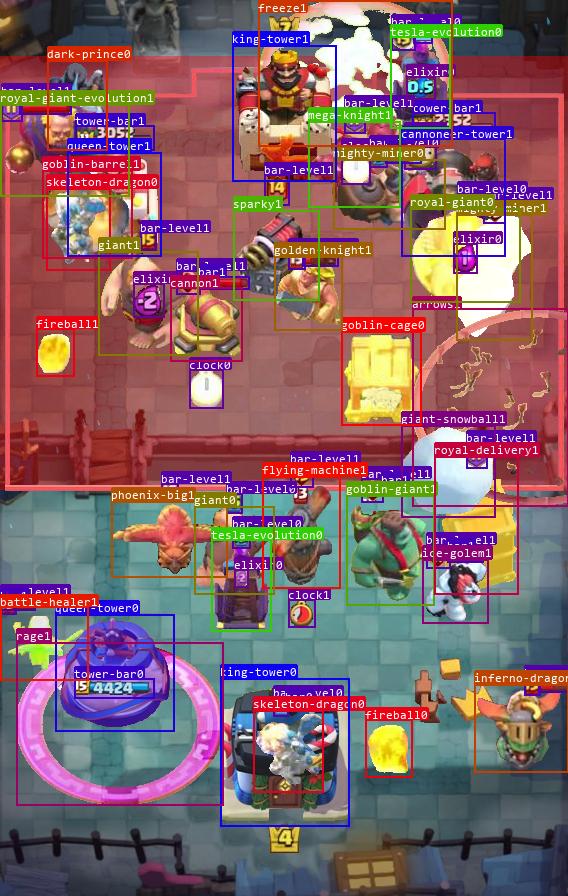
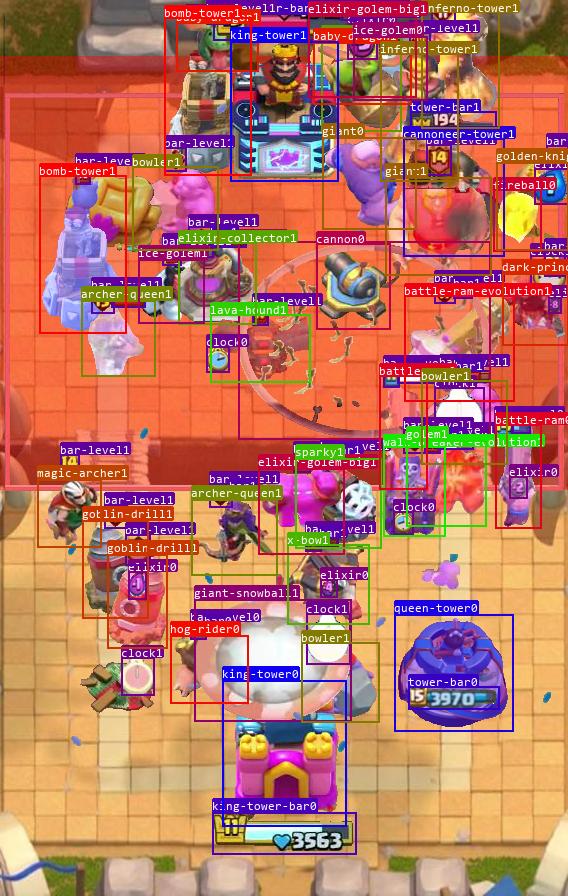
YOLOv8目标识别效果:


模型实时对局效果:

整体架构设计
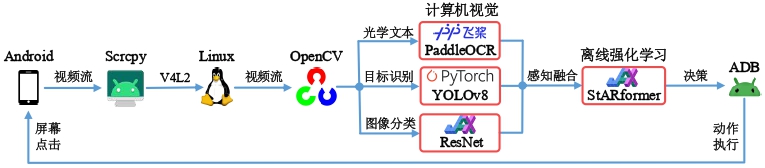
“非嵌入”即直接识别手机中的图像。数据传递的具体流程:手机通过USB连接电脑,通过Scrcpy将视频流传输到Linux内核中的V4L2虚拟设备中(Scrcpy-V4L2),再通过Python中的OpenCV读取成np.ndarray数组形式,将图像的不同部分传入到不同的模型中进行预识别,再通过感知融合模型处理成决策模型输入的特征,传入到决策模型中进行决策。
目标识别数据集构建
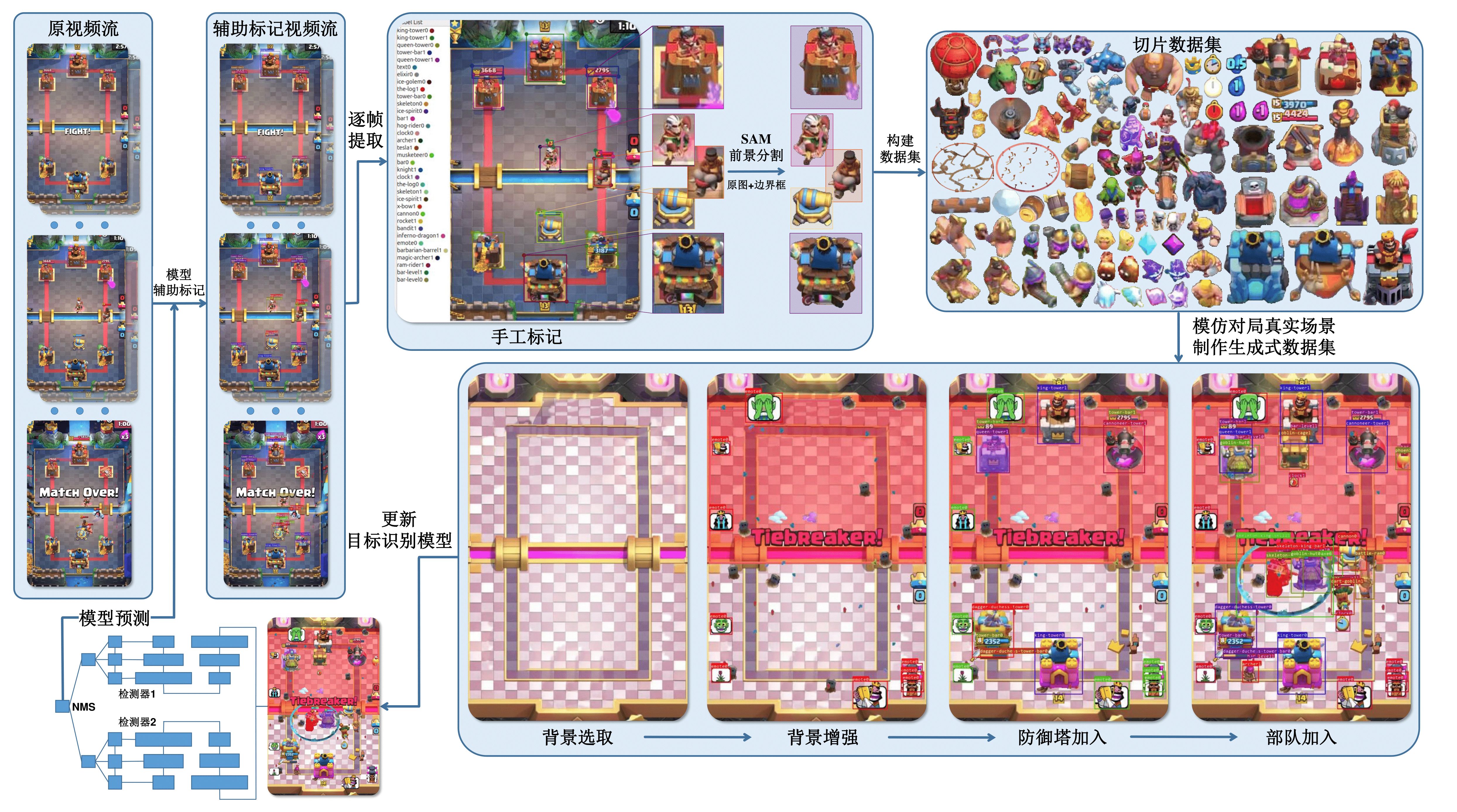
构建目标识别数据集是一个纯体力活,但是可以利用 Segement Anything Model (SAM) 简化我们在制作切片时的工作量,从左上角顺时针开始看:
- 首先我们还是要从原始数据流开始,对其中的待识别目标人工标记(或者可以让已有的识别模型进行辅助标记,然后人工微调),这样就可以得到真实数据流的标记数据,但是数据量非常小,后续将作为模型的验证集。
- 然后我们将原图与边界框传入到SAM中,进行前景分割,将分割的前景在进行人工筛选(其中还需要大量的PS,处理细节问题),将不同类别的切片进行合并,从而得到切片数据集(包含 154 个类别)
- 再通过一个目标识别数据集生成算法,生成用于目标识别模型训练所需的数据集,使用新的数据集训练完新的模型后,用于下一次的辅助标记工作。
生成式数据集算法
这算法是一种基于图层等级进行生成的方法,对不同的切片类别设置不同的图层等级,按照图层等级从低到高顺次绘制到背景板上,绘制代码在 generation.py 中,其全部配置文件在 generation_config.py 中。
| 图层等级 | 切片等级 |
|---|---|
| 0 | 地面法术,地面背景部件 |
| 1 | 地面部队,防御塔 |
| 2 | 空中部队,空中法术 |
| 3 | 其余待识别部件,空中背景部件 |
细节如下:
- 背景选取:从数据集中随机选取一个去除防御塔、部队及文本信息的空竞技场作为背景图片。
- 背景增强:加入背景板中的非目标识别部件,用于数据增强,例如:部队阵亡时的圣水,场景中随机出现的蝴蝶、花朵等。
- 防御塔加入:在双方的三个防御塔固定点位上随机生成完好或被摧毁的防御塔,并随机选取生成与之相关联的生命值信息。
- 部队加入:按照类别出现次数的反比例 所对应的分布进行类别随机选取,其中 表示类别 的切片之前生成的总次数,;在竞技场中按照动态概率分布随机选择生成点位,并随机选取生成与之相关的等级、生命值、圣水、时钟等信息。
完成绘制单位加入后,可以按照插入顺序得到待绘制单位序列 ,但生成的切片可能存在覆盖关系,因此需要引入最大覆盖率阈值 ,当被覆盖单位面积超过该单位切片面积的 倍时,对被覆盖单位进行去除,对单位完成筛选之后,再按照图层等级的从高到低进行绘制,并将识别类别 中的边界框信息进行记录,用于后续识别模型训练。

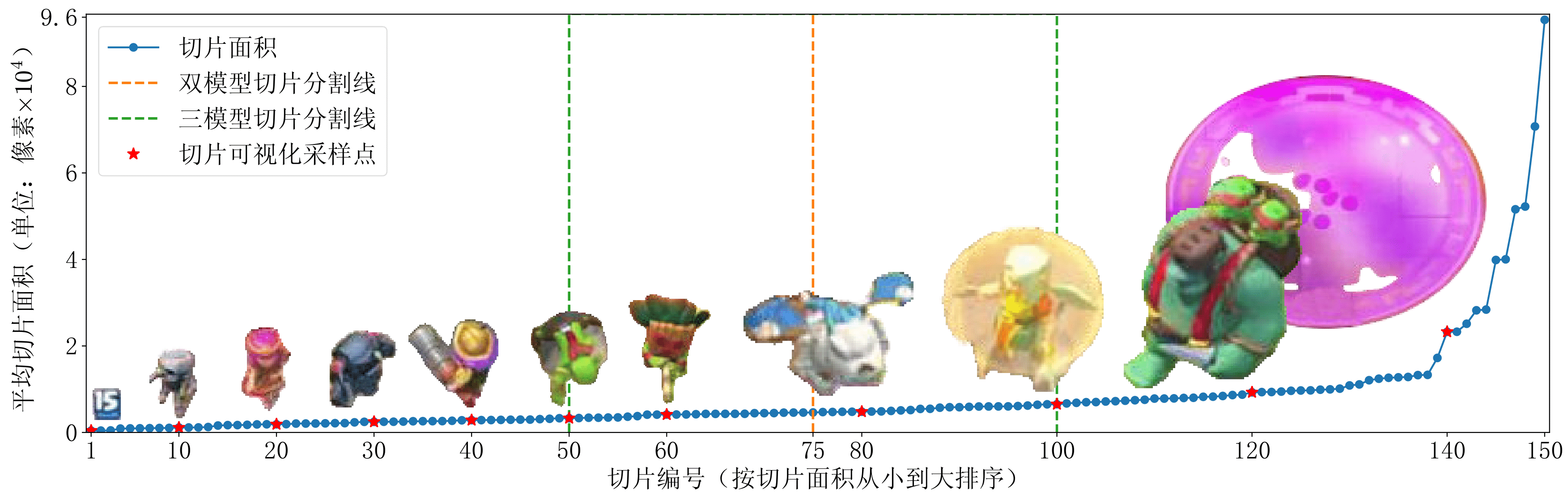
下图是一些生成图像,生成的单位数量均为 ,从左侧为小型切片 ,中间为大型切片 ,右侧为大型切片 ;
生成的单位数量均为 ,从左侧为小型切片 ,中间为大型切片 ,右侧为大型切片 。
数据集分析
- 生成式数据集切片:总计 154 个类别,待识别类别 150 个,总共包含 4654 个切片,在全部待识别类别的切片图像中,切片大小分布如下图所示。
- 目标识别验证集:总计 6939 张人工标记的目标识别图像,包含 116878 个目标框,平均每张图片包含 17 个目标框,该数据集均为真实对局视频流逐帧标记得到,而模型训练所使用的完全是生成式数据集,所以该数据集可以做验证集使用。
YOLO目标识别模型训练
目标识别模型使用了自己实现的 YOLOv5 和重构后的 YOLOv8 ,每个训练集大小设置为 20000,至多训练 80 个 epoch 收敛。数据增强使用了:HSV 增强,图像旋转,横纵向随机平移,图像缩放,图像左右反转,具体参数见下表。
| 数据增强类型 | 参数变换范围 | 单位 |
|---|---|---|
| HSV 增强 | 比例系数 | |
| 图像旋转 | 度 | |
| 横纵向随机平移 | 比例系数 | |
| 图像缩放 | 比例系数 | |
| 图像左右反转 | 概率大小 |
实验结果如表 4-1 所示,表中具体内容解释如下:
- 模型名称:编号后的字母表示模型大小,l,x 分别对应大与特大型模型,YOLOv8-l 表示使用 n 个 YOLOv8-l 模型,每个子模型分别识别上图中分割线所划分区域中的切片类型,最后将识别的预测框通过 NMS 进行筛选,NMS 过程中 IOU 阈值设定为 0.6。
- 验证速度:模型预测时 Batch 大小设置为 1,FPS 为模型在 GeForce RTX 4090 下测试的验证速度,验证测试时置信度设置为 0.001。当对视频流数据进行预测时,将置信度改为 0.1,并使用 ByteTrack 算法在目标追踪计算过程中对边界框进行筛选,FPS(T) 是在 GeForce RTX 4060 Laptop 下带有目标追踪的识别速度。
综合,识别带目标追踪的识别速度 FPS(T) 和小目标的识别准确率 mAP(S),我们最终选定使用模型 YOLOv8-l 作为最终目标识别模型。
图像感知特征提取
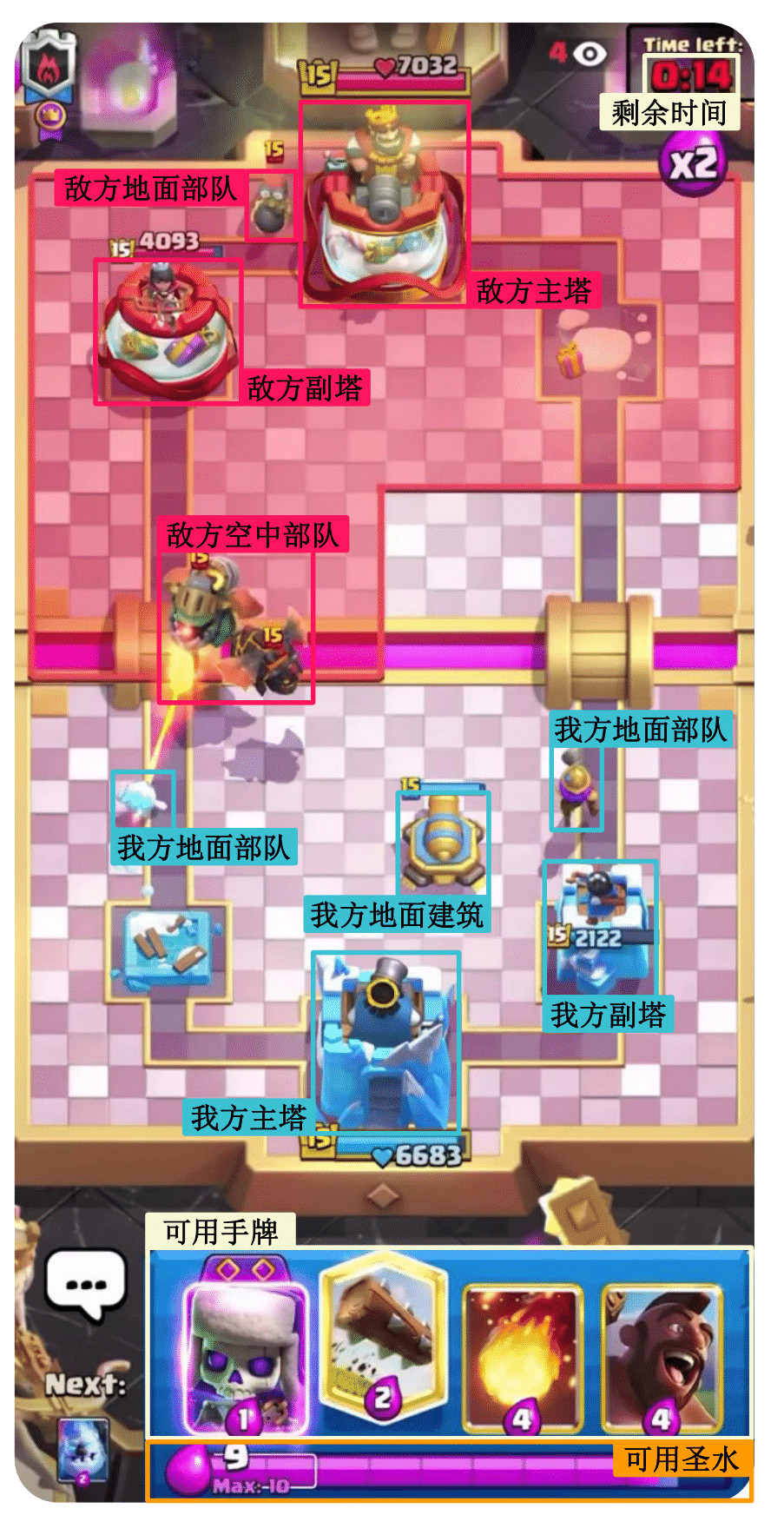
在感知特征提取中,将同时用到三种模型(PaddleOCR, YOLOv8, ResNet)作为一阶段图像特征提取,分别可以得到当前时刻下三个预处理信息:剩余时间(OCR) 、竞技场中的预测框(YOLO) 、当前手牌及总圣水(图像分类器) 。下面将介绍特征提取器的设计方法,可以将预处理信息进一步转化为决策模型的输入信息,它们分别为环境状态信息提取(State)、执行动作信息提取(Action)和环境奖励信息提取(Reward)。
状态特征
状态特征包含以下四个信息:
- 通过的总时长 ,直接通过右上角进行OCR识别得到;
- 竞技场部队信息 ,通过YOLOv8模型识别中间部队,并结合下文中的关联性推理方法得到部队的状态信息(包括:类别,位置,从属派别,血条图像);
- 手牌信息 ,一个四维向量,每一维度表示当前手牌中的卡牌类别(需要注意当一张卡牌被拖出但没有被释放时,对应的卡槽仍然保持非空);
- 圣水信息 ,直接通过识别下面的数字可以得到。
状态特征提取中使用到了下述两个细节,实现方法都是对特征融合模型中加一个记忆buffer即可。
关联性推理
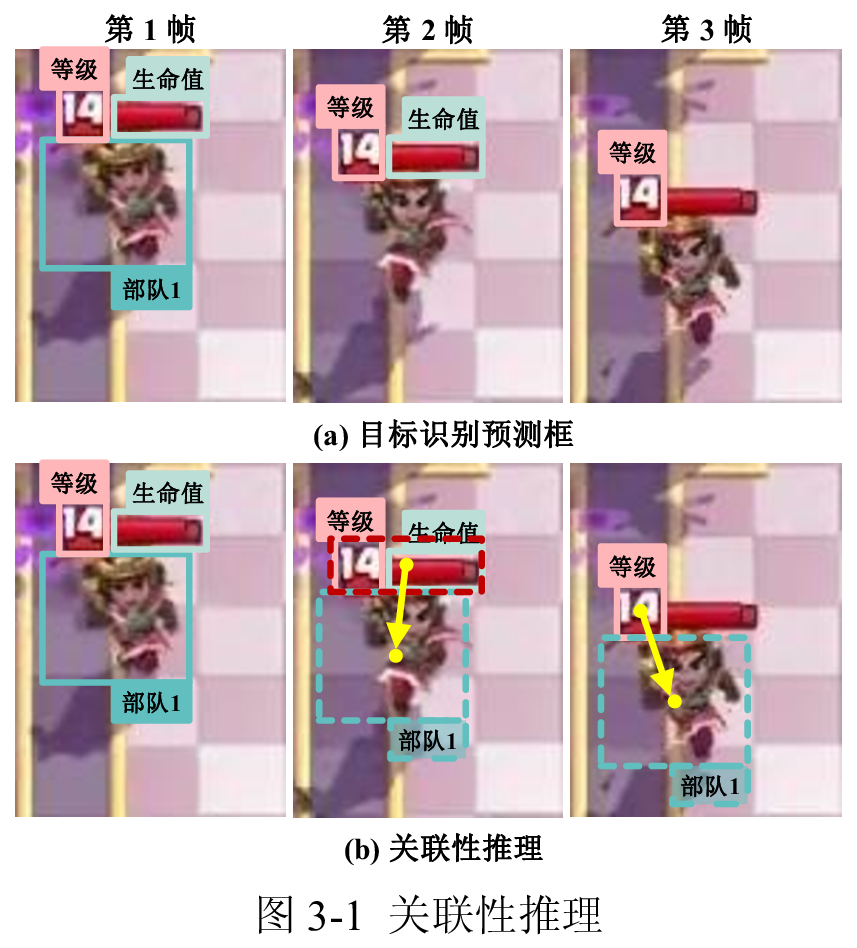
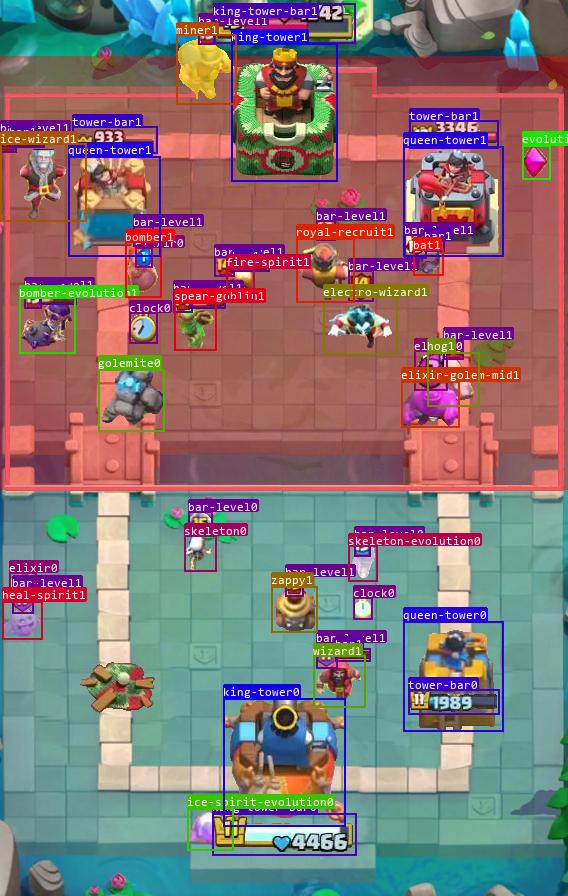
由于等级信息和血条信息相对部队边界框更容易识别,并且每个部队都存在一个与之唯一对应的等级和生命值信息,且部队与等级或生命值信息的相对位置基本不变,所以即使部队识别框出现:消失、类别识别错误、派别识别错误时,利用之前与之关联的等级和生命值信息中进行修正,效果如上图。
当模型在第 1 帧关联了部队 1 与等级、生命值信息的对应关系,通过目标追踪及上下帧信息记忆,即使在第 2, 3 帧未能目标识别模型未能检测到部队 1,通过等级或生命值的关联性推理,模型同样可以推理得到当前单位的真实位置。
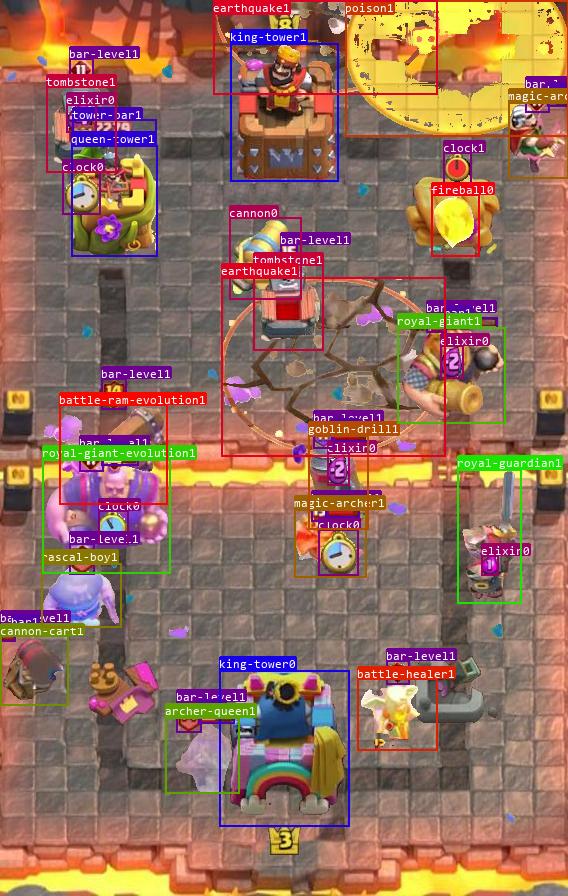
错误动作先验信息

在执行动作之前,状态特征中应不包含任何直接与该动作相关的先验信息,否则模仿学习依赖该先验信息直接给出动作预测,而真实交互环境中由于不再出现这类动作的先验信息(例如一个放置该牌的虚影,或者提前的圣水数字变换),所以导致模型无法做出决策,错误状态信息上图所示。
第一个虚影的处理方法比较简单,由于放置牌时才会产生虚影,此时虚影的上方一定有该单位的名称,所以我们可以通过识别名称与部队的类别是否相同来删去该虚影;第二个错误原因在于动作帧的识别必须依赖于YOLO模型对圣水动画的识别,由于识别模型相对有一定的滞后,因此我们需要按照OCR给出的圣水变换时刻,将动作前移到该时刻下。
动作特征
动作特征包含以下两个信息:
- 当前执行动作的二维坐标 ;
- 当前执行动作所使用的卡牌编号 。
这里需要注意上文中 错误动作先验信息 的YOLO模型动作识别滞后的问题,需要将第 3 帧识别到的动作前移到第 2 帧(圣水数字发生突变)上。
奖励特征
奖励函数设计如下:
奖励特征仅包含奖励 一种信息,通过OCR识别可以得到敌我防御塔具体生命值,设 为防御塔生命值,当 时表示左右两个副塔生命值, 表示主塔生命值, 分别表示我方和敌方建筑, 表示前一帧与当前帧生命值的差值, 表示对应防御塔的总生命值,分别定义如下四种奖励函数:
- 防御塔生命值奖励
-
防御塔摧毁奖励 :当敌我副塔被摧毁时给予 奖励,敌我主塔被摧毁时给予前者的 倍奖励。
-
主塔激活奖励 :当副塔均存活的条件下,主塔第一次失去生命值时,给予 奖励。
-
圣水溢出惩罚 :当总圣水持续保持溢出状态时,每间隔 秒产生一次 的惩罚。
综合上述奖励,得到总奖励:
决策模型
状态空间
模型的状态输入由 2 部分构成,分别为
- 为单位的网格状特征输入,对于第 行 列的特征 表示处于该位置的单位具有如下 种特征: 为类别编码, 为从属派别编码, 为生命值图像编码, 为其余条状图像编码;
- 表示当前状态下的两个全局特征: 为当前手牌信息, 为当前总圣水量。
模型的动作输入由2个部分构成,分别为
- 表示动作执行的部署坐标;
- 表示动作执行的手牌编号。
预测目标设计与重采样
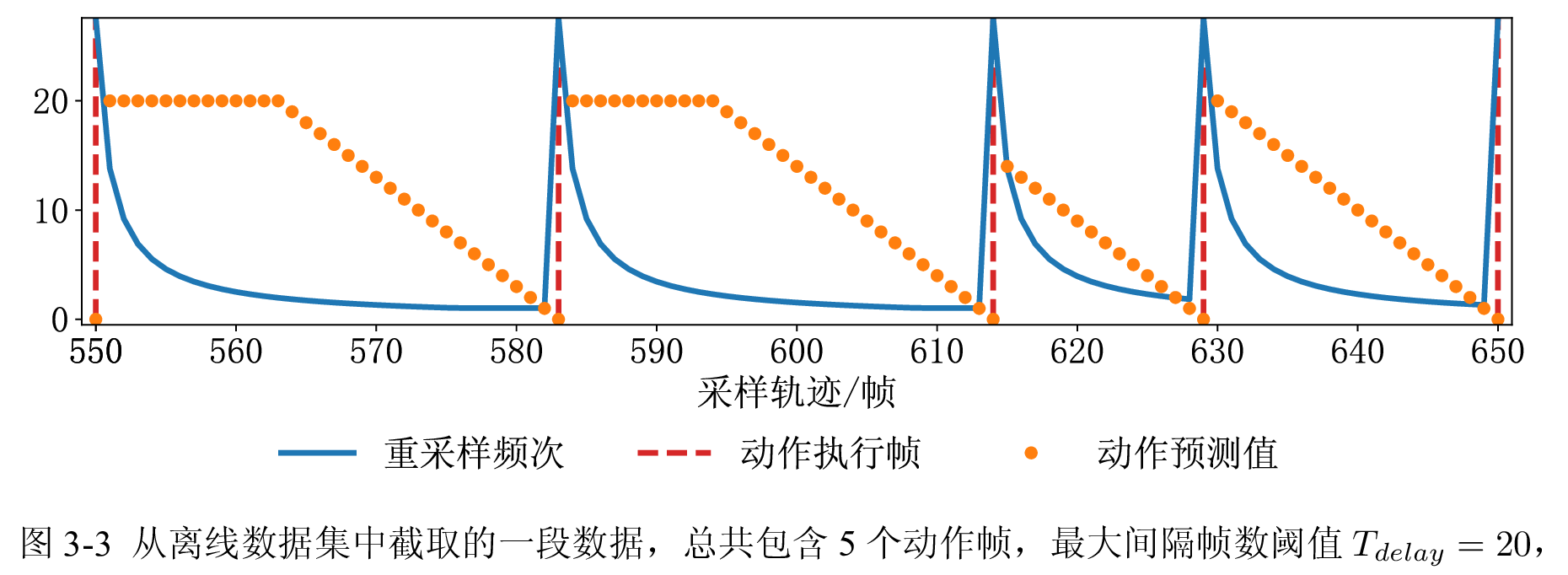
由于离线数据集中的动作执行极为离散,总帧数中仅有 为执行动作帧,其余帧均不执行动作,如果直接逐帧预测动作会产生非常严重的长尾问题,导致模型最终基本不执行动作,因此需要将预测目标从离散转化为连续,解决方法是引入延迟动作预测:对于第 帧,需找到其后(包含自身)最近的动作帧 ,令最大间隔帧数阈值为 ,则每个非动作帧的预测的延迟动作为 。
对离线数据集进行采样时,为避免长尾问题导致模型偏移,本文还设置了重采样频次,设数据集总帧数为 ,动作帧数为 ,则动作帧占比为 ,对于第 个动作帧位于数据集中的第 帧,则 帧作对应的重采样频次为
则训练轨迹中结束帧的采样分布为 ,下图中展示了离线数据集一段轨迹所对应的重采样频次与动作预测值。
决策模型设计
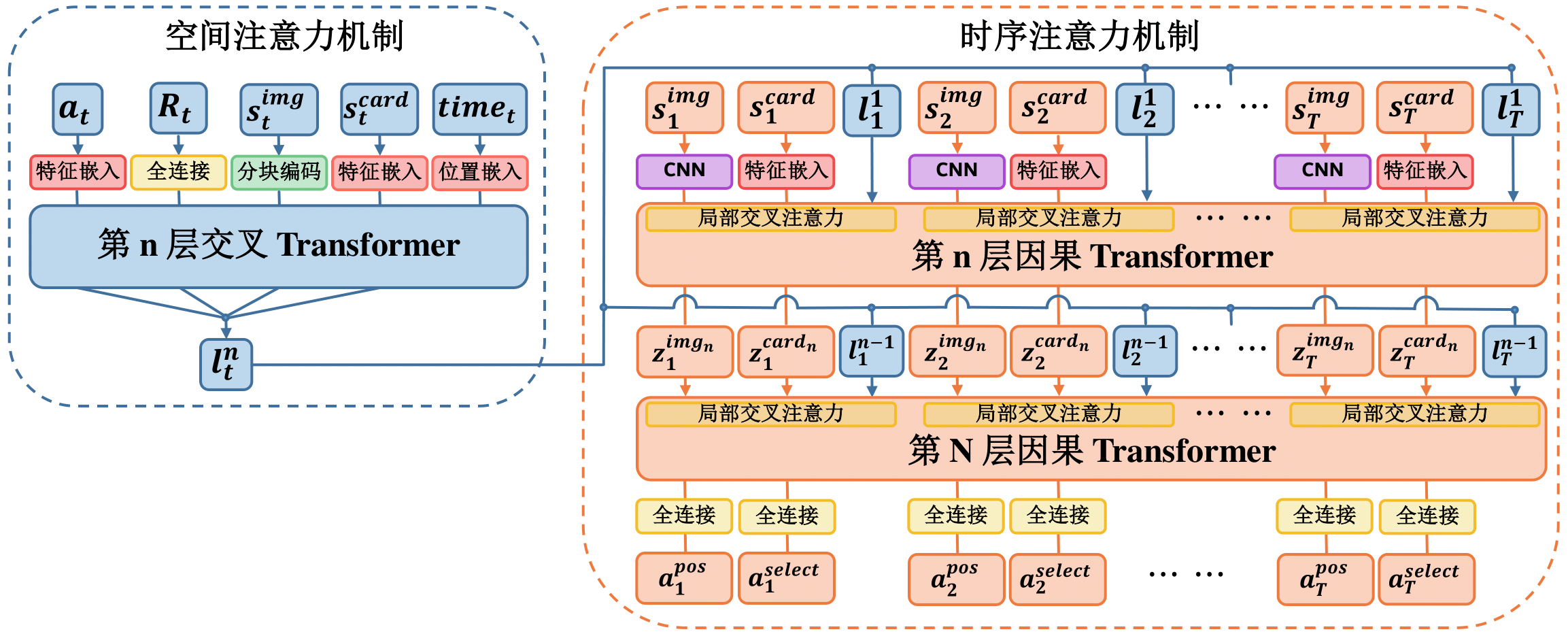
我们使用的是基于 StARformer 的模型架构,StARformer 是一种对 DT 算法在图像状态输入上进行优化的模型,本质上就是使用了 ViT 的将图像转化为序列的方式,传入到左侧的空间 Cross-Attention Transformer 中,对空间特征处理后再传入到时序 Causal-Attention Transformer 中对动作进行预测。(DT 仅包含 时序 Transformer 部分)
对 Cross-Attention 和 Causal-Attention 的介绍请见 用JAX复现基于Transformer的miniGPT模型 - Attention机制。
在实现细节上需要注意在同一时刻下相邻的 token 是可以相互产生 Attention 的(通过修改注意力矩阵即可)。
模型训练
我们将损失函数定义如下
其中 分别为最大间隔帧数阈值、目标动作的部署坐标、手牌编号以及部署延迟,注意每条轨迹下只考虑 对应的梯度。
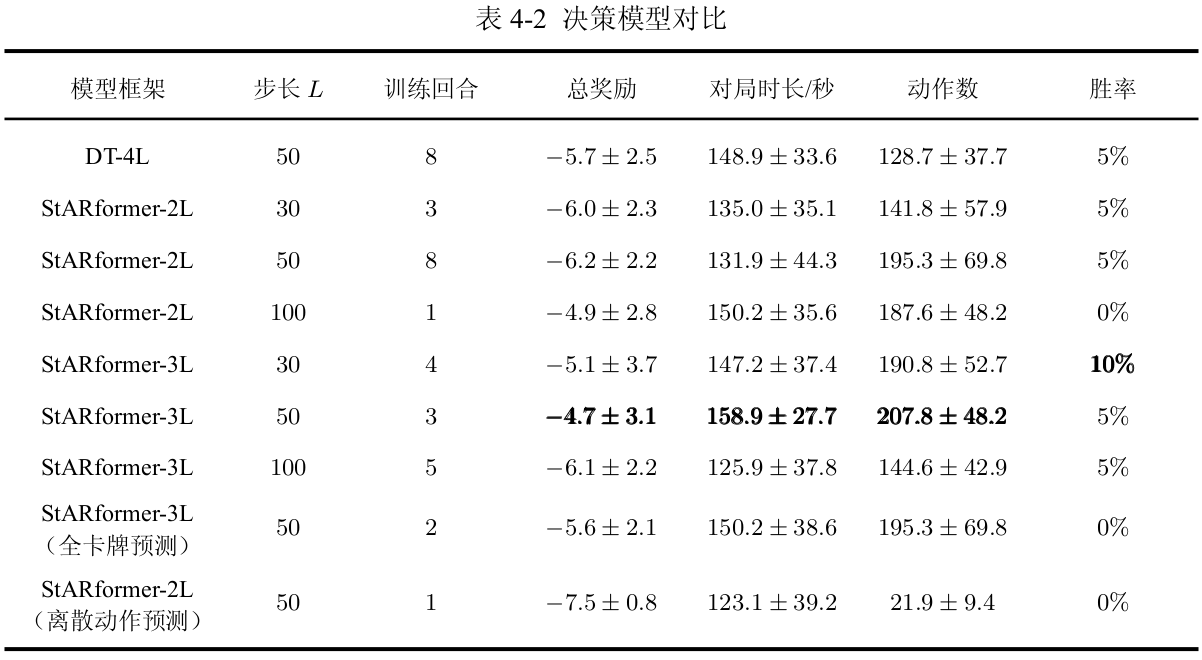
上表中记录了为每个模型的前 10 次训练结果中,与环境交互 20 个回合得到的最高平均奖励,从中可以看出,将离散预测改为连续预测提高了 37% 的性能、StARformer架构从 2L 修改为 3L 的改动提高了 24% 的模型性能。表中每列的含义分别为:
- 步长 :为决策模型架构设计中的输入轨迹长度。
- 训练回合:前 个训练结果中,获得最高奖励所对应的回合数。
- 总奖励:按奖励公式进行累计得到的总奖励。
- 对局时长:统计每次对局的时长。
- 动作数:统计每局智能体成功执行的动作数目。
我使用的验证环境:手机系统为鸿蒙、电脑系统为 Ubuntu24.04 LTS、CPU: R9 7940H、GPU: RTX GeForce 4060 Laptop,平均决策用时 120ms,图像感知融合用时 240ms。
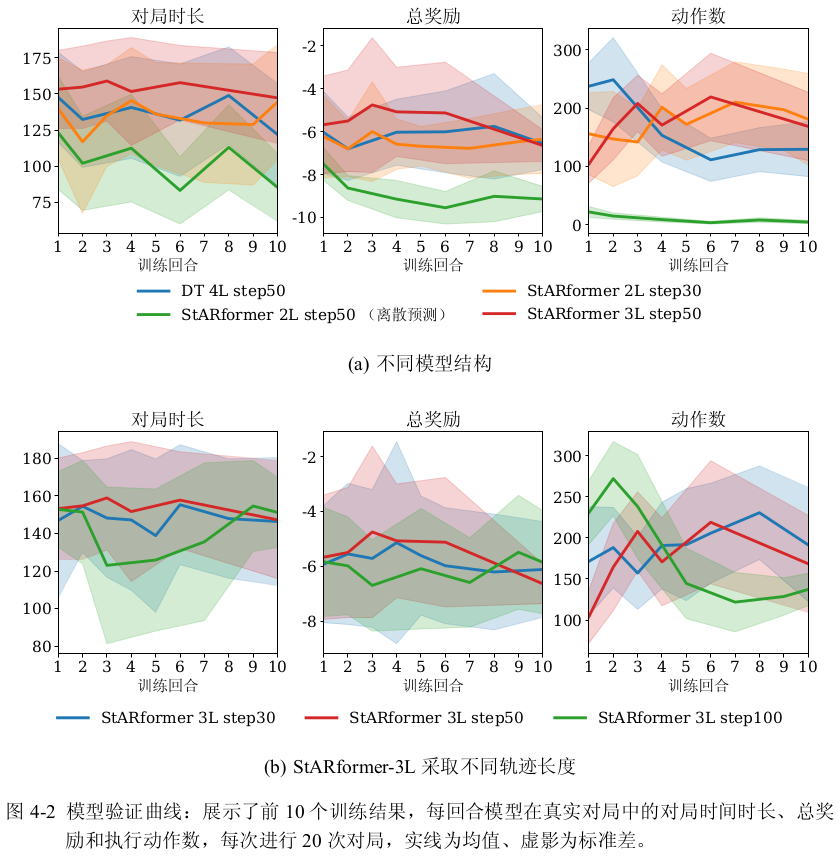
下图展示了部分模型前 个训练结果的验证曲线。
后续工作
本毕设的智能体能力远没有达到开题中所述的人类平均水平,与内置 AI 对局胜率也仅有 5% 不到,其问题主要出在离线强化学习中。
在经典 Atari 游戏中,离线强化学习中最强的 StARformer 能力也无法达到在线算法 DQN 或 PPO 的 20%,而且具有极大的方差,由于无法与环境进行直接交互,离线强化学习与在线算法相比,探索的状态数减小了 1000 倍左右。即使本毕设使用 10 万帧数据进行训练(8小时对局数据),仍有大量的未知场景,因此模型无法给出最优的决策。
由于最后决策模型设计仅剩 2 周,为验证智能体在非嵌入条件下的可行性,本毕设保守地选择了离线强化学习作为决策模型。
后续改进:重新设计决策模型,在 Windows 上运行 Android 模拟器 + 感知融合算法,与 Linux 通过 TCP/UDP 通讯传输融合特征,最后使用 LSTM 架构 + PPO 算法训练在线模型。